目录
4.4 Prompt Augmentation with ChatGPT
4.5 LLMs Fine-Tuning for Graph Reasoning
4.7 LLMs Inference and Graph Reasoning Query Parsing, Execution and Post-Processing
论文链接:https://arxiv.org/pdf/2304.11116.pdf
摘要
本文旨在开发一种具有复杂图数据推理能力的大型语言模型(LLM)。目前,LLM 在各种自然语言学习任务中都取得了令人瞩目的成绩,其扩展功能还被应用于研究多模态数据的视觉任务。然而,当涉及图学习任务时,现有的 LLMs 在执行精确数学计算、多步骤逻辑推理、感知空间和拓扑因素以及处理时间进程方面存在固有的弱点,因而存在非常严重的缺陷。为了应对这些挑战,本文将研究赋予现有 LLMs 图推理能力的原理、方法和算法,这将对当前 LLMs 和图学习的研究产生巨大影响。受最新的 ChatGPT 和 Toolformer 模型的启发,我们提出了 Graph-ToolFormer(面向图形推理的 Toolformer)框架,通过 ChatGPT 增强的prompt来教 LLMs 自己使用外部图形推理 API 工具。具体来说,我们将在本文中研究如何教 Graph-ToolFormer 处理各种图数据推理任务,包括(1)非常基本的图数据加载和图属性推理任务,从简单的图顺序和大小到图直径和周边,以及(2)更高级的真实世界图数据推理任务,如书目论文引用网络、蛋白质分子图、顺序推荐系统、在线社交网络和知识图。
在技术上,为了构建 Graph-ToolFormer,我们建议分别为每个图形推理任务手工制作指令和少量prompt模板。通过上下文学习,基于这些指令和提示模板示例,我们采用 ChatGPT 对更大的图形推理语句数据集进行注释和增强,并调用最合适的外部 API 函数。这些增强的prompt语句数据集将通过选择性过滤进行后处理,并用于微调现有的预训练因果 LLM(如 GPT-J 和 LLaMA),教它们如何在输出生成中使用图形推理工具。为了证明 Graph-ToolFormer 的有效性,我们在各种图推理数据集和任务上进行了广泛的实验研究,并推出了具有各种图推理能力的 LLM 演示。Graph-ToolFormer 框架、图形推理演示以及图形和prompt数据集的所有源代码都已在项目的 github 页面上发布。
1 INTRODUCTION
