文章目录
Encrypted Malware Traffic Detection via Graph-based Network Analysis
中文题目:基于图的网络分析加密恶意软件流量检测
发表会议:RAID 2022: 25th International Symposium on Research in Attacks, Intrusions and Defenses
发表年份:2022-10-26
作者:Zhuoqun Fu, Mingxuan Liu, Yue Qin, Jia Zhang, Yuan Zou1, Qilei Yin, Qi Li, Haixin Duan
latex引用:
@inproceedings{fu2022encrypted,
title={Encrypted Malware Traffic Detection via Graph-based Network Analysis},
author={Fu, Zhuoqun and Liu, Mingxuan and Qin, Yue and Zhang, Jia and Zou, Yuan and Yin, Qilei and Li, Qi and Duan, Haixin},
booktitle={Proceedings of the 25th International Symposium on Research in Attacks, Intrusions and Defenses},
pages={495--509},
year={2022}
}
摘要
互联网恶意活动在数量和危害上持续增长,对社会构成严重威胁。具有远程控制功能的恶意软件被认为是最具威胁性的恶意活动之一,因为它可以实现任意类型的网络攻击。针对这种情况,许多恶意软件检测方法被提出来识别基于流量特征的恶意行为。
然而,新兴的加密和规避技术对充分利用网络信息构成了巨大的障碍。这大大削弱了依赖于单一类型特征的现有恶意软件检测方法的有效性。
在本文中,我们提出ST-Graph来解决这个问题。除了传统的流属性,ST-Graph基于图表示学习算法探索网络行为的空间和时间特征,并集成所有可用信息来提高检测决策。
为了说明ST-Graph的有效性,我们在两个数据集上评估了它。实验结果表明,ST-Graph在效率、泛化性和鲁棒性方面优于最先进的恶意软件检测系统。具体来说,它达到了超过99%的精度和召回率,其假阳性率甚至比基线模型低了两个数量级(近0.02倍)。同时,ST-Graph在两种真实网络场景中部署了一年左右的时间,在1.7 Gbps带宽下,5分钟的流量仅花费了160秒的时间,效率非常突出。
存在的问题
- 大多数流量的加密极大地限制了表明恶意网络行为的可访问信息(例如,有效载荷中的URL和HTTP头)。这削弱了传统基于网络的恶意软件检测的准确性和一致性,如深度包检测。
- 为了扩大指示性信息集,[3,19]总结了TLS流量的细粒度特征,并使用机器学习方法识别由已知恶意样本生成的加密流量。这种方法依赖于人类的先验知识和特征提取。
- 深度学习方法基于单一流特征的检测方法无法推广到未知样本,可能会产生大量无法解释的假阳性。
- 加密恶意软件检测缺乏代表性信息的问题还没有得到很好的解决。以往的工作只使用单一类型的特征,如流特征或上下文信息,而信息丢失和压缩仍然存在。
论文贡献
- 提出了ST-Graph,一个加密场景下的实时恶意流量检测框架。ST-Graph通过探索和集成多种特征,有效地揭示加密网络中的恶意行为,从而实现低误报率的检测。
- 为加密流量设计了一个异构属性图,并提出了一种新的嵌入方法,即间隔倾斜随机游走,用于探索和融合流量数据的时空特征。
- 我们在几个真实的网络场景中对检测系统进行了长达一年的评估,并观察到良好的结果。与其他工作相比,我们的检测模型具有更高的精度(接近基线的10倍),并且在可容忍的时间成本下显著降低假阳性。
- 通过实际部署,我们的检测系统发现了一些其他系统无法发现的恶意案例,并揭示了一些新兴的恶意流量类型。
论文解决上述问题的方法:
信息丢失和压缩的问题:
提出了ST-Graph,从空间和时间角度探索多个特征,并集成所有可用信息,用于加密场景下的全面恶意软件流量检测。
更具体地说,我们设计了一个面向时空流量行为的属性异构图,该图有效地捕捉了大规模网络中节点之间的关联特征。我们的方法配备了图形表示学习方法,扩展了可用于识别加密恶意流量的信息范围,从而提高了检测的准确性和鲁棒性。
