A Novel Graph based Trajectory Predictor with Pseudo Oracle
带有 Pseudo Oracle的新型基于图的轨迹预测器
作者:Biao Yang, Guocheng Yan
论文地址:
发表时间:
备注:
论文解析
代码开源
代码解析
摘要
动态场景中的行人轨迹预测在许多应用中仍然是一个充满挑战和关键的问题,例如无人驾驶汽车和具有社交意识的机器人。挑战集中在捕捉行人的社交互动和处理他们未来的不确定性上。行人的头部方向可用作指示相关行人的预言[1],因此对于建模社交互动很有帮助。此外,行人未来轨迹的潜在变量分布可以称为另一个预言。但是,很少有作品充分利用这些预言信息来提高预测性能。
在这项工作中,我们提出了GTPPO(带有伪Oracle的基于图的轨迹预测器),它是基于生成模型(generative model-based)的轨迹预测器。
建议的GA2T(图形注意力和社交注意力网络)模块可以捕获行人之间的社交互动。
社会关注度是根据行人的行进路线计算得出的,该行进路线被称为pseudo oracle。
此外,我们提出了一个潜在变量预测器,以从观测到的轨迹中学习潜在变量的分布。这种潜在的变量分布反映了行人的未来轨迹,因此可以被视为另一个pseudo oracle。
我们将GTPPO的性能与基准数据集上最近提出的几种方法进行了比较。定量评估表明,GTPPO优于最新方法,具有较低的平均和最终位移误差。定性评估表明,GTPPO成功地识别了突然的运动变化,因为估计的潜在变量反映了未来的轨迹。
1 引言
通常,我们的主要贡献是三方面。
(1)我们提出了一个GA2T模块来模拟行人的社交互动。我们使用行人的行进方向作为Pseudo Oracle来计算他们的社会关注度,然后通过突出显示相关行人之间的相关性来改进图形关注网络(GAT)。
(2)我们提出了一种新颖的潜在变量预测器,它可以估计知识丰富的潜在变量以提高预测性能。这种潜在变量包含有关行人未来轨迹的知识,因此可以称为另一个Pseudo Oracle。
(3)我们将GA2T模块和潜在变量预测器嵌入到基于生成模型的轨迹预测器中,以处理未来的不确定性。
此外,我们在ETH [12]和UCY [13]数据集上实现了最先进的性能。本文的其余部分安排如下。第二节回顾了相关作品。第三节详细介绍了建议的方法。第四节介绍了实验结果。第五节提供结论和讨论。
2 相关工作
A. Trajectory prediction methods
B. Graph models for modeling social interactions(用于建模社交互动的图模型)
C. Latent variable learning(潜在变量学习)
由于基于生成模型的方法具有处理未来不确定性的能力,因此已成为主流。潜在变量与生成的多峰输出具有很强的相关性。
随机高斯噪声通常用作潜变量[9] [23]。但是,它几乎不了解行人的运动特征或场景信息。
Lee等 [7]使用条件变分自动编码器执行了轨迹预测。潜变量是从观察到的轨迹中学到的。
袁等 [35]提出了一种多样性采样函数,以产生一系列可能的潜在变量。
张等[36]提出了一个随机模块,用于根据行人的历史运动生成潜变量。 T
ang等 [37]提出了一种动态编码器,以从多个输入中学习潜在变量,包括轨迹和环境。
但是,与仅处理轨迹数据相比,处理视觉上下文需要更多的计算。在这项工作中,我们提出了一种新颖的潜在变量预测器,该预测器仅从轨迹数据估计潜在变量。
此外,我们将行人的位置,速度和加速度输入到预测变量中,以了解有关环境背景,行人的运动模式及其激进性的知识。
与仅使用观测数据的参考文献[36]和[37]不同,我们试图弥合观测轨迹与地面真实轨迹之间的潜在变量分布差距。我们的灵感来自参考文献[38],该文献专注于具有先验知识的随机视频生成。
3 PROPOSED METHOD
在这项工作中,我们提出了GTPPO,它是一个基于图模型的轨迹预测器。 GTPPO可以产生准确的轨迹预测,同时保持各种输出。图2说明了GTPPO的系统管线。