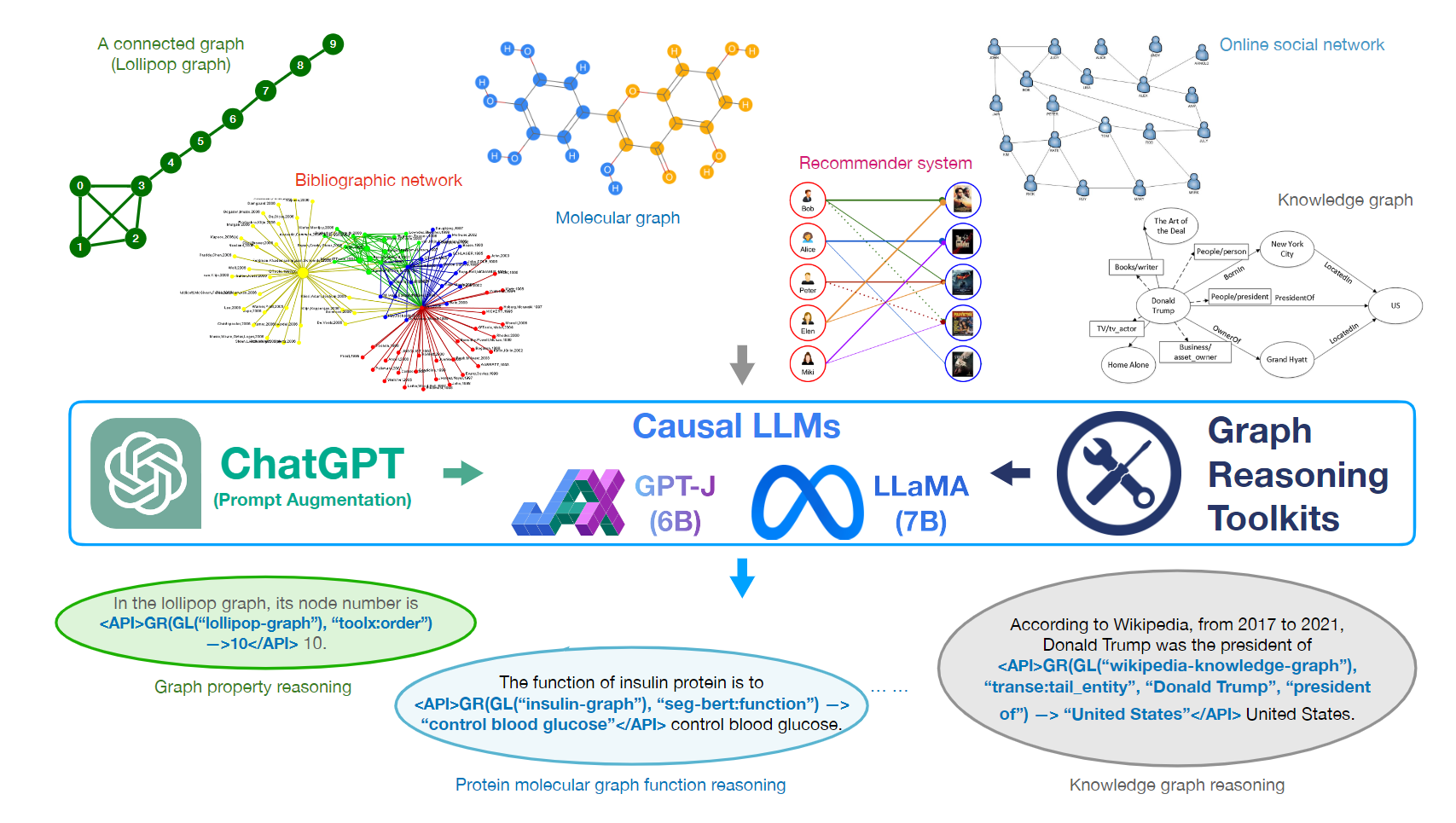
近年来,大型语言模型(LLMs)[8, 34, 50 ]在各种自然语言处理任务中取得了令人瞩目的成绩[32, 34, 49 ],其扩展部分也被广泛应用于解决其他许多不同模式数据的问题[10, 32, 40, 41 ]。随着基于 GPT-3.5 和 GPT-4 的 ChatGPT 和 Microsoft Bing Chat 的推出,LLM 也被广泛应用于人们的日常生产和生活中。与此同时,由于其固有的局限性,这些 LLMs 在使用过程中也受到了很多批评,比如无法进行精确计算 [36] 、难以解决多步逻辑推理问题 [6]、无法进行空间和拓扑推理 [1]、无法感知时间因素的进展 [9]。随着自然语言处理和计算机视觉的并行发展,基于transformer的图结构数据深度学习模型近年来也受到了社会各界的广泛关注[16 , 56, 60]。图为现实世界中许多相互连接的数据提供了一种统一的表示方法,它既能模拟节点的不同属性,又能模拟节点之间的密集连接。除了我们在离散数学和算法课程中学到的经典图结构(如图 1 所示),现实世界中的许多数据也可以用图建模[45],如书目网络[47]、原蛋白分子图[52]、推荐系统[28]、在线社交网络[31]和知识图[18]。
同时,与将视觉和语言数据纳入 LLM 以设计雄心勃勃的 AGI 发展计划的蓬勃研究探索相比[33],研究人员似乎 "无意 "或 "有意 "忽略了广泛存在的图形数据,而且似乎没有任何计划将其纳入为实现 AGI 而构建的 LLM 中。在这里,我们说研究人员 "无意 "忽略了图,因为与我们日常处理的文本和图像相比,图长期以来只是被用作现实世界数据的中间模型数据结构,我们通常不会与图进行直接交互。在创建 AIGC 和构建 AGI 系统的现阶段,人们自然会误以为图不应该是重点。与此同时,我们说研究人员可能“故意”忽略了图表因为图学习可能涉及(1)图属性的大量精确数学计算,(2)通过链接进行多跳逻辑推理,(3)捕获广泛连接的图空间和拓扑结构,以及(4)有时我们还需要处理随时间变化的动态图形。细心的读者可能已经注意到,图学习提到的这些要求实际上是一针见血的,这正好对应了我们一开始提到的当前LLM的弱点。
无论我们面临什么潜在挑战,“没有图形推理能力的 AGI 永远不会是我们想要的 AGI”。基于这样的动机,我们写了这篇论文,试图将图数据合并到LLM中,用于各种图推理任务。一方面,我们真心希望像OpenAI、微软、谷歌和Meta这样目前人工智能领先的公司在制定实现AGI的使命和计划时能够考虑到图结构化数据推理,以便图学习社区将能够与语言和视觉社区一起为构建AGI系统贡献我们的努力。另一方面,我们也希望使现有的LLM能够克服其在处理复杂图推理任务的图结构化数据时的性能弱点。
