Linkage Based Face Clustering via Graph Convolution Network
作者:
发表会议:CVPR2019
作者单位:清华大学、澳大利亚国立大学
github地址:https://github.com/Zhongdao/gcn_clustering/
目的:根据潜在的身份将face分组,将任务看成一个链接预测问题:当两个face具有同样的身份,两个face之间存在一个链接。(仅仅链接预测达不到聚类的效果,还需要进行链接合并)
关键思想是我们在face实例周围的特征空间(将face映射到特征空间中,相似的face会靠近)中找到蕴含丰富信息的local context局部上下文,它包含这个实例和它的邻居之间的丰富信息。通过在每个实例周围构造子图作为输入数据,来描述local context局部上下文,我们利用GCN来推断子图对中链接的可能性。
实验结果表明,与传统的聚类方法相比,我们的方法对复杂的人脸分布具有更强的鲁棒性,在标准人脸聚类基准上取得了与最新方法相当的结果,并且在大数据集上具有可扩展性。此外,我们还证明了该方法不需要以聚类的数量作为先验条件,能够感知噪声和异常值,并且可以扩展到multi-view version多视图版本以获得更准确的聚类精度。
1.Introduction
本文研究了基于人脸特征的聚类问题。没有事先假设人脸表征的分布或聚类身份的数目。人脸聚类的应用有分组、标记桌面或在线相册的照片,组织大规模的人脸图像、视频收集,构建大规模数据集的自动数据清理、标注。
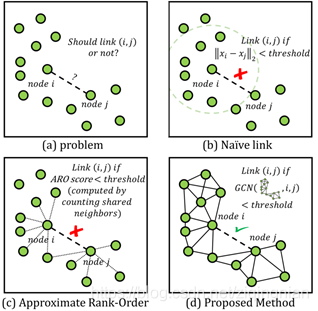
图1所示:(a)本文的目的是估计两个节点是否需要链接。
(b)-(d):三种连接方式的比较,(b):设置L2距离的阈值,直接链接L2距离低于阈值的节点对,不考虑context上下文,效果不好,因为clusters的密度变化比较大,(c): 采用heuristic启发的方法进行基于上下文的链接估计,设计了新的距离表示,如Approximate
Rank-Order Distance (ARO),(c):我们的方法,使用基于上下文的参数模型估计链接的可能性。
传统的聚类方法可能对数据分布做出不切实际的假设,导致人脸表征的复杂分布。例如K-means要求clusters是凸分布,Spectral Clustering需要不同的clusters在实例数目上保持平衡。基于linkage-based链接的聚类方法不用对数据分布做假设可实现更高的准确率。
我们学习预测一个节点和它的邻居链接的可能性,而不是通过启发式的方法(新的距离的表示方法)计算链接的可能性。工作的核心思想是,我们发现一个节点和它邻居之间链接的可能性可以从它的上下文推断。利用节点上下文有价值的信息,我们提出基于GCN的可学习聚类方法。其方法的框架可概括如下:
首先,将聚类表示为一个链接预测问题。当认为两个节点的身份标签相同时,两个节点之间存在一条链接。其次,仅预测实例与其最近邻居之间的联系。
我们围绕每个实例(pivot,中心)构造一个实例中心子图,以描述局部上下文,为每个节点建模一个中心邻居对。从IPS中可以推断出哪一个中心邻居应该被链接,(疑问:构建的中心对是每个节点对应一个节点,但是某一个节点最终可能和多个节点进行了链接)使用GCN来学习这个任务。最后GCN输出一组可能的链接,并通过传递合并链接节点来获得聚类类别。
结果表明,所提出的方法与现有方法相比具有较高的精度,并且在计算复杂度方面具有可扩展性。该方法通过学习自动生成链接似然,其性能优于其他基于链接的方法,如采用启发式规则计算链接似然的ARO方法。此外,我们的方法可以感知噪声和异常值,不需要集群的数量作为输入,并且很容易扩展到多视图版本,以利用来自不同来源的数据。