A. Problem definition

B. Encoder-decoder network
类似于STGAT,我们使用编码器/解码器网络,因为它具有生成多模式输出的能力。
我们简要介绍一下编码器和解码器网络,如下所示:
Encoder network: 每个行人的运动模式都是一个时间序列,可以通过LSTM很好地建模。我们为每个行人使用共享的LSTM来编码运动模式。与STGAT相似,我们用MLSTM表示此LSTM。具体而言,单层MLP用于将行人i在时间t( ( Δ x i t = x i t − x i t − 1 \left(\Delta x_{i}^{t}=x_{i}^{t}-x_{i}^{t-1}\right. (Δxit=xit−xit−1, Δ y i t = y i t − y i t − 1 ) \left.\Delta y_{i}^{t}=y_{i}^{t}-y_{i}^{t-1}\right) Δyit=yit−yit−1))的相对位置转换为固定长度矢量等然后,将向量馈入M-LSTM,以在时间t生成行人i的运动状态,如下所示:
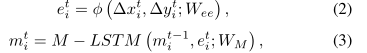
其中 ϕ ( ⋅ ) \phi(\cdot) ϕ(⋅)是嵌入函数。
Wee和WM分别是φ(·)和编码器函数M-LST M(·)的可学习权重。
之后,将行人的运动状态反馈到GA2T模块中,以汇总他们的社交互动。我们使用另一个共享的LSTM处理GA2T模块的输出以生成交互状态。与STGAT类似,我们用G-LSTM表示此LSTM,其定义如下:
g i t = G − LSTM ( g i t − 1 , m ^ i t ; W G ) g_{i}^{t}=\mathrm{G}-\operatorname{LSTM}\left(g_{i}^{t-1}, \hat{m}_{i}^{t} ; W_{G}\right) git=G−LSTM(git−1,m^it;WG)
其中 m ^ i t \hat{m}_{i}^{t} m^it是GA2T模块的输出。 WG是G − LSTM(·)的可学习重量。
Decoder network: 解码器网络用于未来的轨迹预测。馈入解码器模块的中间状态向量由三部分组成:M-LSTM的运动状态,G-LSTM的交互状态以及估计的潜在变量。我们在解码器模块中使用共享的LSTM,并将其称为D-LSTM。
然后,可以通过以下解码操作生成预测的相对位置:
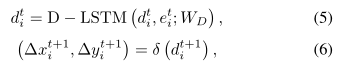
其中 W D W_{D} WD是D-LST M(·)的可学习权重,δ(·)是将嵌入转换为相对位置的线性层。 d i t d_{i}^{t} dit是mt i,gt i和估计的潜在变量zt i的串联。
等式为在时间t处的输入嵌入,它是根据等式(2)计算的。
D-LSTM的后续输入是根据最后预测的相对位置的嵌入来计算的。
C. G A 2 T GA^{2}T GA2T module
图形模型是对行人社交互动进行建模的有效工具,这对于准确的轨迹预测至关重要。场景中的行人被称为图上的节点,它们的交互可以通过图神经网络进行建模。在这项工作中,我们使用GAT通过将不同的重要性分配给不同的节点来汇总来自邻居的信息。有关GAT的详细信息,请参见STGAT [31]。
GAT可以从理论上以数据驱动的方式学习行人的社交互动。但是,由于缺少足够多的训练数据,学习过程总是很困难。作为常识,行人的未来轨迹总是受到前方人群的影响。
如图3的上部所示,目标一的未来轨迹仅受目标三的视野(FoV)中的目标三的影响。
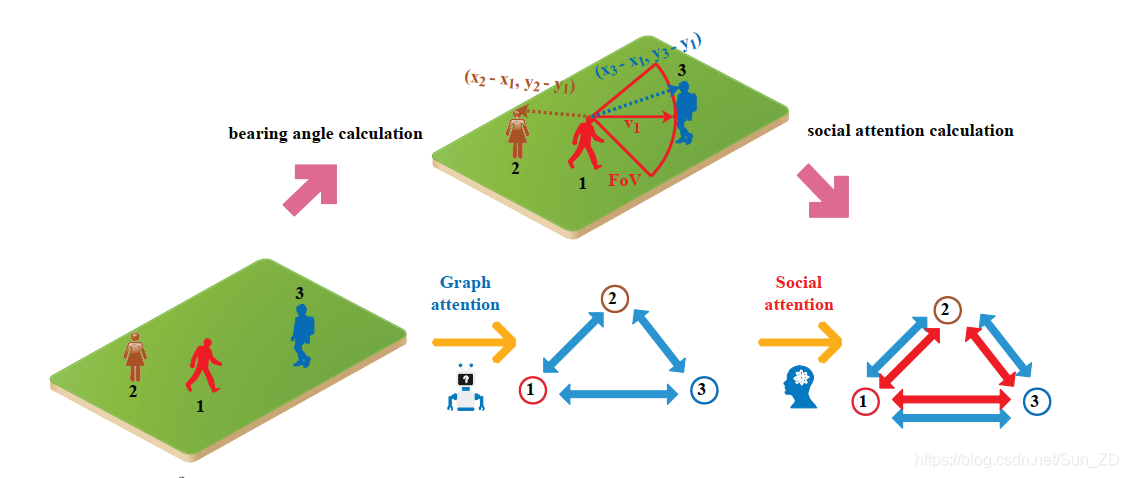
图3:GA2T模块。我们使用两项注意操作来汇总邻居的信息。前者是通过数据驱动的方式学习的图形注意,后者是社会关注,其受以下事实的启发:行人的未来轨迹始终受前面人的影响,而不受后面人的影响。行人的社会关注度是根据他们的方位角(最好以彩色显示)来计算的。