同时,我们精心设计了基于随机游走[49]的图表示学习算法,高效地学习网络流量的时空特征。学习到的主机表示是从网络中的行为序列中汇总信息,这有效地突出了受害主机和良性样本之间的流量差异,几乎没有信息损失。
论文的任务:
- 恶意软件检测:主机是否被恶意软件感染(二分类)
- 恶意软件家族分类(多分类)
1. 威胁模型

ST-Graph部署在网关,主要用于监听内部主机访问网关处的外部服务器时产生的加密网络流量,实时检测存在可疑通信的受感染主机。在这项工作中,我们只关注标准化的TLS协议加密流量。由于它易于部署,因此它是恶意软件使用率最高的主流加密协议。需要注意的是,我们的检测系统只捕获流量而不进行操作,因此不会影响良性转发流量。
这种检测方法的挑战:
- 可用信息有限,限制了检测的有效性(准确率、鲁棒性)
第一个担忧来自最近的加密和对手的规避技术,这些技术大大减少了可用于检测的信息量。在加密场景中,通信有效载荷的不可见性使得传统检测方法无法做出准确的预测。更严重的是,对手已经进化出几种技术来逃避现有的基于单流的检测方法[17,61,65]。
(1)在基于模糊的逃避中,攻击者改变主机对命令和控制(C&C)服务器的访问频率[26],从而模糊主机的可疑属性,以逃避基于数据包长度和时间间隔的检测[3,19,45]。
(2)在基于伪装的逃避中,恶意软件采取良性软件连接的形式,伪装其流量是由良性软件产生的,最初作为前台访问良性第三方网站,或减少访问的网站数量以避免基于上下文的检测。可疑行为隐藏在数以百万计的合法请求背后,这对有效检测造成了巨大障碍,并引入了高水平的假阳性。因此,加密和逃避行为促使我们探索更多可用的信息,以进行有效的检测。
- 网络连接过于全面,阻碍了检测的效率。(实时性)
对于第二个问题,由于网络用户数量的增加和网络连通性的复杂,对网络交互的检测面临着大量的网络吞吐量。同时,为了有效检测而探索额外的、多面特征的需求也加剧了计算的复杂性。因此,我们需要设计新的检测技术,能够在可容忍的计算复杂度下,在全面的网络交互中探索和处理更多的网络特征。
2. 系统概述
2.1 实证研究的观察
在前人研究发现部分恶意软件在攻击目标和攻击方法上存在相似性的基础上[29,46,57],我们从代码和生成流量两个方面对远程控制恶意软件进行了手工分析。
-
首先,我们随机抽取30个恶意软件作为基础,并在我们控制的几个操作系统上运行它们。注意,整个实验环境是封闭的,不会影响任何第三方。从代码方面,我们对他们的代码进行了反向分析,分析了代码逻辑和硬编码的内容。发现
- 同一家族的恶意软件倾向于共享相似的软件框架,这是造成相似流量行为的根本原因。
- 恶意软件通常不是最新的,仍然接受低版本的TLS连接。
- 恶意软件的开发人员经常使用默认的固定参数,特别是时间间隔。例如,我们发现一些恶意软件通常将连接控制服务器的时间间隔设置为60秒。
-
由于远程控制攻击具有明确的联合攻击目的,即远程控制被感染主机,因此远程控制攻击存在相对固定的流量模式。

通信过程可以概括为两个主要阶段:攻击阶段(实线)和控制阶段(虚线)。
攻击阶段:通过欺骗网站(灰圈)或利用漏洞安装恶意软件,将恶意软件发送到受害者的机器,这可以帮助对手获得对主机的控制。
例如,图3中的H2,攻击者在攻击阶段通过发送钓鱼邮件进行欺诈活动,并引诱受害者点击嵌入的链接,这可能会导致钓鱼网站(灰圈)重定向到恶意软件下载网站。
控制阶段:受感染的主机将连接到对手的控制服务器,接收并执行指令。
我们发现大多数恶意软件倾向于在不同的阶段连接到不同的目标服务器,这构成了一个连接顺序。我们推测其原因可能是为了逃避侦查。有趣的是,恶意软件的伪造无辜网络连通性测试很常见,这是在连接控制服务器之前的准备,例如查询主机的公共ip或下载服务器的证书。
例如,在图3中,连接到白色圆圈的虚线表示网络连接测试行为。具体来说,受感染的主机可能主动连接外部服务器(如第三方服务器)进行网络检查。根据上述观察,可以从以下几个方面总结恶意软件感染的常见特征:
空间特征:指主机与目标服务器之间的集中特性,尤其在家族内部。如前所述,由于框架重用,同一家族中的一些恶意软件表现出很高的相似性,这反映在它们试图连接的目标服务器上。例如,在图3中,H2和H3在控制阶段连接到相同的目标服务器。