因此,最新开发的 LLM 也能为图学习社区解决各种图推理任务带来益处。考虑到当前的语言模型及其极高的预训练成本,我们不可能从根本上重新设计具有预训练功能的新 LLM,使其具备图推理能力。对于学术界的大多数研究小组和工业界的大多数公司来说,从头开始预训练这种 LLM 是一项不可行的任务。为了适应 NLP 方法的常见做法,我们将在本文中通过微调现有的一些预训练 LLM(如 GPT-J 或 LLaMA),引入面向图形推理的工具成型器框架(Graph-ToolFormer)。从技术上讲,如图 1 所示,基于 OpenAI 最新的 ChatGPT 和 Meta 的 Toolformer 模型[43 ],我们建议为现有的预训练 LLM(如 GPT-J 或 LLaMA)提供执行各种复杂图推理任务的能力,允许它们使用外部图学习工具,如其他预训练的图神经网络模型和现有的图推理工具包。为了使 Graph-ToolFormer 成为通用的图推理接口,我们将对 LLM 进行微调,让模型不仅能决定从哪里获取图数据,还能决定使用什么工具,以及何时和如何使用这些工具,而不是在推理语句中手动硬编码图数据加载和外部图学习工具使用函数调用。
有关 Graph-ToolFormer 模型的更多技术细节将在下面的方法论部分介绍。作为将 LLM 用于一般图形推理任务的首次探索尝试,我们将本文的贡献总结如下:
使用 LLM 进行图形推理: 本文是第一篇尝试提出通用 LLM(即 Graph-ToolFormer)的论文,它可以处理图形推理任务。它有效地弥补了现有图推理 LLM 的不足。更重要的是,它有助于将图学习社区与语言和视觉学习社区领导的 LLM 和 AIGC 的最新发展联系起来。因此,图学习社区的人们也将有舞台展示我们在当前 AIGC 时代和未来 AGI 时代的技能和专业知识。
- 图推理prompt数据集: 在本文中,我们创建了大量人类编写的语言指令和图学习工具如何使用的提示示例。在自监督上下文学习的基础上,我们使用 ChatGPT 对一个大型图推理数据集进行注释和扩充,其中包含不同外部图学习工具的 API 调用,这些 API 调用还将通过选择性过滤进行后处理。通过 github 页面1,我们向社区发布了本文中使用的图原始数据集和生成的图推理提示数据集,以供未来探索之用.