因此,行人的头部取向可以用作预言,以提高预测性能[1]。
因此,我们提出了GA2T模块,该模块可通过两次注意操作捕获行人的社交互动。如图3的下部所示,在自动学习的图形注意之后使用了包含人类知识的社交注意。
我们根据行人的方位角计算社会关注度。
我们将行人的行进方向用作pseudo oracle,因为很难从视觉数据中准确识别行人的头部方向。
然后,行人方位角的余弦值计算如下:
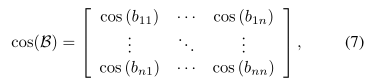
其中n是一个场景中的行人数量。 bij表示代理j与代理i的方位角,即代理i的速度与矢量连接代理i和j的夹角。然后,根据余弦值计算注意力权重。我们执行硬或软注意操作以完善GAT的输出。硬和软注意的表达方式如下:
Hard attention: 一个行人对另一行人的影响随着他们的方位角的增加而减小。
也就是说,余弦值越大,表示两个行人之间的影响越大。
因此,注意力集中的权重被表示为具有相同cos(B)大小的矩阵HA,并且HA的每个元素hij 通过阈值设置为0或1。如果cos(bij)大于经验阈值0,则将hijis设置为1,否则将其设置为0。
Soft attention: 与硬注意力通过阈值计算注意力权重不同,软注意力自适应地计算注意力权重SA,其公式如下:
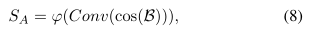
其中ϕ(·)表示S型激活,Conv(·)表示1×1卷积运算。
D. Latent variable predictor(潜在变量预测器)
如前所述,潜变量在基于生成模型的轨迹预测器中起着至关重要的作用。
GTPPO提出了一种新颖的潜在变量预测器,可以从轨迹数据中了解有关场景和行人特征的知识。
具体来说,我们训练一个潜变量预测变量,该变量可以分别从观察到的轨迹和地面真实轨迹估计相似的潜变量分布。
如图2所示,潜变量预测变量由两个前馈神经网络组成,其公式如下:
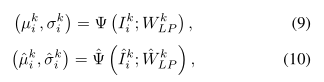

其中
Ψ ( ⋅ ) \Psi(\cdot) Ψ(⋅)和 Ψ ^ ( ⋅ ) \hat{\Psi}(\cdot) Ψ^(⋅)分别是权重为 W L P k W_{L P}^{k} WLPk和 W ^ L P k \hat{W}_{L P}^{k} W^LPk的前馈神经网络。
I i k I_{i}^{k} Iik和 I ^ i k \hat{I}_{i}^{k} I^ik是我们分别从观察到的轨迹和地面真实轨迹中提取的第k种输入(位置,速度和加速度)。
( μ i k , σ i k ) and ( μ ^ i k , σ ^ i k ) \left(\mu_{i}^{k}, \sigma_{i}^{k}\right) \text { and }\left(\hat{\mu}_{i}^{k}, \hat{\sigma}_{i}^{k}\right) (μik,σik) and (μ^ik,σ^ik)表示分别由Ψ(·)和ˆΨ(·)估计的第k种输入的潜在变量分布。
在训练阶段,行人i在时间t的估计潜在变量 z i t z_{i}^{t} zit,它是通过合并来自 ( μ ^ i k , σ ^ i k ) ( k = 1 , 2 , 3 ) \left(\hat{\mu}_{i}^{k}, \hat{\sigma}_{i}^{k}\right) \quad(\mathrm{k}=1,2,3) (μ^ik,σ^ik)(k=1,2,3)和随机高斯噪声 的样本来生成的。
在测试阶段, z i t z_{i}^{t} zit是通过合并来自 ( μ i k , σ i k ) ( k = 1 , 2 , 3 ) \left(\mu_{i}^{k}, \sigma_{i}^{k}\right) \quad(\mathrm{k}=1,2,3) (μik,σik)(k=1,2,3) 和随机高斯噪声的样本而生成的。
E. Loss function