连接的时间特征:主机在一段时间内的连接顺序可以帮助我们重建恶意软件的感染过程,可以清楚地显示其随阶段的变化。此外,由于固定参数的设置,被感染主机与控制服务器之间的通信是有规律的,特别是报文长度和报文间隔时间。
空间特征反映了各主机网络连接关系的性质。
时间特征显示了通信的侧信道信息。
2.2 系统设计

基于观察到的特征,我们设计了ST-Graph,它将主机网络行为的空间(即主机和服务器之间的访问)和时间(即连接顺序和时间相关信息)特征整合到主机表示中,以提高检测决策的有效性。为了获得更高的效率,我们只通过迭代更新优化边表示来改进图表示的算法,而最优节点表示则来自封闭形式的解。这大大降低了图表示学习的计算复杂度。
2.3 工作流程
-
数据预处理器(Traffic Preprocessor)
- 从每个原始数据包中提取一个5元组(即<源IP,源端口,目的IP,目的端口,协议>),并将与同一5元组相关联的数据包集成为一个流。
- 用一个完整的TLS握手来保留TLS协议的流量,并提取每个流的关键信息。更具体地说,我们在每个保留的TLS流中提取TLS握手的内容,包括TLS版本和支持的密码套件,并计算一些统计信息,例如流中的数据包数量和字节数。从数据流中提取的这种统计信息仍然是恶意软件流量检测的重要元素,并在稍后的图表示的计算中使用。
-
图表示器(Graph Representor)
建立了一个异构图,通过时间和空间特征来表示主机和服务器之间的端到端通信。具体来说,时间特征是我们从流中提取的流量特征,这些特征嵌入到流表示中;图形结构体现了空间特征。在此基础上,我们设计了一种节点嵌入算法,将时空特征转化为反映主机访问行为相似性的主机表示。我们将在下面详细阐述这个模块。
-
检测器(Detector)
给定每个主机的嵌入向量,数值量化主机的行为特征,我们应用机器学习方法来计算主机被感染的可能性。考虑到[12]抗过拟合的能力以及在对比实验中的更好表现(见附录A),我们最终采用随机森林(RF)回归算法作为我们的检测器。它是一种集成学习方法,通过平均多个决策树的输出来进行预测。根据每台主机的预测感染值,检测器输出可疑主机列表及其访问信息。
2.4 ST图(ST-GRAPH: SPATIO-TEMPORAL GRAPH,时空图)
- Graph Construction:首先构建一个异构图来关联主机和服务器之间的所有网络连接。
- Edge Embedding:基于图结构,我们应用随机游走[16]为每个流生成对应的连接列表,并使用概率模型优化边表示。每个流由其边表示和流量特征表示。
- Host Representation:最后,我们用主机的所有访问顺序来表示每台主机,集成了与主机相关的流量特征和网络结构。
ST-Graph采用少量迭代的随机游走学习边嵌入,并采用封闭形式的解决方案优化主机嵌入。这大大降低了计算复杂度,满足了实时检测的需要。
-
图构建(Graph Construction)
图拓扑: G = ( H , D , E , S , I ) G = (H, D, E, S, I) G=(H,D,E,S,I)
顶点集合 H H H :
内部主机。每一个由其IP表示为唯一标识符
顶点集合 D D D :
外部服务器。每个顶点都由服务器的域名或其IP地址初始化。域可以从ClientHello中的SNI中获取,当域不可用时,服务器的IP地址作为替代。
边集 E = { E ∣ E = ( h e , d e ) , h e ∈ H , d e ∈ D } E = \{E | E = (h_e,d_e),h_e∈H,d_e∈D\} E={ E∣E=(he,de),he∈H,de∈D}:
主机和服务器之间的所有连接(即流)。如果主机 h h h 与服务器 d d d 进行TLS握手,则连接这两个节点的边 e = ( h , d ) e = (h,d) e=(h,d) 将被添加到 E E E 中。
I = { i e ∣ e ∈ E } I = \{i_e |e∈E\} I={ ie∣e∈E}:
每条边的时间特征,其中 i e i_e ie 表示其主机 h e h_e he 连接的 e e e 的顺序。例如:

S = { s e ∣ e ∈ E } S = \{s_e |e∈E\} S={ se∣e∈E}:
如下所述从流中提取的特征。
邻接矩阵示意图:
流特征:
- 从内部主机提取的TLS握手特征
观察到恶意软件和C&C服务器不会及时更新,因此它们通常接受较低的TLS版本,并保持对弱加密算法的支持能力。潜在的原因是攻击者相对不太关心通信是否会被解密,而且低版本操作系统中的漏洞更容易被利用。