2. Related Work
Face Clustering.由于姿态、遮挡、光照和实例数目的变化,人脸clusters在大小、形状和密度上有显著的变化,人脸表征具有复杂的分布,使其不适合应用于经典的聚类算法,如K-means和谱聚类,因为这些方法对数据分布有严格的假设要求。
Approximate Rank-Order Distance (ARO)方法为大规模聚类提供了一个有效的框架。ARO的目标是预测一个节点是否应该连接到它的k个最近邻(KNN),并传递合并所有的链接对。因此,ARO的计算复杂度仅为O(kn)。近似最近邻(ANN)搜索算法也可以加速KNN的搜索过程。相应地,总体复杂度是O(nlogn)或O(n2),这取决于我们是将k设为常数还是让它随n增加。ARO比基于AHC的算法更高效。在本研究中,由于所提出的方法是基于KNN的,因此也适用于该框架的开发。
Link Prediction链接预测是社会网络分析中的一个关键问题。给定一个以图形式的复杂网络,其目标是预测两个成员节点之间链接的可能性。为了估计链接的可能性,之前的一些工作,如PageRank和SimRank分析整个图。 Zhang和Chen认为仅从节点对的局部邻居计算链接似然就足够了,并提出了Weisfeiler-Lehman Neural Machine和GCN,从局部子图学习一般的图结构特征。这与我们的工作密切相关,因为聚类任务可以简化为一个链接预测问题,我们也利用图神经网络学习局部图。
Graph convolutional network (GCN),GCNs 可以被分为spectral谱方法和spatial空间方法。我们基于空间方法GCN去解决链接预测问题。
3. Proposed Approach
3.1. Overview
Problem definition.假设我们有一组人脸图像的特征X= ![]()
![]()
![]() ,N是图片的数目,D是特征维度,人脸聚类的目标是分配标签yi
,N是图片的数目,D是特征维度,人脸聚类的目标是分配标签yi ![]() ,因此,具有相同伪标签的实例形成一个cluster。我们遵循基于链接的聚类,预测成对实例之间联系的可能性。集群在所有链接对的实例之间产生。
,因此,具有相同伪标签的实例形成一个cluster。我们遵循基于链接的聚类,预测成对实例之间联系的可能性。集群在所有链接对的实例之间产生。
Motivation. 这项工作背后的动机是,我们发现我们只需要计算一个实例和它的k个最近邻之间的链接可能性,它足以产生良好的聚类结果。在表1中,我们给出了不同k值下聚类性能的上界。为了得到上界,如果每个实例的邻居与其kNN相同,我们直接将每个实例与其kNN连接起来。结果表明,在不同的k值下,上限都很高。这表明预测实例与其kNN之间的联系的潜在有效性,而不是预测所有潜在对之间的联系的潜在有效性。采用这种策略的优点是可以获得较高的聚类精度,同时系统具有高效的优点。

Table 1.基于IJB-B-521dataset的人脸聚类性能与KNN参数的关系,k是每个实例与其k个最近的邻居链接起来得到的,k值上限比较大。
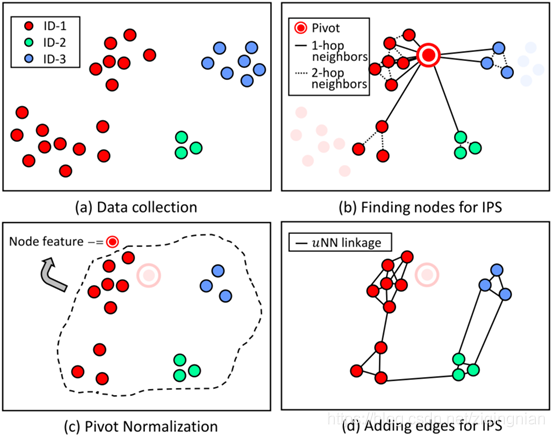
Pipeline. 本研究的重点是人脸聚类系统的效率和准确性。因此,我们采用预测实例与其knn之间的联系的思想。由于预测链接是基于上下文的,为了使预测更准确,我们设计了一个局部结构,称为实例枢轴子图(IPS)。IPS是一个以主实例p为中心的子图。IPS由包含p的knn和p的h-hop的高阶邻居的节点组成。重要的是,我们从所有这些节点中减去枢轴p的特征,使得每个节点特征都编码了枢轴-邻居对之间的链接关系。
(怎样寻找的1-hop、2-hop?)