这项工作中使用的损失函数由两部分组成,即variety 和潜在变量分布损失。
variety 损失用于在L2损失中拟合最佳预测轨迹,同时保持多样化的输出。
它的工作方式如下:模型为每个行人生成多个输出。
然后,它选择到地面真实距离的L2距离最小的轨迹,以计算出variety 损失,如下所示:
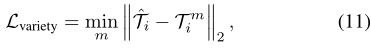
其中 T ^ i and T i m \hat{\mathcal{T}}_{i} \text { and } \mathcal{T}_{i}^{m} T^i and Tim分别是地面真值和 m t h m^{t h} mth预测的轨迹。
m是一个超参数,根据SGAN [9]设置为20。
潜变量分布损失用于测量观测轨迹和地面轨迹之间的潜变量分布间隙。
我们使用KL散度来计算损失,其公式如下:
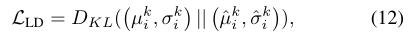
然后,以加权方式定义总损失,如下所示:
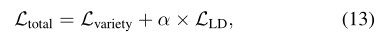
其中通过基准测试数据集的交叉验证将α设置为10.
F . Implementation details
一层LSTM用于编码器和解码器,其中隐藏状态的维度为32。
16维潜在变量包含一个四维随机高斯噪声和三个从位置,速度和加速度嵌入的四维矢量, 分别。
有关GAT模块的详细信息,请参见STGAT [31]。
我们使用Adam [39]优化器训练了批处理规模为400个时代的64个网络。
编解码器网络的学习率是0.001,潜变量预测器的学习率是0.0001。
提出的模型是使用Pytorch框架构建的,并使用Intel I7 CPU和NVIDIA GTX-1080 GPU进行了培训。
IV. EXPERIMENTAL RESULTS
公开的ETH [12]和UCY [13]对提出的方法进行了评估。这两个数据集包含五个子数据集,即ETH,HOTEL,UNIV,ZARA1和ZARA2。所有子数据集都包含具有丰富的人与人之间的对象交互场景的真实行人轨迹,包括人们彼此交叉,形成和分散的群体以及避免碰撞的场景。将1,536名行人的所有轨迹转换为现实世界的坐标。我们将采样频率降低到2.5Hz,以减少计算开销。我们使用与社交LSTM [8]相似的方法。具体来说,我们在四个集合上训练模型,并在其余集合上对其进行测试。观察到的地平线和预测的地平线分别为8(3.2秒)和12(4.8秒)个时间步长。预测水平用T表示。
此外,所提出的方法还通过以下两个误差度量进行评估:
1.平均位移误差(ADE):在所有预测水平上,预测轨迹与地面真实轨迹之间的平均L2距离。
2.最终位移误差(FDE):在最后一个预测步骤中,预测目标与实际最终目标之间的欧几里得距离。
A. Quantitative evaluations定量评估
Comparisons with state-of-the-art methods:
由于包括线性回归,vanilla-LSTM和社会力量模型在内的常用基准的性能要比Social-LSTM [8]差,因此我们仅将建议的方法与以下最新技术进行比较:
- Social-LSTM [8]:
- SGAN [9]
- SR-LSTM [22]
- Sophie [23]:
- S-Way [20]:
- Social-BiGAT [32]:
- STGAT [31]:
表1列出了我们的方法与最新方法之间的比较结果。
Social-LSTM和SGAN是使用深度神经网络的典型的基于确定性和生成模型的轨迹预测器。但是,它们的性能不如最近提出的方法令人满意。
Sophie使用两种注意力吸引机制来捕获社交互动,从而提高了预测性能。
除注意力机制外,S-Ways还计算行人之间的方位角,欧几里得距离和将来的最近距离,然后将它们输入到具有注意权重的改进的合并模块中。因此,S-Ways的性能优于ETH数据集中的其他方法。但是,S-Ways更注重捕捉社交互动,而不是编码行人的运动模式。结果,它在ZARA1和ZARA2数据集中表现不佳,而ZARA1和ZARA2数据集的挑战性不如ETH数据集。