提取的特征:从TLS ClientHello消息中提取特征,包括TLS版本、提供的密码套件列表和作为TLS握手特征的扩展。
- 从外部节点提取的域名特征
主要基于许多恶意域是通过域生成算法(DGA)计算的。
提取的特征:数字,字符的比例,元音或辅音字母的比例。还提取域名长度特征来处理基于词库的DGA(它从专有字典中选择单词进行组合以减少随机性)。
- 流的侧信道统计特征。
尽管数据包长度和到达时间不能提供连接内容的信息,但它们可以帮助推断网络行为。例如,用于维护连接的大量心跳包可能导致每个流中只存在很少的数据包。因此,我们计算一些统计信息,如在流中发送和接收数据包的数量、长度或时间间隔。
提取的特征:在流中发送和接收数据包的数量、长度或时间间隔等统计信息。
-
边嵌入(Edge embedding)
随机游走策略:
先给出一些声明:对于边 e e e 来说:
- 随机游走次数为 P N P_N PN ,对于 P N P_N PN 而言,最大不能超过 P L P_L PL 步,即 P N < = P L P_N<=P_L PN<=PL
- 随机游走经过的边集合记为: N e N_e Ne
- 边 e e e 的邻边集合记为 C e C_e Ce: C e = { u : ( h u , d u ) ∣ u ∈ E , h e = h u 或 d e = d u } C_e = \{u :(h_u,d_u)|u ∈ E,h_e = h_u 或 d_e = d_u \} Ce={ u:(hu,du)∣u∈E,he=hu或de=du}
简单理解:就是对于边e而言,所有的和它共有节点的边。(就是最直观的理解)
- 两条边 u , v u,v u,v之间的连接阶距离 d d d 为 d ( u , v ) = ∣ i u − i v ∣ d(u,v) = |i_u−i_v | d(u,v)=∣iu−iv∣
其中 i e i_e ie 为边 e e e 由它的主机(注意不是服务器) h e h_e he连接的顺序。
(1)随机游走来收集 N e N_e Ne
起始节点:
假设从边 o o o 出发,该边的相邻边集合为 C o C_o Co,那么它走向下一个相邻边 x x x(其中 x ∈ C o x \in C_o x∈Co)的概率为: P r ( w 1 = x ∣ w 0 = o ) = 1 d ( o , x ) ∑ y ∈ C o 1 d ( y , o ) Pr(w_1=x|w_0=o) = \frac{\frac{1}{d(o,x)}}{\sum_{y\in C_o} \frac{1}{d(y,o)}} Pr(w1=x∣w0=o)=∑y∈Cod(y,o)1d(o,x)1
下面是我的理解,用下图来模拟一个例子:红色代表边 o o o,黄色代表边 o o o 的邻边集合 C o C_o Co,三角形代表服务器 S i S_i Si,圆圈代表主机 h i h_i hi,如图所示,图中有两台主机 h 1 、 h 2 h_1、h_2 h1、h2,三台服务器 S 1 、 S 2 、 S 3 S_1、S_2、S_3 S1、S2、S3 。
下面的公式推导是 “起始边为 o o o(图中即边1),下一步为边2”的概率的计算方法:

特点:在上面的矩阵中可以发现,如果起始边的位置为(i,j),那么它的邻边就是他所在行和列中的值不为0的边。

使用上述概率计算公式有以下好处:倾向于选择与当前边连接顺序距离最小的边作为下一步。所以可以推出,在小时间间隔内生成的流往往是随机游走中的连续步骤。
中间节点:
假设当前位置为边 v v v ,上一个位置为边 u u u,那么它走向的下一个相邻边 x x x 的概率为: P r ( w i + 1 = x ∣ w i = v , w i − 1 = u ) = α u , x ∗ 1 d ( v , x ) ∑ t ∈ C v α u , t ∗ 1 d ( v , t ) Pr(w_{i+1} = x |w_i = v, w_{i−1} = u) = \frac{\alpha_{u,x} * \frac{1}{d(v,x)}}{\sum_{t\in C_v}\alpha_{u,t}*\frac{1}{d(v,t)}} Pr(wi+1=x∣wi=v,wi−1=u)=∑t∈Cvαu,t∗d(v,t)1αu,x∗d(v,x)1