Figure 2.构造实例中枢子图(IPS)。(a)面部表征的集合。(b) 我们使用每个实例p作为主节点,并找出它的邻居直到h-hop作为IPS的节点。(c) 通过减去主节点的特征,这些节点特征被标准化了。(d) 对于IPS中的节点,我们从整个集合中找到它的uNNs。如果邻居也是一个IPS节点,则在节点和它的uNNs之间添加一条边。在这个图中设置h=2,k1=10,k2=2,u=3,k1为1-hop邻居个数,k2为2-hop邻居个数。需要注意的是,基于主节点p的IPS不包含p。主节点p的IPS用于预测p和IPS中每个节点之间的链接。
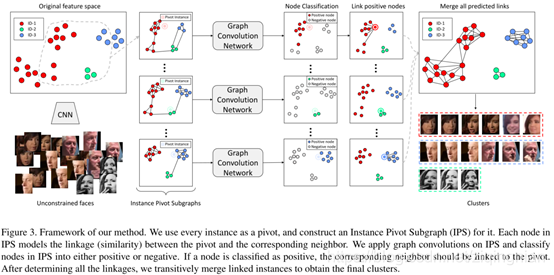
pivot-neighbor pair:中枢邻居对, 图3通过三步给出方法的框架
我们使用每个实例作为中枢轴,并为其构造一个实例中枢子图(IPS)。
给定一个IPS作为输入数据,使用GCNs对其进行推理,网络为每个节点输出一个得分,即对应的中枢轴邻居对之间的链接可能性。
以上步骤输出整个Graph的一组加权边,其中权值表示链接可能性,最后根据链接的可能性将链接的实例合并到cluster中。
3.2. Construction of Instance Pivot Subgraph构造实例中枢子图
我们估计两个人脸(节点)之间的链接可能基于他们在一个图中的局部上下文。我们提出构造实例中枢子图(IPS)作为上下文。首先定位所有的IPS节点,然后通过减去中枢节点特征归一化这个节点特征。
步骤1:Node discovery.给定主节点p,将它的邻居节点直到h-hop,对于每个hop。选择的最近邻居的数目可能有所不同。我们将i-th hop中最近的邻居数目设为ki,i=1,2..h.
例如设p为中枢节点, IPS Gp(Vp,Ep)包含节点集合Vp ,当k1=8,k2=4,k3=2时,表示8个最近邻居节点,4个1-hop邻居节点,2个2-hop邻居节点。需要注意Vp不包含中枢节点p。高阶邻居邻域中本身包含中枢节点和它的邻域之间局部结构上下文的辅助信息。例如,对于p和它的一个邻居q,如果q的KNN始终远离p,那么p和q之间联系的可能性就会很小。
步骤2:Node feature normalization.
现在有了中枢实例节点p、节点集合Vp和节点特征xp,通过减去xp将中枢节点信息编码到IPS的节点特征中,
![]()
使用Fp表示归一化节点特征。IPS的节点特征是中枢节点p的特征和对应邻居q的特征之间的残差向量。
步骤3:Adding edges among nodes.在节点之间添加边,对于节点集合Vp中的节点q,我们首先在整个原始集合的所有实例中找到u个最近的邻居节点。如果在Vp中出现了一个uNNs的节点r,我们向边的集合Ep添加一条边(q,r)。使用邻接矩阵Ap和节点特征矩阵Fp表示IPS的拓扑结构。
3.3. Graph Convolutions on IPS. IPS的图卷积
IPS中包含的上下文(节点之间的边)可以帮助确定一个节点是否应该链接到中枢节点。为了利用IPS对GCN进行修改执行推理任务。图卷积层以节点特征矩阵和邻接矩阵A作为输入,输出经过变换的节点特征矩阵。在第一层,输入节点特征矩阵作为原始节点矩阵特征,X=F.本文图卷积公式表示为
![]()
![]() N是节点的数目。
N是节点的数目。
din和dout分别是输入/输出节点特征的尺寸
G=g(X,A)是大小N×N的aggregation聚合矩阵,每行和为1。g()是进行聚合的函数。
运算符||表示沿矩阵维数进行串联。W是大小为dout×dout图卷积层可学习的权重矩阵,![]() 是非线性激活函数。
是非线性激活函数。
图的卷积运算可以分为两个步骤。第1步,X左边乘以G,聚合节点的邻居节点的底层信息。然后将输入节点的特征X与聚集的信息GX沿特征维度进行连接。第2步通过一组线性滤波器对所连接的特征进行变换,该滤波器的参数W需要学习。g()有三种方式。
Mean Aggregation. 平均聚合![]() ,A是邻接矩阵,
,A是邻接矩阵,![]() 为度矩阵。实际就是对邻接矩阵的归一化。
为度矩阵。实际就是对邻接矩阵的归一化。
Weighted Aggregation. 加权聚合,将A中的每个非零元素替换为相应的余弦相似度,并使用softmax函数沿每行对这些非零值进行归一化。加权聚合对邻居进行加权平均池化。
Attention Aggregation. 类似于注意力网络,G中的元素是由一个两层MLP使用一对中枢轴邻居节点的特征作为输入生成,MLP是端到端的训练。Attention Aggregation在邻居之间进行加权平均池化,权重自动学习。