广泛的实验研究: 我们在现实世界中研究的各种基于图推理的应用任务中广泛测试了我们提出的 Graph-ToolFormer 的有效性,其中包括最基本的图数据加载和一般图属性计算任务,以及一些更高级的任务。具体来说,我们在实验中研究了几个具有挑战性的高级图推理任务,其中包括文献网络中的论文主题推理、分子图函数预测、在线社交网络社区检测、推荐系统中的个性化顺序推荐以及知识图实体和关系推理。
本文的其余部分组织如下。我们将在第 2 节中简要介绍相关工作。第 3 节将提供一些术语的定义和所研究问题的表述。第 4 节将提供有关 Graph-ToolFormer 框架的详细介绍。图的有效性-ToolFormer 将在第 5 节中对真实世界基准图数据集进行大量实验进行测试。最后,我们将在第 6 节中总结本文,并在第 7 节中简要讨论一些潜在的未来探索方向.
2 相关工作
在本节中,我们将讨论与本文提出的 Graph-ToolFormer 框架相关的几个研究课题,其中包括图神经网络、语言模型、基于语言模型的图学习和prompt调整。
2.1 Graph Neural Networks
图神经网络(GNN)旨在学习图结构数据的嵌入代表。已经提出的图神经网络的代表例子包括 GCN [19 ] 和 Graph-Bert [60 ],在此基础上还推出了各种扩展变体 [20, 46, 51 ]。如上所述,GCN 及其变体模式都基于近似图卷积算子 [13],这可能会导致深度模型架构的假死问题 [59] 和过度平滑问题 [ 23]。文献[12, 23, 59]对其原因进行了理论分析。为了处理这类问题,[ 59 ]对图原始残差项进行了概括,并提出了一种基于图残差学习的方法;[ 23 ]建议在 GCN 架构中采用残差/密集连接和扩张卷积。除了基于 GCN 和 Graph-Bert 的方法,[ 17 , 46 ]等其他一些研究也试图将循环网络用于深度图表示学习。
2.2 Language Models
自 Transformer [50 ] 提出以来,大型语言模型(LLM)已成为各种 NLP 任务的主流深度模型。在预训练的辅助下,科技巨头公司也推出了各自版本的不同 LLM,如谷歌的 BERT [ 8 ]、Meta 的 BART [22 ]、OpenAI 的 GPT [5 , 38 , 39 ]、AI2 的 ELMo [ 37 ] 和微软的 MT-DNN [25]。其中许多 LLM 也已开源,模型算法和学习参数都已发布到社区,用于研究和应用目的。与这项工作密切相关的一篇研究论文是 Meta 公司的 Toolformer [43],它建议将外部 API 纳入语言模型。有了这些外部 API,模型就能自动决定如何使用哪种工具。同时,甚至在 Toolformer 模型之前,其他几篇论文[29, 35]也曾探索过用外部工具来增强语言模型。
2.3 Prompt Tuning
事实证明,prompt可以有效地调整预训练的语言模型,实现零次或少量学习[5],与传统的微调任务相比,它可以帮助语言模型更快地学习。到目前为止,我们已经看到了三类prompt 调整方法,即离散提示[44]、连续提示[24]和引导[5]。离散prompt[44] 使用一些模板文本对数据实例进行重新格式化,例如、
![]()
离散提示通常会调整模型的所有参数。另一方面,连续提示[24]会在示例前预置特殊标记的嵌入向量,这只会更新小得多的模型参数集。与离散提示和连续提示截然不同的是,GPT-3 最初采用的 "引导"(priming)[ 5] 会在目标评估示例前预置几个引导示例,例如

根据[54]中报告的分析,离散提示在少样本调整中效果很好,连续提示尚未报告在少样本设置中成功,而启动成本非常高,并且似乎对于最大的 GPT- 3效果很好(175B)型号。
3 符号、术语定义和问题表述
在本节中,我们将首先介绍本文中使用的术语。之后,我们将提供几个常用术语的定义以及本文所研究的图推理任务的表述。
3.1 Basic Notations
在本文的后续部分中,我们将使用小写字母(例如 x)表示标量,小写粗体字母(例如 x)表示列向量,粗体大写字母(例如 X)表示矩阵,和大写书法字母(例如,)来表示集合或高阶张量。给定一个矩阵 X,我们将 X(i, :) 和 X(:, j) 分别表示为其 i 行和 j 列。矩阵 X 的 (i_th , j_th ) 项可以表示为 X(i, j)。我们用 X⊤ 和 x⊤ 来表示矩阵 X 和向量 x 的转置。对于向量 x,我们将其范数表示为
![]() 。矩阵 X 的弗罗贝尼乌斯范数表示为
。矩阵 X 的弗罗贝尼乌斯范数表示为![]() 。相同维度的向量 x 和 y 的逐元素乘积表示为 x ⊗ y,其串联表示为 x ⊔ y.