α u , x = { 1 / p , x = = u 1 , x 是 u 的一个近邻时 1 / q , 其他 \alpha_{u,x}= \begin{cases} 1/p,\quad x == u\\ 1,\quad x是u的一个近邻时\\ 1/q,\quad 其他 \end{cases} αu,x=⎩ ⎨ ⎧1/p,x==u1,x是u的一个近邻时1/q,其他其中,这里的 p 、 q p、q p、q 为超参数。
- p p p 用来控制从v回到起点u的概率。
- q q q 用来控制v去到新节点的概率。当q < 1时,倾向于访问全局节点(DFS);如果q > 1,倾向于访问本地节点(BFS),这增强了对周围邻居的覆盖。

(2)为了将图的空间和时间特征合并到边嵌入中,为每条边设置一个向量 r e r_e re,那么边 e e e 与边 n n n 相关的可能性计算公式为: P r ( n ∣ e ) = e x p ( r e ⋅ r n ) ∑ v ∈ E e x p ( r e ⋅ r v ) Pr(n |e) = \frac{exp(r_e · r_n)}{\sum_{v ∈E} exp(r_e · r_v )} Pr(n∣e)=∑v∈Eexp(re⋅rv)exp(re⋅rn)
(3)假设不同边对之间的邻域关系是独立的,并进一步定义边 e e e 的邻域似然为: P r ( N e ∣ e ) = ∏ n ∈ N e P r ( n ∣ e ) Pr(N_e|e) = \prod_{n\in N_e}Pr(n|e) Pr(Ne∣e)=n∈Ne∏Pr(n∣e)
(4)文中借鉴了skip-gram模型来获取每条边的embedding,其中skip-gram模型使用了negative sampling来降低计算量。
l o s s p o s = − 1 b a t c h _ s i z e ∑ l o g ( P r ( 正样本向量 ∣ e ) ) loss_{pos} = -\frac{1}{batch\_size}\sum log(Pr(正样本向量|e)) losspos=−batch_size1∑log(Pr(正样本向量∣e))
l o s s n e g = − 1 b a t c h _ s i z e ∗ n e g _ s u m ∑ l o g ( 1 − P r ( 负样本向量 ∣ e ) ) loss_{neg} = -\frac{1}{batch\_size*neg\_sum}\sum log(1-Pr(负样本向量|e)) lossneg=−batch_size∗neg_sum1∑log(1−Pr(负样本向量∣e))
l o s s = 1 2 ( l o s s p o s + l o s s n e g ) loss = \frac{1}{2}(loss_{pos} + loss_{neg}) loss=21(losspos+lossneg)
(5)最后,通过连接它的流特征 s e s_e se 和它的时空嵌入 r e r_e re 来表示边 f e = φ ( [ s e ∣ ∣ r e ] ) f_e = φ ([s_e ||r_e]) fe=φ([se∣∣re])其中 φ ( x ) = x ∣ x ∣ φ (x) = \frac{x}{|x|} φ(x)=∣x∣x是一个归一化函数。 -
主机表示(Host Representation)
- 对于主机 h h h ,我们用一个图 g h g_h gh 来表示主机在短时间内的顺序访问行为: g h = P r o p a g a t e ( r e ∣ e ∈ E ∧ h e = h ) g_h = Propagate({r_e |e ∈ E ∧ h_e = h}) gh=Propagate(re∣e∈E∧he=h)
- 对于目标主机 t t t,假设 u u u 是 t t t 通过流 e = ( t , u ) e = (t,u) e=(t,u) 访问的服务器。
- 在网络流量中,每台主机可能访问许多公共服务来获取大量流量数据,这对于描述主机的行为并不是很有信息量。因此,我们根据在信息传播之前通过流访问的服务器的重要性对与主机关联的流进行排名:
- 所有主机 H H H 访问该服务器的频率