SR-LSTM提出了一种状态优化模块,以汇总邻居的信息。它实现了与S-Ways相似的预测性能。
Social-BiGAT和STGAT使用图模型来捕获社交互动。具体来说,由于使用时空GAT,STGAT达到了次优的平均ADE和FDE。
它揭示了一个事实,即图模型擅长建模社交互动,这对于准确的轨迹预测非常重要。 STGAT中使用的时空机制使其优于Social-BiGAT,后者也使用GAT对社交互动进行建模。
我们的方法,尤其是一种使用软注意力机制的方法,在HOTEL,UNIV,ZARA1和ZARA2数据集的两个预测范围内均优于其他方法。将进行消融研究以探究预测性能如此优越的原因。
Ablation study: 对于消融研究,我们研究了GTPPO中使用的不同模块的效果,GTPPO是STGAT的改进版本,通过提出潜在变量预测因子和GA2T模块。
我们将整个模型表示为GTPPO-MLP-Soft或GTPPO-MLP-Hard。
MLP表示具有多个输入的潜在变量预测变量。软和硬分别代表软和硬注意机制。如表2所示,注意力机制鼓励模型捕捉复杂的社会互动。
因此,GTPPO-Soft和GTPPO-Hard可以在拥挤的UNIV数据集中提高STGA T的预测性能。通过以数据驱动的方式学习行人的社交互动,GTPPO-Soft的性能优于GTPPO-Hard。 GTPPO-MLP鼓励模型探索有关行人未来轨迹的知识。具体来说,GTPPO-MLP估计一个反映未来运动的潜在变量。与STGAT相比,除UNIV数据集中的ADE值外,大多数情况下都可以观察到改进。 GTPPO-MLP-Soft和GTPPO-MLP-Hard利用建模复杂的社交互动和从未来轨迹中学习知识的能力。具体而言,GTPPO-MLP-Soft实现了最低的ADE和FDE平均值。但是,它在ZARA1和ZARA2数据集中的性能略逊于GTPPO-MLP。一个可能的原因是GTPPO-MLP-Soft必须在学习软注意力机制和潜在变量预测变量之间进行权衡。
Evaluations of different sampling times:评估不同的采样时间:
基于生成模型的轨迹预测器通过生成多个输出来处理未来的不确定性。但是,由于variety loss ,许多产出离ground-truth还很远[41]。这些输出可能会基于预测的轨迹影响或误导进一步的决策。我们建议一个好的轨迹预测器应该在保持多样性输出的情况下,以很少的尝试来估计准确的未来轨迹。正如消融研究显示的那样,MLP模块鼓励模型研究行人的未来运动。因此,所提出的方法可以基于从未来轨迹中学到的知识,以很少的尝试来执行精确的轨迹预测。当逐渐减少采样时间时,我们在STGAT和GTPPOMLP之间进行比较。
图4示出了当使用不同的采样数时,STGAT和GTPPO-MLP之间的平均ADE和FDE的比较结果。
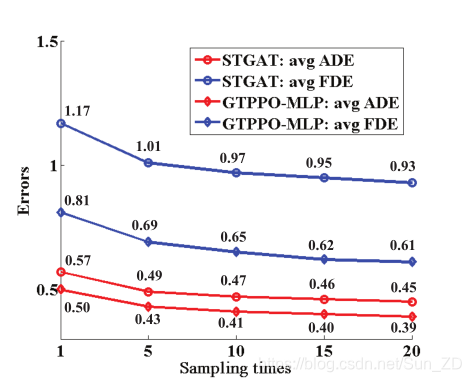
对于这两种方法,当逐渐减少采样时间时,预测性能都会变差。但是,GTPPO-MLP仍然可以在很少采样的情况下执行令人满意的轨迹预测。如图4所示,使用5个采样的GTPPO-MLP的平均ADE为0.43,而使用20个采样的STGAT的平均ADE为0.45。一次采样的GTPPO-MLP的平均FDE优于一次采样的STGAT的平均FDE。所有这些发现揭示了GTPPO-MLP进行准确轨迹预测的能力,而很少尝试。
Computational time analysis:(计算时间分析:) 轨迹预测的计算时间是实时应用的关键问题。与STGAT相比,我们计算了所提出方法的计算时间。

表III:与STGA T相比,所提出方法的计算时间。我们计算一次正向计算批为64的时间。时间单位为毫秒。