。相同维度的向量 x 和 y 的逐元素乘积表示为 x ⊗ y,其串联表示为 x ⊔ y.
3.2 术语定义
在本文中,我们将研究图结构化数据的推理任务。本文研究的图数据集都来自不同的领域,它们具有非常不同的结构并具有非常不同的属性。在本小节中,我们将提供本文研究的这些不同图结构数据的通用术语定义.
定义 1.(图): 一般来说,本文研究的图可以表示为 G= (V,E)。在表示法中,符号 V = {v1,v 2, - - - , } 表示图中的节点集, ![]() 表示这些节点之间的链接集,其中 |V | = n和 |E| = m通常也分别称为图的阶数和大小。
表示这些节点之间的链接集,其中 |V | = n和 |E| = m通常也分别称为图的阶数和大小。
根据应用领域的不同,要研究的图数据可能具有非常不同的属性和结构信息。对于某些图,节点可能带有一些特征和标签信息,可分别通过映射 : V → 和 : V →
来表示。对于每个节点
∈ V,我们可以用
![]() 表示其特征,用
表示其特征,用 ![]() 表示其标签向量,其中
表示其标签向量,其中 和
分别表示特征和标签空间维度。如果图 G, 中的链接也附有特征和标签,我们也可以用类似的方法表示链接 ,
∈ E 的相应特征和标签向量,分别表示为
和
![]() 。
。
对于书目网络、在线社交网络、推荐系统、知识图谱等多个领域的图数据,数据集中会存在一个单一的大规模图结构,但该图可能包含数千、数百万甚至数十亿个图结构。这种大规模图完全可以用上述定义来表示。与此同时,对于许多其他领域的图,比如我们在离散数学课程中学到的特殊图结构,以及生物化学分子图,数据集中会存在大量小得多的图实例,每个图实例通常包含几十或几百个节点和链接。为了区分这两类图结构数据,现有的一些工作[57]也将第一类图命名为巨型网络,将第二类图称为小型图实例集。同时,为了表示这类小型图实例集,我们引入了图集的概念,具体如下
定义 2(图集): 对于生成的特殊图实例(本文将介绍)和生化分子图实例,我们可以将这些数据集中的图实例集合表示为 G = {g1, g2, - - , },其中 G= (V , E ) 表示单个图实例,它可以根据上述图定义来表示![]()
对于某些应用领域,在上述图集中,每个图实例还可能有其独特的特征和标签信息,表示图实例的拓扑属性和标签。形式上,对于图集 G 中的图实例 ∈ G,我们可以将其原始特征和标签向量分别表示为 x∈ R 和 y∈ R 。
3.3 Problem Formulation
本文旨在增强现有预训练 LLM 执行图推理任务的能力。如前所述,本文研究的图推理任务包括:
(1)基本图属性推理;(2)书目论文主题推理;(3)生物化学分子图函数推理;(4)推荐系统序列推荐推理;(5)在线社交网络社区推理;(6)知识图实体和关系推理。
具体来说,本文研究的这些图推理任务都是经过精心挑选的,可以分为以下六类最基本的图学习问题:
- 属性计算: 对于基本图属性推理等任务,我们实际上是要计算输入图数据的显式或隐式属性,从简单的图中节点/链接数,到图半径和直径,以及更复杂的图外围和节点配对短路径长度。
节点分类: 在书目论文主题推理任务中,我们的目标是预测书目网络中学术论文的主题,这实际上可以建模为节点分类任务。通过论文节点及其邻近节点的原始特征,我们可以将论文分为不同的类别,这些类别与这些论文的特定主题相对应。
