学Python数据科学,玩游戏、学日语、搞编程一条龙。
整套学习自学教程中应用的数据都是《三國志》、《真·三國無雙》系列游戏中的内容。
Pandas 是用于分析、数据处理和数据科学的基础库。 一些较少使用但惯用的 Pandas 功能,这些功能可以使代码具有更好的可读性、多功能性和速度。

文章目录
解释器启动时配置选项和设置
解释器启动时设置自定义的 Pandas 选项,使用启动文件 pd.set_option() 来配置想要的内容。
import pandas as pd
def start():
options = {
'display': {
'max_columns': None,
'max_colwidth': 25,
'expand_frame_repr': False, # 不要换行到多个页面
'max_rows': 5, # 数据截断行数
'max_seq_items': 0, # 打印序列的最大长度
'precision': 4, # 精度
'show_dimensions': False
},
'mode': {
'chained_assignment': None # 控制 SettingWithCopyWarning
}
}
for category, option in options.items():
for op, value in option.items():
pd.set_option(f'{
category}.{
op}', value) # Python 3.6+
查看 pandas 设置。
start()
pd.get_option('display.max_rows')
5
使用数据打印一下结果,自动截断设置的行数。
import pandas as pd
df = pd.read_excel('Romance of the Three Kingdoms 13/人物列表(含DLC).xlsx')
df

Test模块
在 Pandas 的测试模块中隐藏着一些方便的功能,用于快速构建准现实的 Series 和 DataFrame。
import pandas.util.testing as tm
tm.N, tm.K = 15, 3 # 默认行/列
import numpy as np
np.random.seed(444)
tm.makeTimeDataFrame(freq='M').head()
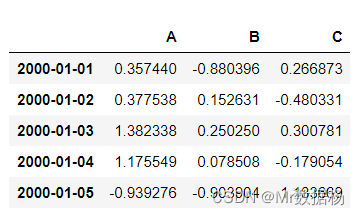
tm.makeDataFrame().head()
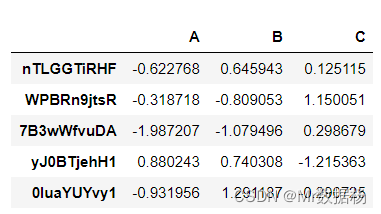
查询所有功能可以使用 dir 方法,通过方法名称就能知道每个模块大致的作用。
[i for i in dir(tm) if i.startswith('make')]
['makeBoolIndex',
'makeCategoricalIndex',
'makeCustomDataframe',
'makeCustomIndex',
'makeDataFrame',
'makeDateIndex',
'makeFloatIndex',
'makeFloatSeries',
'makeIntIndex',
'makeIntervalIndex',
'makeMissingCustomDataframe',
'makeMissingDataframe',
'makeMixedDataFrame',
'makeMultiIndex',
'makeObjectSeries',
'makePeriodFrame',