如表3所示,由于在测试期间仅添加了简单的前馈神经网络,因此MLP模块的计算开销很小。由于计算方位角,GTPPO-MLP-Hard和GTPPO-MLP-Soft需要大约四倍的计算开销。值得注意的是,我们在一次正向计算中同时处理了64个场景。因此,所提出的方法可以满足实时应用的需求。此外,人们可以在不太拥挤的场景中使用GTPPO-MLP,以获得更好的实时性能。
B. Qualitative evaluations(定性分析)
我们进行了一些定性评估,以深入了解GTPPO。
图5显示了在不同数据集中使用STGAT,SR-LSTM,Sophie,GTPPO-MLP,GTPPO-MLP-Soft和GTPPO-MLP-Hard进行的轨迹预测结果。

图5:在(a)ETH,(b)HOTEL,(c)ZARA1和(d)中使用STGA T,SR-LSTM,Sophie,GTPPO-MLP,GTPPO-MLP-Soft和GTPPO-MLPHard进行的轨迹预测结果)ZARA2数据集。红线和蓝线分别表示观察到的轨迹和地面真实轨迹。不同颜色的虚线表示通过不同方法预测的轨迹。我们从20个预测的样本中显示了具有最低ADE值的最佳轨迹(最佳观察颜色和放大)。
每个子图代表具有多个标记行人的场景。与以前的工作类似,在每种方法生成的20个样本中,预测的轨迹是ADE值最低的最佳轨迹。
通常,在大多数情况下,所有方法都会执行准确的轨迹预测。
这些方法成功地识别出静止的行人,例如,在图5(b)的第二个场景中瞄准了一个和两个目标。通过生成更近的未来轨迹,我们的方法比选定的方法表现更好。除了获得更接近的输出外,我们的方法还可以成功应对具有挑战性的突然运动变化。如图5(a)的第一个场景所示,STGAT,SR-LSTM和Sophie无法捕获目标对象的运动变化。但是,我们的方法识别出由于估计的潜在变量(反映未来运动)而引起的运动变化,然后执行准确的轨迹预测。
在其他场景中也可以观察到类似的结果,例如,图5(a)的第三场景,图5(c)的第三和第四场景以及图5(d)。这些发现揭示了这样一个事实,即在大多数情况下,从位置,速度和加速度中学到的信息对于准确的轨迹预测很有用。
除最佳轨迹外,预测轨迹的密度图还揭示了不同方法生成准确多样的输出的能力。
图6说明了从(a)ETH,(b)HOTEL,(c)ZARA1和(d)ZARA2数据集选择的四个典型场景中的预测轨迹的密度图。

由于每个场景中的轨迹太多,因此未显示UNIV数据集中的密度贴图。在ETH场景中,GTPPO-MLP和GTPPO-MLP-Soft识别突然的运动变化,而STGAT失败。此外,由于使用了软注意力机制,因此GTPPO-MLP-Soft生成的密度图比GTPPO-MLP生成的密度图更独立。在HOTEL场景中,所有方法都会为目标1生成错误的未来轨迹,以避免与目标2发生冲突。但是,通过我们的方法预测的轨迹更接近于地面。在ZARA1方案中,GTPPO-MLP和GTPPOMLP-Soft可以识别目标2和目标3的缓慢移动,而STGA T仍可以预测远距离的未来轨迹。在ZARA2方案中,GTPPO-MLP和GTPPO-MLPSoft成功识别了目标对象的运动变化,而STGA T失败。
V. CONCLUSION AND DISCUSSION
在这项工作中,我们提出了GTPPO,它使用两个pseudo oracles执行轨迹预测。pseudo oracles是行人在最后观察到的一步的行进方向,用于近似行人的头部方向。通过添加根据行人的行进方向计算出的社会关注度,提出了一种改进的GAT模块GA2T。经过验证,GA2T可以在拥挤的数据集中实现更高的预测性能。另一个pseudo oracles是由新型潜在变量预测器估计的潜在变量。这样的潜在变量学习有关未来轨迹的知识。随机高斯噪声被注入到估计的潜在变量中以处理未来的不确定性。在五个公开可用的数据集上,以两个常用度量(即ADE和FDE)执行评估。与最新方法的比较表明,该方法在轨迹预测中具有优势。消融研究和定性评估揭示了不同模块的效果,尤其是潜变量预测变量识别突然运动变化的能力。此外,该方法仅从轨迹中学习知识,从而满足实时性能的要求。我们的未来集中在如何控制潜在变量预测变量以生成更好的潜在变量上。