- 主机 t t t 访问服务器 u u u 的顺序( i e : e ∈ E , h e = t ∧ d e = u i_e:e∈E,h_e = t∧d_e = u ie:e∈E,he=t∧de=u)
- 直观地说,如果一个服务器 u u u 被大多数主机访问,那么它很可能也会被目标主机 t t t 访问
- 如果 t t t 在非常早期的阶段访问 u u u ,那么相对于其他服务器, u u u 是 t t t 的重要访问目的地
- 因此,我们定义边 e e e 对它的主机 t t t 的重要性为: ρ ( e ) = ∣ { e ′ ∣ e ′ ∈ E ∧ d e ′ = u } ∣ i e ⋅ ∣ E ∣ \rho(e) = \frac{|\{e'|e'\in E \wedge d_{e'} = u\}|}{i_e · |E|} ρ(e)=ie⋅∣E∣∣{ e′∣e′∈E∧de′=u}∣
其中, ∣ { e ′ } ∣ |\{e '\}| ∣{ e′}∣是结束于 u u u 的边的数量, ∣ E ∣ |E| ∣E∣ 是边的总数, i e i_e ie 是边 e e e 被 t t t 连接的顺序。
- 主机 t t t 和边缘 e e e 之间的相关评分: c o r r ( t , e ) = λ ρ ( e ) + ( 1 − λ ) e x p ( g t ⋅ f e ) ∑ i ∈ E e x p ( g t ⋅ f i ) corr(t, e) = λρ(e) + (1 − λ) \frac{exp (g_t · f_e )}{ \sum_{i ∈E} exp (g_t · f_i )} corr(t,e)=λρ(e)+(1−λ)∑i∈Eexp(gt⋅fi)exp(gt⋅fe)
- 令 L t = { e ∣ e ∈ E ∧ h e = t } L_t = \{e|e∈E∧h_e = t\} Lt={ e∣e∈E∧he=t} 表示所有从主机 t t t 出发的边。 L t L_t Lt 中所有边的联合相关评分定义为: C O R R ( L t ) = ∏ e ∈ L t c o r r ( t , e ) = ∏ e ∈ L t [ λ ρ ( e ) + ( 1 − λ ) e x p ( g t ⋅ f e ) ∑ i ∈ E e x p ( g t ⋅ f i ) ] CORR(L_t) = \prod_{e \in L_t}corr(t,e) = \prod_{e \in L_t} [λρ(e) + (1 − λ) \frac{exp (g_t · f_e )}{ \sum_{i ∈E} exp (g_t · f_i )}] CORR(Lt)=e∈Lt∏corr(t,e)=e∈Lt∏[λρ(e)+(1−λ)∑i∈Eexp(gt⋅fi)exp(gt⋅fe)]
- 对于该联合相关评分的对数形式可用一阶泰勒展开近似表示为: l o g [ C O R R ( L t ) ] ≈ [ ∑ e ∈ L t ( l o g ( λ [ ρ ( e ) + ξ ] ) + ξ ρ ( e ) + ξ ) ⋅ f e ] ⋅ g t log[CORR(L_t)] \approx [\sum_{e \in L_t}(log(λ[ρ(e)+\xi]) + \frac{\xi}{ρ(e)+\xi})·f_e] · g_t log[CORR(Lt)]≈[e∈Lt∑(log(λ[ρ(e)+ξ])+ρ(e)+ξξ)⋅fe]⋅gt
其中, ξ = 1 − λ λ Z ξ = \frac{1−λ}{λZ} ξ=λZ1−λ(其中 Z = ∑ i ∈ E e x p ( g t ⋅ f i ) Z = \sum_{i ∈E} exp (g_t · f_i ) Z=∑i∈Eexp(gt⋅fi)),这是一个常量,
- 通过最大化 l o g [ C O R R ( L t ) ] log[CORR(L_t)] log[CORR(Lt)] 来获得主机 g t g_t gt 的最优表示,首先定义向量 M t = [ ∑ e ∈ L t ( l o g ( λ [ ρ ( e ) + ξ ] ) + ξ ρ ( e ) + ξ ) ⋅ f e ] M_t = [\sum_{e \in L_t}(log(λ[ρ(e)+\xi]) + \frac{\xi}{ρ(e)+\xi})·f_e] Mt=[e∈Lt∑(log(λ[ρ(e)+ξ])+ρ(e)+ξξ)⋅fe]那么 l o g [ C O R R ( L t ) ] log[CORR(L_t)] log[CORR(Lt)]就可以表示为:
l o g [ C O R R ( L t ) ] ≈ M t ⋅ g t log[CORR(L_t)] \approx M_t · g_t log[CORR(Lt)]≈Mt⋅gt因此如果要最大化 l o g [ C O R R ( L t ) ] log[CORR(L_t)] log[CORR(Lt)],那么向量 g t g_t gt 就需要与向量 M t M_t Mt 同向。如果再限定 g t g_t gt 为单位向量,那么最优主机表示 g t ∗ g_t^* gt∗ 就应该表示为: g t ∗ = M t ∣ M t ∣ g_t^* = \frac{M_t}{|M_t|} gt∗=∣Mt∣Mt
2.5 实验评估
-
实验设置
实现:
- 数据预处理器(Traffic Preprocessor)
使用TShark(3.2.5版本)对分片报文进行解析,然后恢复完整的通信。
- 图表示器(Graph Representor)
使用NetworkX(版本2.5.1)来构建异构图,并用Gensim(版本4.1.2)的文本表示来初始化节点
- 检测器(Detector)
scikit-learn(版本0.23.2)实现随机森林
基线模型:
- ETA[2]:采用随机森林模型检测恶意软件流量。具体来说,ETA利用了流的特性,包括TLS握手元数据、链接到加密流的DNS上下文流,以及5分钟窗口内来自同一源IP地址的HTTP上下文流的HTTP报头。
随机森林的参数设置为scikit-learn(版本0.23.2)中的默认参数。
- FS-Net[37]:是一个端到端的深度学习模型,采用多层编码器-解码器结构来挖掘流的潜在顺序特征。总之,它从原始流中学习代表性特征,然后对它们进行分类。
FS-Net,将隐藏状态维数设置为128,层数设置为2,长度嵌入维数设置为16。
实验环境和超参数设置:
- 环境:
在一台Supermicro服务器上运行这些方法,它有两个Intel Xeon E5-2690 cpu (2× 14核),Centos 7.9.2009, 345G内存。
- 超参数:
- 主机表示向量 D h D_h Dh 的维数为256
- 随机行走路径 P L P_L PL 的长度为100
- P N P_N PN 的路径数为10
- 控制返回概率的参数 p p p 设为1
- 控制探索新节点概率的参数 q q q 设为2
评估指标:
- 精度
- 召回率
- 假阳性率(FPR)
-
数据集
- 公共数据集AndMal2019
AndMal2019数据集包括5065个良性Android应用程序和426个恶意Android应用程序在真实智能设备上产生的流量和设备日志。恶意应用程序可分为39个家族。
- 私有数据集EncMal2021
我们收集的数据集EncMal2021是通过捕获示例生成的流量和校园网流量来构建的。它包含108,847个主机,5202,093个流,其中4.5%标记为恶意,其余标记为良性。
- 私有数据集EncMal2021收集方法:
恶意流量:我们使用恶意软件分析沙箱来收集数据。沙箱(包括Windows 7和Windows 10操作系统)允许用户提交恶意可执行示例,并根据可执行文件的执行情况控制运行时。恶意样本来自恶意软件分析网站VirusTotal和我们合作的大型安全公司,每天有数百万个样本更新。表1显示了恶意软件家族的名称和样本的数量。

每个示例平均运行5分钟,在此期间记录并保存所有生成的流量。由于沙盒中样本的大多数行为可以在前两分钟内观察到,我们认为5分钟是观察几乎所有有效行为的足够时间间隔。总的来说,我们最终从53111个样本中捕获了239007个流。在EncMal2021中,恶意样本在沙箱中运行,导致恶意流量的分布与实际情况不完全一致。但是,我们通过丰富恶意软件类型和沙盒环境来弥补这一点,以便构建的数据集尽可能全面。
正常流量:我们从两个数据源构建良性流量,一个是在校园网络中捕获的真实流量,另一个是在沙盒中运行的良性样本生成的流量。良性数据集中的大多数样本都是从拥有近10,000个活动主机的大型校园网中收集的。从2021年1月到2021年4月,我们连续5个月在不同时间点被动监控所有入站和出站加密流量,并保存原始pcap数据包。