'makePeriodIndex',
'makePeriodSeries',
'makeRangeIndex',
'makeStringIndex',
'makeStringSeries',
'makeTimeDataFrame',
'makeTimeSeries',
'makeTimedeltaIndex',
'makeUIntIndex',
'makeUnicodeIndex']
Pandas访问器
可以将 Pandas 访问器视为一个属性,用作附加方法的接口。
有3个基本的数据处理标准格式:
- .str 映射到 StringMethods
- .dt 映射到 CombinedDatetimelikeProperties
- .cat 路线到 CategoricalAccessor
pd.Series._accessors
{
'cat', 'dt', 'sparse', 'str'}
StringMethods,直接使用字符串方法处理。
data = pd.Series([
'A, a-001',
'B, b-001',
'C, c-001',
'D, d-001'
])
data.str.upper()
0 A, A-001
1 B, B-001
2 C, C-001
3 D, D-001
dtype: object
CombinedDatetimelikeProperties,直接按照时间数据进行处理。
daterng = pd.Series(pd.date_range('2022', periods=5, freq='Q'))
daterng
0 2022-03-31
1 2022-06-30
2 2022-09-30
3 2022-12-31
4 2023-03-31
dtype: datetime64[ns]
daterng.dt.day_name()
0 Thursday
1 Thursday
2 Friday
3 Saturday
4 Friday
dtype: object
CategoricalAccessor,用于分类数据。在后面的apply中会有详细的说明。
从组件列创建 DatetimeIndex
类似日期时间的数据如上面的 daterng 所示,可以从多个组件列创建一个 Pandas DatetimeIndex,这些列共同形成一个日期或日期时间。
from itertools import product
datecols = ['year', 'month', 'day']
df = pd.DataFrame(list(product([2021, 2022], [1, 2], [1, 2])),columns=datecols)
df['data'] = np.random.randn(len(df))
df
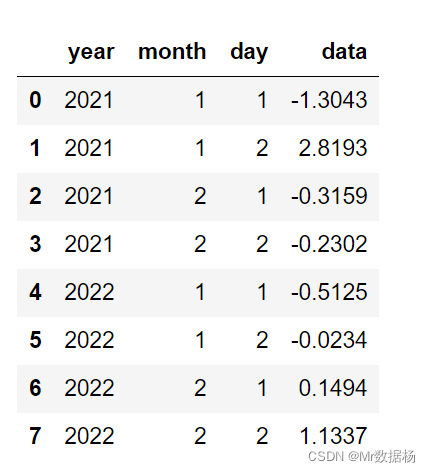
df.index = pd.to_datetime(df[datecols])
df.head()
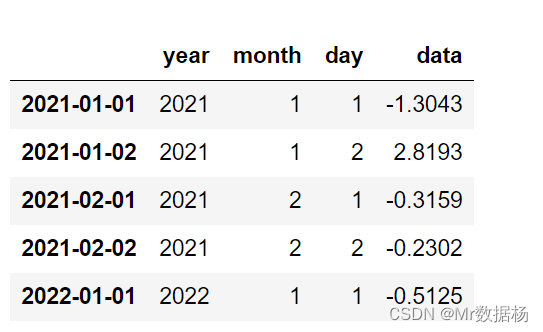
CategoricalAccessor 分类数据
这里应用总的来说就是为了节省空间和时间。
颜色数据是 str 字符串类型,如果转换成数字的话很直观的就能看到空间节省了。
colors = pd.Series([
'periwinkle',
'mint green',
'burnt orange',
'periwinkle',
'burnt orange',
'rose',
'rose',
'mint green',
'rose',