- 图分类: 对于生物化学分子图功能推理任务,我们的目标是根据分子图结构推断生物化学分子的潜在功能,这可以定义为图状态分类任务。通过分子图结构和原始属性,我们可以对图实例进行分类
链接预测: 对于顺序推荐系统的再推荐任务,我们的目标是根据用户与项目的历史交互记录,推断用户对系统中某些项目的潜在偏好,这可以定义为图学习中的链接预测任务(连接用户和项目)。根据推荐系统的设置,我们既可以预测表示用户是否会对项目感兴趣的链接存在标签,也可以推断表示用户会给项目打分的潜在链接权重。
- 图分割/聚类: 对于在线社交网络社区推理任务,我们的目标是推断在线社交网络的社区结构,这可以定义为图划分/聚类任务。根据用户的社交互动模式,我们希望将在线社交网络中的用户划分为不同的聚类,每个聚类表示一个由社交互动非常频繁的用户组成的社交社区。
图搜索:对于知识图谱推理任务,我们的目标是根据输入参数推断潜在的实体或关系,这可以建模为图搜索问题。从输入的实体或关系开始,我们的目标是扩展和搜索相关的实体或关系用于生成输出,可以有效保留输入所需的语义。
为了用一个 LLM 解决上述各种图形推理任务,我们建议将外部图形学习工具的 API 调用无缝地纳入图形推理语句。根据上述符号,我们将为现实世界中的不同图任务设计一套图推理 API 调用。这些 API 调用包括外部图学习工具的名称和参数,为了与普通文本区分开来,这些名称和参数都将用特殊符号包围。我们将利用 ChatGPT 生成一个包含此类 API 调用的大型语言建模提示数据集,用于微调 GPT-J 和 LLaMA 等 LLM。本文将研究的这些 LLM 都已经过预先训练,我们将仅使用生成的提示数据集对其进行微调。有关解决这些任务的技术细节的更多信息将在下面的方法论部分介绍。
4 PROPOSED METHOD
在本节中,我们将介绍本文提出的 Graph-ToolFormer 框架。首先,我们将在第 4.1 节中为读者简要介绍 Graph-ToolFormer 框架。之后,我们将在第 4.2 节中介绍图形推理 API 调用的一般表示方法,并在第 4.3 节中介绍面向具体图形推理任务的 API 调用。第 4.4 节将介绍如何使用 ChatGPT 来扩充提示数据集。第 4.5 节将详细介绍利用增强提示数据集进行语言模型微调的方法。同时,为了让 Graph-ToolFormer 也能处理一些基本的图形推理问答,我们还将在第 4.6 节中介绍一些图形推理问答提示,这些提示将被合并到语句提示中,用于 LLM 微调。最后,基于语言模型生成的带有 API 调用的输出语句,第 4.7 节将介绍面向 API 调用解析、执行、图任务推理和输出后处理的图推理任务。
4.1 Framework Outline
在图 2 中,我们提供了 Graph-ToolFormer 框架的大纲,说明了 Graph-ToolFormer 的内部功能组件和流水线。根据框架大纲,在手工编写的指令和少量提示示例的基础上,我们使用 ChatGPT 来注释和扩充一个有关图形推理 API 调用语句的大型提示数据集。利用生成的提示数据集,我们将对现有的预训练因果 LLM(如 GPT-J [11, 53] 和 LLaMA [ 49 ])进行微调,教它们如何使用外部图推理工具。