数据可视化是数据分析中非常重要的一环,掌握了可视化技巧,可以让我们在数据分析过程中,发现更多的细节,数据之间透露的逻辑关系,也可以让我们的数据分析报告更加生动,有说服力,因此掌握数据可视化,可以说是数据分析工程师必备的技能。
【思考】最基本的可视化图案有哪些?分别适用于那些场景?(比如折线图适合可视化某个属性值随时间变化的走势)
- line plot, 折线图适合可视化某个属性值随时间变化的走势
- bar plot, 水平柱状图或垂直柱状图,参数stacked=True,可以设置叠状柱形图,是最常见的可视化表示方法,非常适合用于对比大小、直观
- pie plot, 饼图,明确显示数据的比例情况,尤其适合渠道来源分析等场景
- box plot, 箱盒图,便于发现数据异常值
- scatter plot, 散点图,针对离散数据,用于判断两个变量之间的联系
- contour plot,等高线图,
- histogram plot, 直方图是一种对数值频率进行离散化显示的条形图。数据点被分割成离散的,均匀间隔的箱子,并绘制每个箱子中的数据点的数量。用来查看数据的分布特征。
参考:
# 加载所需的库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# 加载result.csv这个数据
df = pd.read_csv('result.csv')
del df['Unnamed: 0']
df.head()

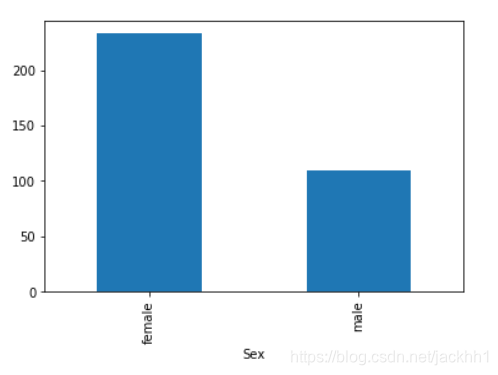
一、 任务一:可视化展示泰坦尼克号数据集中男女中生存人数分布情况(用柱状图试试)
df1 = df['Survived'].groupby(df['Sex']).sum()
df1.plot.bar()
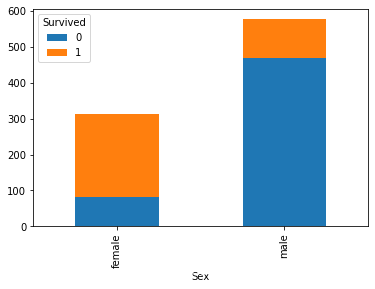
二、任务二 可视化展示泰坦尼克号数据集中男女中生存人与死亡人数的比例图
df1 = df.groupby(['Sex', 'Survived'])['Survived'].count().unstack()
df1.head()
df1.plot.bar(stacked=True)
[思考]:为什么要unstack?
df1 = df.groupby(['Sex', 'Survived'])['Survived'].count()
df1.head()
Sex Survived
female 0 81
1 233
male 0 468
1 109
Name: Survived, dtype: int64
df1有两层行索引,需要用unstack函数将某一行索引变成列索引,相反,stack函数是将列索引变成行索引
【参考】:
pd.DataFrame.unstack
https://zhuanlan.zhihu.com/p/163670638

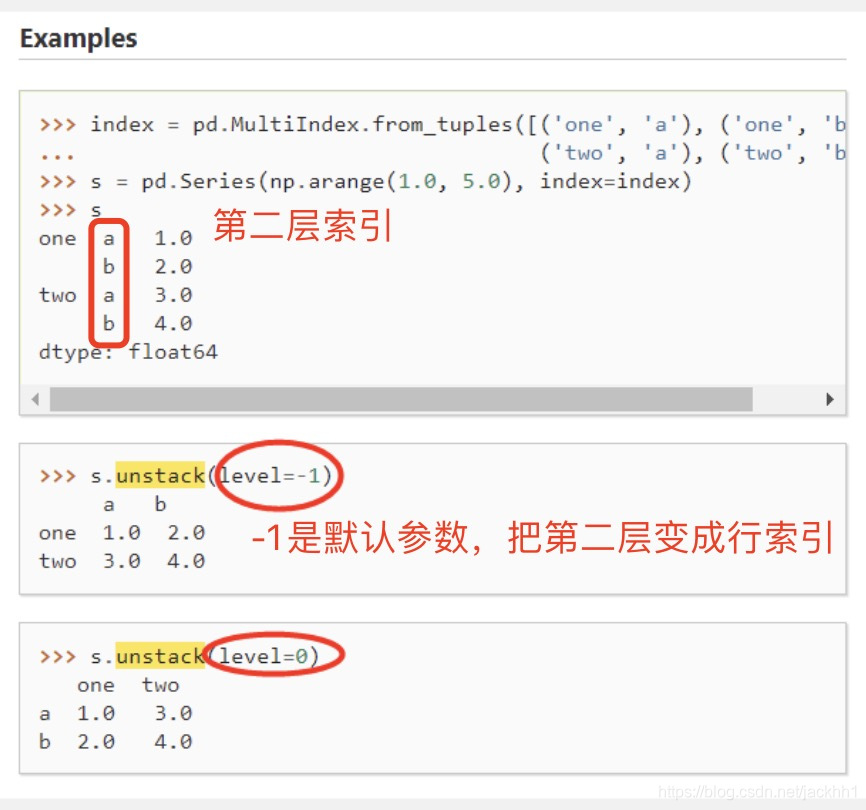
这里还要复习下DataFrame的结构,一个DataFrame是有值,行索引,列索引组成,下图中DataFrame的值是一个2*3的矩阵,行索引是’Ohio’, ‘Colorado’,行索引名称是‘state’;列索引是’one’, ‘two’, ‘three’,列索引名称是‘number’