本文使用的GCN是由Relu函数进行激活的四个图卷积层的堆栈,然后以softmax激活后的交叉熵损失作为优化目标函数。反向传播中,只传播1-hop邻居节点的梯度,我们只考虑一个中枢节点和它的1-hop邻居节点之间的联系。与传播全部节点的梯度相比,该策略在速度和精度方面都有提升。因为高阶邻居节点与中枢节点的多数是负联系。为了测试,也只对1-hop节点进行分类。
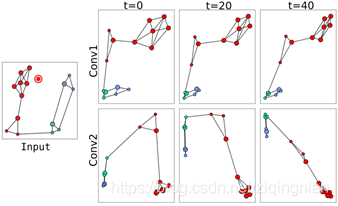
为了证明图卷积网络的工作机制,我们设计了一个2层图卷积网络的例子。为了实现可视化的目的,每一层的输出维度d1和d2设置为2。图4展示了每一层的输出随着迭代而变化。每个图卷积层后,正节点(红色)更紧密,负节点(蓝色、绿色)为另一组。因为在聚合的过程中,邻居的信息被传递给节点,来自邻居的信息作为嵌入的平滑性将节点进行链接。同时监督信号将正负样本分开。
3.4. Link Merging 链接合并(没看懂,没有足够的篇幅进行描述)
为了在人脸数据上应用聚类,我们循环遍历所有实例,构建一个IPS,每个实例作为中枢,并预测所涉及的实例与中枢之间的链接可能性(节点分类器softmax输出的概率)。我们得到了一组链接可能性加权的边,为了获得聚类,一种简单的方法是将权重低于某一个阈值的链接全部裁剪,然后使用Breath First Search呼吸优先搜索(BFS)传播伪标签,如图3所示,但是性能会受到选取阈值的较大影响。我们采取[34]提到的伪标签传播策略。在每次迭代中,算法将低于某个阈值的边切掉,并保持被链接簇的大小,且簇的大小需要大于下一次迭代中处理队列中处理队列预定义的最大值。在下一次迭代中,增加了被切掉的边的阈值。这个过程被迭代直到队列为空,这意味着所有实例将使用伪标签进行标记。
4. Experiment(本文的实验非常完善)
4.1. Evaluation Metrics and Datasets
为了评价算法的性能,采用NMI和F-measure。给出了![]() 的ground truth类集合,C的预测类集合,NMI定义为
的ground truth类集合,C的预测类集合,NMI定义为
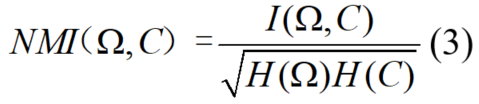
![]()
我们使用单独的数据进行训练和测试。 首先使用ArcFace作为face表征(输入的一部分),该模型在MS-Celeb-1M和VGGFace2数据集的并集上进行训练。其次对于GCN训练,使用CASIA数据集的一个随机子集,其中包括5k个face身份和200k样本。为了测试,使用IJB-B数据集,因为它包含一个clustering protocol. 这个protocol包含7个子数据集,子数据集的ground truth身份数目不同。我们在三个最大的子数据集上评估我们的算法。在三个子任务中,ground truth身份个数分别为512、1024和1845,样本个数分别为18,171、36,575和68,195。
4.2. Parameter Selection
三个超参数
h-hops,每个h-hop对应的最近邻居节点的数目ki,选择的链接的边的数目μ。
实验发现,h=2
训练时,期望得到更多的反向传播数据,k1=200,k2=10,设置μ=10确保每个2-hop至少有一条边。
测试时,参数设置与训练时不同,首先保持μ不变,改变k1,k2查看F-measure在IJB-B数据集上的变化。如图5所示,F-measure随着k1和k2的增大而增大,k1越大,被预测的候选链接越多,召回率也就越高。较大的k2涉及到更多的2-hop邻居,更精确地描述了1-hop邻居的局部结构,因此预测更准确。k1和k2过大时,性能达到饱和。性能对于参数μ并不敏感。
最终在接下来的实验中选择k1=80,k2=5,μ=5,在性能和效率之间取得了很好的平衡。
4.3. Evaluation
与几种常见的聚类方法进行比较。
Attention Aggregation优于其他两种聚合方法,但是考虑到计算代价,改进不明显,在接下来的实验中选择了Mean Aggregation。(虽然Attention Aggregation在某些方面优先,但是实验还是选择的最普遍的归一化)
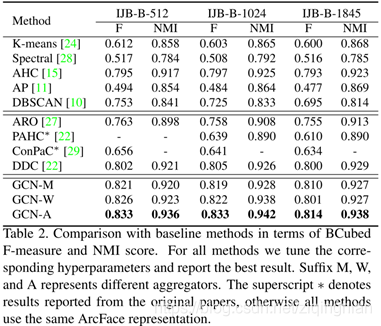
Comparison with baseline methods.