利用LoRA(Low-Rank Adaptation)[15]和8位Adam以及模型量化技术[7],Graph-ToolFormer可以在内存空间非常小的GPU上进行微调,例如Nvidia GeForce RTX 4090(24GB RAM),甚至Nvidia GeForce RTX 1080Ti(11GB RAM)。经过微调的 Graph-ToolFormer 将用于推断目的。给定输入查询语句和问题后,Graph-ToolFormer 会在输出语句的最合适位置自动添加相应的图形推理 API 调用。下文各小节将详细介绍上述组件的详细信息以及构建 Graph-ToolFormer 的步骤。

4.2 Prompts with API Calls
在本文中,我们可以用f(args)来表示外部图学习工具的 API 调用,其中f是外部工具的函数名,args表示函数的参数列表。为简化表述,我们也可以用元组符号 c= ( f, args) 来表示这种 API 调用,这将在本文下文中经常使用。我们建议将 API 调用嵌入到生成的输出语句中,而不是仅仅将外部 API 调用作为输出,这样 LLM 就可以通过文本常规对话来处理和响应图推理任务。
要在输出语句中插入应用程序接口调用,我们可以将应用程序接口调用 c= ( f,args ) 的标记序列表示为
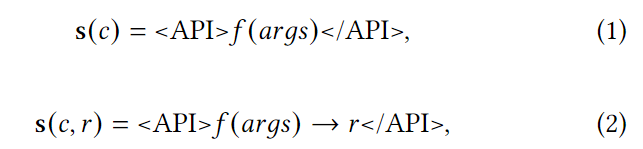
其中围绕 API 调用函数的"<API>"和"</API>"都是特殊标记,用于将其与生成的输出语句中的其他token区分开来。对于 Graph-ToolFormer 框架来说,当它生成"<API>"和"</API>"标记时、框架解析器会识别出其中的token表示 API 函数调用。至于第二个 API 调用表示法,该符号r表示f(args)的返回结果。对于token为"→r"的 API 调用,Graph-ToolFormer 也会在查询解析和执行后将 API 调用结果替换并插入到语句中;否则,API 调用将在后端执行,返回结果将被记录到工作内存中。有关输出语句 API 调用解析、执行和后处理的详细信息将在第 4.7 节中介绍。根据推理任务中 API 调用的函数f(args)和上下文,稍后微调的 LLM 将自动决定是否将输出结果插入输出语句中.
与[43]中研究的非常简单的API调用(如 "日历"、"计算器 "和 "维基搜索")不同,在图推理中,一些API调用可能涉及对各种外部函数的复杂嵌套调用。例如,一个 API 调用中的某些参数实际上可能是其他 API 调用的返回结果,或者我们可能需要同时调用多个连续的 API 来完成一个图形推理任务。在下文第 4.3 节讨论具体的图形推理任务时,我们会遇到一些这样复杂的图形推理 API 调用.
为了解决此类复杂的图形推理任务,本文还将允许 Graph-ToolFormer 生成嵌套和连续的 API 调用,这些 API 调用由特殊标记"<API>"和"</API>"包围。例如,给定的两个 API 调用 c1 = (f1, args1) 和 c2 = (f2, args2) 都有各自的输入参数,第一个 API 函数 f1 需要使用第二个 API 函数 f2 的返回结果作为其输入参数,我们可以将这种嵌套的 API 调用表示为
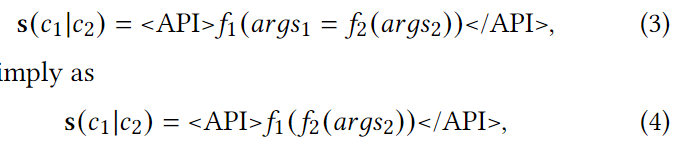
其中符号“c1 |c2”表示这两个 API 调用是嵌套的.