三、任务三 可视化展示泰坦尼克号数据集中不同票价的人生存和死亡人数分布情况。(用折线图试试)(横轴是不同票价,纵轴是存活人数)
df2 = df.groupby(['Fare', 'Survived'])['Survived'].count().unstack()
# df2.plot.bar(stacked=True)
fig = plt.figure(figsize=(100,100))
df2.plot.line(grid=True)
plt.show()
# fig = plt.figure(figsize=(50,50))

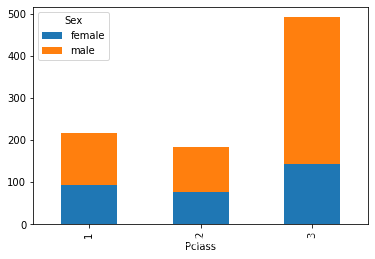
四、 任务四 可视化展示泰坦尼克号数据集中不同仓位等级的人生存和死亡人员的分布情况。
df3 = df.groupby(['Pclass', 'Survived'])['Survived'].count().unstack()
df3.plot.bar(stacked=True)
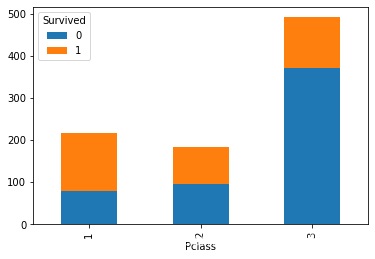
很明显,舱位等级越低,存活率越低,舱位等级越高,存活率越高
五、可视化展示泰坦尼克号数据集中不同年龄的人生存与死亡人数分布情况。
df4 = df.groupby(['Age', 'Survived'])['Survived'].count().unstack()
# df4.plot(kind='pie',subplots=True,stacked=True)
# df4.plot.bar(stacked=True)
df4.plot(kind='area',subplots=False,stacked=True, figsize=(20, 20),fontsize=20)