几种baseline方法中对数据分布做出较少限制假设的算法通常获得更高的性能。例如AHC没有对数据分布的假设,性能最好。我们的方法也不对数据分布做出假设,聚类规则是通过参数模型学习。
Comparison with state-of-the-art. 与先进的方法进行对比
表2的第二部分中,与4种最先进的人脸聚类算法进行对比,ARO,PAHC,ConPaC,DDC.
我们的方法在F-measure和NMI上的评分都优于其他方法,由于使用了不同的人脸表征,PAHC和ConPac的结果可能不能直接进行比较。然而,我们发现这两种方法都低于相应的AHC基线(具有相同的人脸表征),而我们的方法超过了AHC基线。这表明我们的方法的准确性是优于最先进的人脸聚类算法。
Different face representation.
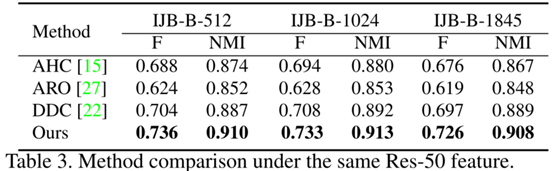
为了验证算法的优势来自算法本身而不是ArcFace表征,我们使用ResNet-50+softmax
Loss提取人脸表征,并用该表征测试聚类方法。表3为实验结果,表明在使用相同的表征的情况下,我们的算法优于最先进的算法。而采用更好的表征(Arcface)时,算法有最好的性能。
Singleton Clusters. 单样本类别
算法产生了许多单样本类别,其中大多数都是极端样本,如低分辨率face、模糊face等。我们过滤了所有的单样本类别,并在IJBB-512上重新测试了F-measure和NMI得分。我们专门测试了去除Singleton样本后其他三种聚类算法的性能。通过调整Singleton样本的比例测试不同算法的性能,然后删除Singleton样本测试性能,并绘制了两个指标的曲线,图6所示
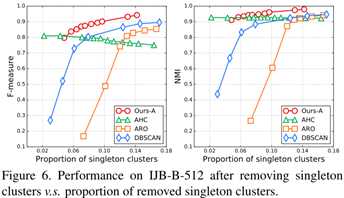
在Singleton样本比例相同的情况下,我们的算法始终优于其他算法。
Scalability and Efficiency. 可扩展性和效率
算法是有效的和可扩展的
4.4. Multi-View Extension
将方法运用在其他视频人脸聚类任务中,提取两种数据视图,人脸特征和音频特征,人脸特征和音频特征由两个CNN提取,然后链接为一个联和表征
5. Conclusion
本文提出了一种基于链接的人脸聚类方法。我们强调了上下文在人脸聚类中的重要性,提出了构建描述给定节点上下文的实例中枢轴子图(IPS)。在IPS上,我们利用图卷积网络来推理给定节点与其邻居之间的链接可能性。大量实验表明,与传统方法相比,该方法对复杂数据分布具有更强的鲁棒性。我们报告有利的可比结果,以最先进的方法在标准面部聚类基准,并表明我们的方法是可扩展到大型数据集。最后,我们展示了该方法在视听人脸聚类中的优势。