'navy'
])
import sys
colors.apply(sys.getsizeof)
0 59
1 59
2 61
3 59
4 61
5 53
6 53
7 59
8 53
9 53
dtype: int64
也可以使用map字典映射的方法进行处理。
mapper = {
v: k for k, v in enumerate(colors.unique())}
mapper
{
'periwinkle': 0, 'mint green': 1, 'burnt orange': 2, 'rose': 3, 'navy': 4}
as_int = colors.map(mapper)
as_int
0 0
1 1
2 2
3 0
4 2
5 3
6 3
7 1
8 3
9 4
dtype: int64
as_int.apply(sys.getsizeof)
0 24
1 28
2 28
3 24
4 28
5 28
6 28
7 28
8 28
9 28
dtype: int64
自迭代 Groupby 对象
Groupby 用于数据的聚合。针对DataFrame主要用途有:
- 根据给定的条件将数据拆分成组。
- 每个组都可单独应用函数(如sum、mean、std等)。
- 将结果合并到一个数据结果中。
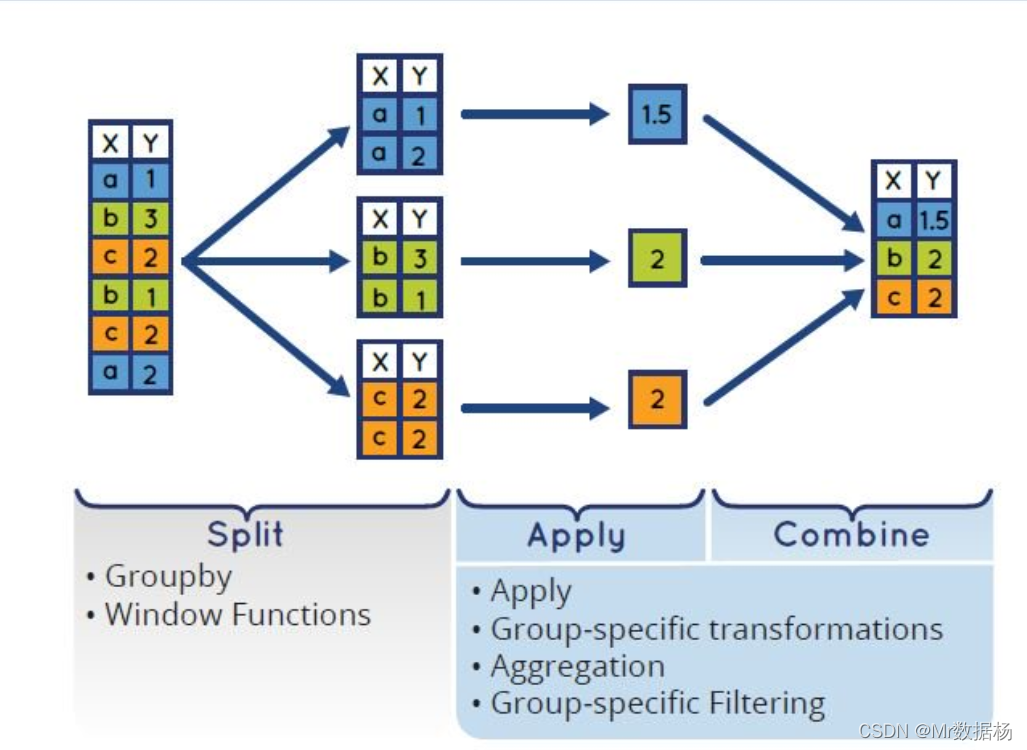
聚合后本身没有实际的意义,需要添加各种条件汇总结果。
grouped = df.groupby('伝授特技')
grouped
<pandas.core.groupby.generic.DataFrameGroupBy object at 0x000001F6FC3EC9E8>
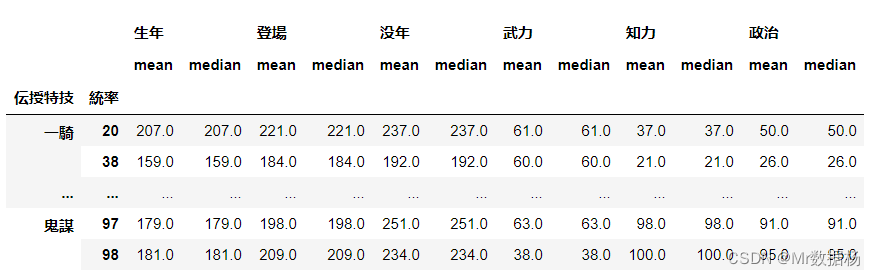
根据固定的条件汇总。
df.groupby(['伝授特技', '統率']).agg(['mean', 'median'])
Pandas 使用布尔运算符
数据列使用bool进行判断。

df["性別"] == "男"
0 True
1 True
...
855 True
856 False
Name: 性別, dtype: bool
对应的可以对判断为真的数据进行提取,对应数据中性别为男性 M的行。
df[df["性別"] != "男"]
或者使用 ~ 号进行取反操作。
df[~(df["性別"] == "男")]
从剪贴板加载数据
这个听起来很神奇,但是实际是可以的。
例如 Excel 中的数据是这样的。
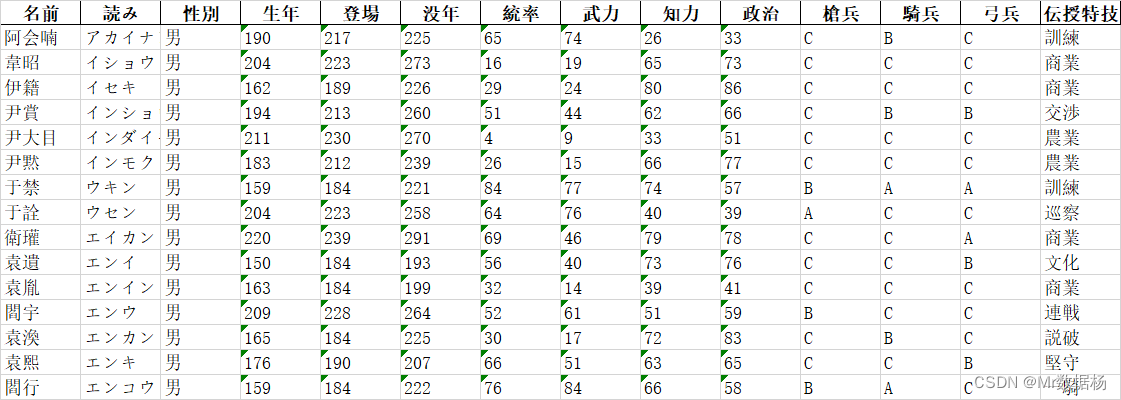
直接复制,然后进行代码操作。
df = pd.read_clipboard(na_values=[None])
df
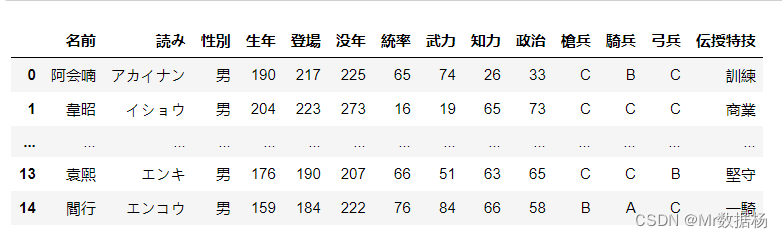
Pandas 对象直接写入压缩格式
将 Pandas 对象直接写入 gzip、bz2、zip 或 xz 压缩,而不是将未压缩的文件存储在内存中并进行转换。
df.to_json('df.json.gz', orient='records',lines=True, compression='gzip')
保存后的数据大小差异 9.9 倍。
import os.path
df.to_json('df.json', orient='records', lines=True)
os.path.getsize('df.json') / os.path.getsize('df.json.gz')
6.22547770700637