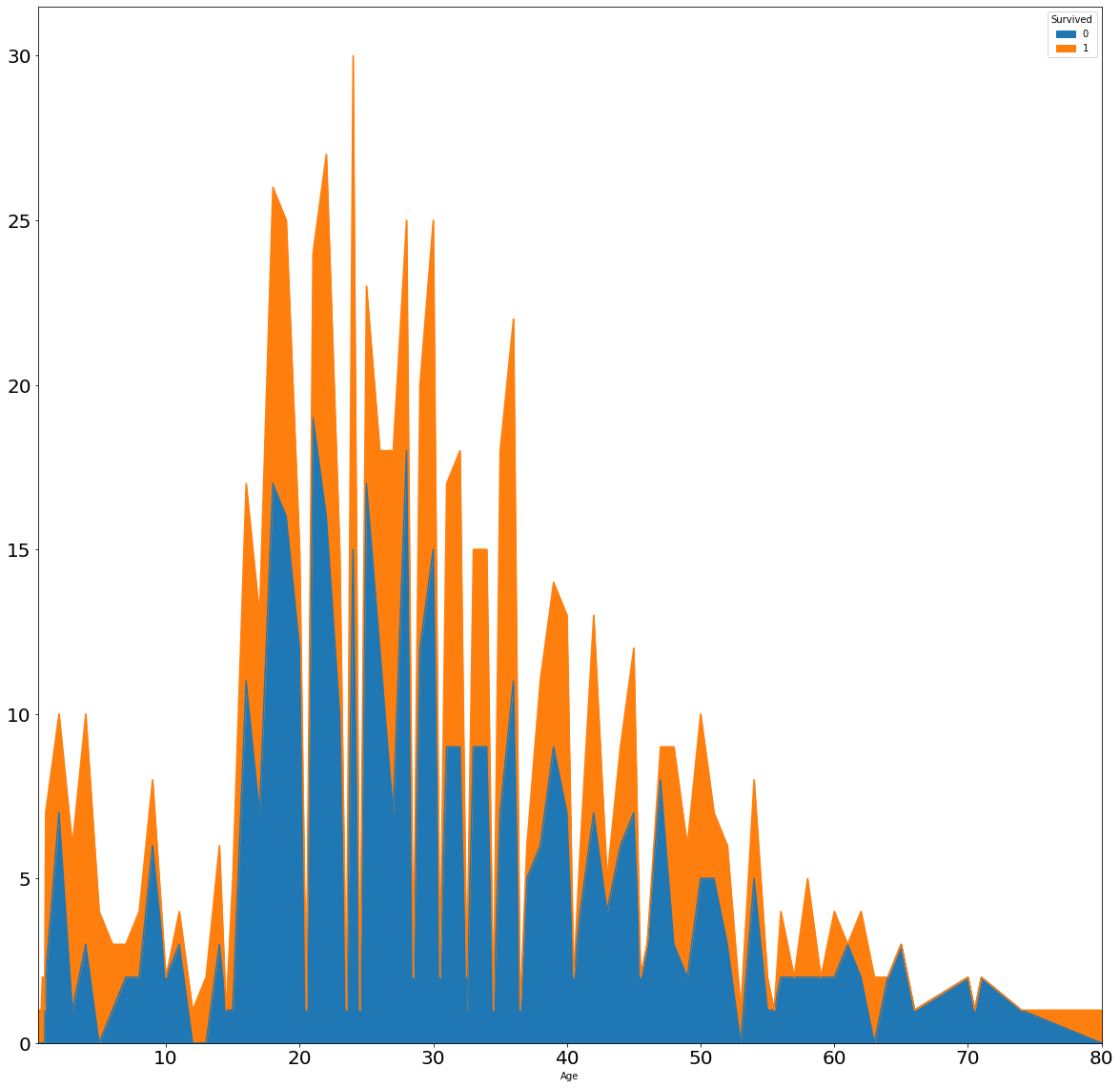
df4 = df.groupby(['Age', 'Survived'])['Survived'].count().unstack()
# df4.plot(kind='pie',subplots=True,stacked=True)
# df4.plot.bar(stacked=True)
# df4.plot(kind='hist',by='Age', bins= 5, subplots=True,stacked=False, figsize=(10, 10),fontsize=10)
df4.plot.hist(by='Age', bins=10, subplots=True,stacked=False, figsize=(10, 10),fontsize=10)
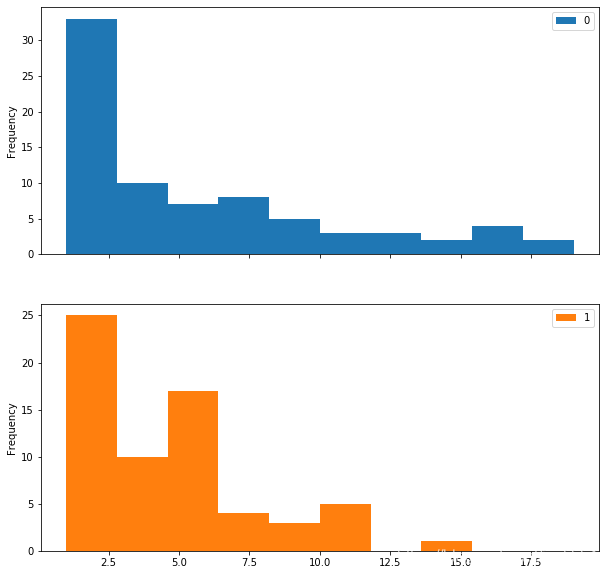
从area图中可以看出,泰坦尼克号小孩中青年存活的存活的数目较多,老年人存活率很低
六、任务六 可视化展示泰坦尼克号数据集中不同仓位等级的人年龄分布情况。
df5 = df.groupby(['Age', 'Pclass'])['Pclass'].count().unstack()
df5.plot(kind='line', stacked=True, figsize=(10, 10), alpha=0.8)

从以上数据图形中可以看出,1等舱的存活率明显高于3等舱,女性的存活率比男性高,头等舱的女性存活率比3等舱的女性存活率高
df6 = df.groupby(['Pclass', 'Sex'])['Sex'].count().unstack()
df6.plot.bar(stacked=True)