由于校园网中存在恶意软件感染主机的可能性,我们不能将所有流量直接作为良性流量使用。我们选择Alexa排名作为过滤标准,保持流量排名前100万的域名。这样选择的原因是,在Alexa上排名超过100万的网站可以被认为是“长尾”,这样的过滤保证了样本的多样性,也在一定程度上保证了流量的良性。
由于爬取的流量可能包含一些私人信息,我们还需要匿名化ip。同一主机被视为同一个假IP,以保证网络关系的完整性。另一方面,为了避免良性流量和恶意流量由于采集方法不同而导致的域分布偏差较大,我们还采集了运行在同一沙箱环境下的良性样本产生的流量。这些样本部分来自微软商店免费软件榜单的前100名,部分来自恶意软件分析网站标记为良性的程序。在良性样本产生的所有流量域中,有24%不在Alexa Top 100万排名中。我们相信这在保持流量良性的同时减轻了与过滤流量相关的偏见。
最后,我们通过53,281个主机在现有网络中捕获4,940,593个流,并使用2,455个样本在沙盒中捕获22,493个流。- 训练集-测试集切分:
对于第一个任务,即恶意软件检测,我们对两个数据集执行不同的train-test split策略,因为这些数据集的容量不同。
- EncMal2021:
我们将收集到的数据集分为三部分:训练集、联合测试集、不联合测试集。比例为6:2:2。
(1)联合测试集与训练集共享相同的恶意软件家族分布;
(2)不联合测试集中的恶意软件家族与训练集中的恶意软件家族并不相交。
(3)我们随机分配良性流量,保持每个部分的良性流量与恶意流量的比例为10:1。 - AndMal2019:
我们使用60%的样本进行训练,40%用于测试。在这里,我们不进一步将测试集分为联合测试集和不联合测试集,因为AndMal2019只包含有限数量的恶意家族。
对于第二个任务,即恶意软件家族分类,我们使用8:2作为两个数据集的训练-测试分割的比例。
-
检测效果
第一个任务:恶意软件检测

第二个任务:恶意软件家族检测

-
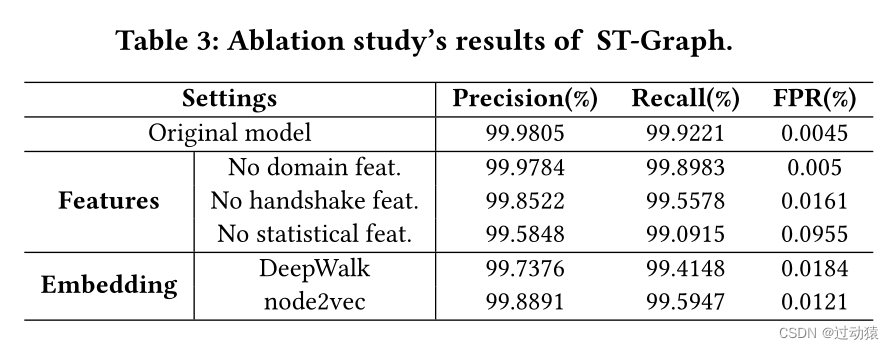
模型泛化能力(消融实验)
-
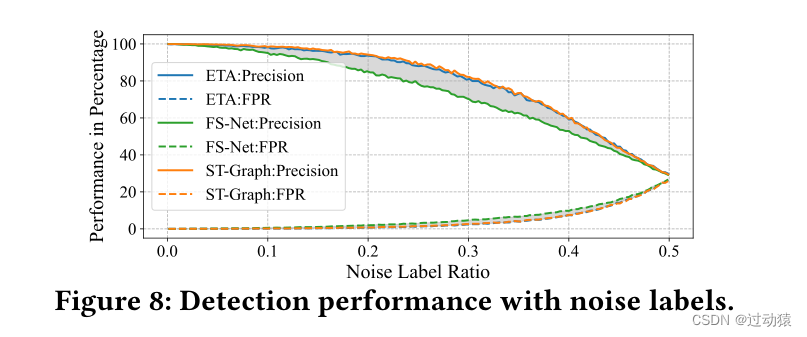
模型鲁棒性检测
-
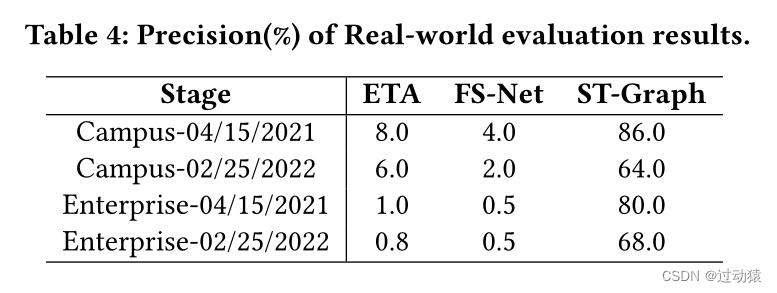
真实世界评估
总结
论文内容
-
学到的方法
理论上的方法:
- 图的随机游走可以综合图的时间和空间特征
- 得到主机的embedding后,还可以通过为embedding设置权重(与这个embedding相关的一些信息,softmax计算重要性。)
写论文的方法:
实验评估的写法:
- 实验设置:
- Implementation:核心方法实现的过程中用到的工具
- Baselines:基线模型,用于对比
- Environment and Parameters:实验环境和参数设置
- Metrics:评估指标
- 数据集:
- 数据集的介绍
- 数据集的收集方法
- 数据集的切分(训练集,测试集)
- 收集数据时涉及到的伦理问题
- 检测效果:
- 在不同数据集上,各种基线模型和提出模型在不同评估指标下的比较。
- 泛化能力(消融实验)
- 模型鲁棒性检测:加入噪声数据
- 真实世界评估
实验评估后面的内容:
- 讨论:模型局限性
-
论文优缺点
优点:
- 准确率高:提出了ST-Graph,从空间和时间角度探索多个特征,并集成所有可用信息,用于加密场景下的全面恶意软件流量检测。
- 实时性好:只通过迭代更新优化边表示来改进图表示的算法,而最优节点表示则来自封闭形式的解。这大大降低了图表示学习的计算复杂度;ST-Graph采用少量迭代的随机游走学习边嵌入,并采用封闭形式的解决方案优化主机嵌入。这大大降低了计算复杂度,满足了实时检测的需要。
- 能检测未知攻击
- 能实际应用
缺点:
- 集合 I I I(主机流的顺序)的元素要怎么表示,没有具体说明。
- 基线模型太少,说服力稍小一些。
- 网络规模。内部网络的规模对st图有影响。内部主机的增加会导致我们的图结构中有更多的节点和边。图中边的数量越多,检测的时间成本就越高,网关无法处理无限多的主机。
-
创新想法
可以不通过随机游走的方式来提取时空特征,而采用其他方法,如GCN等等。
工具
- Tshark:提取流量
- NetworkX来构建异构图
- Gensim的文本表示来初始化节点
数据集
- 公开数据集AndMal2019
- 私有数据集EncMal2021