同时,如果一个任务需要同时调用多个连续的应用程序接口,例如 c1 = (f1, args1) 和 c2 = (f2, args2),我们可以将这种连续的应用程序接口调用表示为
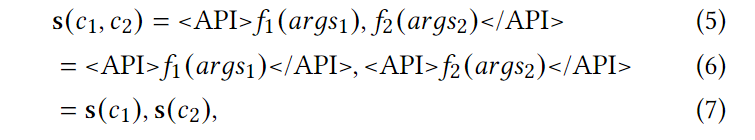
同时,对于一些更复杂的图形推理情况,我们可以使用其他 API 调用表示的更多输入参数或深度嵌套的 API 调用来重写上述 API 调用表示,例如

这样的图推理函数 API 调用将被插入语句中,供 LLMs 日后微调使用。在不修改 LLMs 词汇集和预先训练好的标记符号生成器的情况下,我们可以用一些不常用的标记符号(如"["、"]"和"->")来代替特殊标记符号"<API>"、"</API>"和"→"。
在本文中,我们将研究几种非常不同的图推理任务,涉及不同的图学习 API 调用,这些任务将在下面的小节中为读者详细介绍.
4.3图推理为导向的提示
我们将在本文中使用 Graph-ToolFormer 研究几个图推理任务,其中包括非常基本的任务(例如一般图属性推理)和更高级的任务(例如来自不同特定应用领域的图的推理任务)。正如之前在第3节中介绍的,本文研究的这些图推理任务都是经过精心挑选的,可以分为不同类型的基本图学习任务,例如图属性计算、节点分类、图分类、链接预测、图分区/聚类和图搜索。所有这些基本的图学习任务在现实世界的图数据推理任务中都有广泛的应用。除了本文研究的任务外,通过对 API 调用进行微小的更改,我们还可以将 Graph-ToolFormer 应用于其他与图推理相关的应用任务.
4.3.1 图形数据加载
与文本和图像不同,现实世界中的图数据可能具有相对较大的规模、广泛连接的结构和复杂的原始属性。除了一些小型的手工制作的图形示例之外,几乎不可能手动将图结构数据作为标记序列输入给 LLM 进行推理。因此,在本文中,我们建议赋予 Graph-ToolFormer 模型基于提供的数据集名称、本地文件路径或在线存储库 URL 链接自动从离线文件或在线存储库加载所需图形数据的能力。从技术上讲,我们在本文中介绍的第一个 API 调用是用于图数据加载的,它可以加载整个图,也可以仅加载涉及一个或几个节点和链接的子图。
![]()
其中"GL() "表示 "图形加载 "函数名称的缩写,函数参数 "文件路径"、"节点子集 "和 "链接子集 "分别指定本地图形数据文件路径(如果数据存储在网络上,则指定在线存储库 URL)、特定节点子集和链接子集。符号"→G"明确表示加载的图形数据与参考变量 G= (V,E),这实际上是可选的,取决于应用任务和设置。此外,如果"GL() "函数已经预先提供了本地文件目录或在线资源库根 URL,那么在调用此 API 函数时,我们只需将 "文件路径 "简化为具体的 "图形名称 "即可。
此外,如果省略参数 "节点子集"(node-subset)和 "链接子集"(link-subset),或者分别指定为 "所有节点 "和 "所有链接",那么 API 函数调用将直接加载整个图。在某些情况下,我们只能指定要加载的节点子集(如图中的 { vi,vj , - - , v,k} ⊂ V),但无法枚举所有相关链接,这时我们可以将 "节点子集 "和 "链接子集 "参数分别赋值为"{ vi,vj , - - , vk}"和 "所有相关链接"(或省略 "链接子集 "参数)。这将为我们根据所提供的节点集及其内部链接加载子图提供更大的灵活性。同样,我们也可以只指定链接子集,通过将 "节点子集 "指定为 "所有相关节点 "或省略该参数,它将自动加载图数据中构成所提供链接的节点,如表 1 中所示的第二个图数据加载提示示例。除了这个示例(如表 1 顶部所示),我们还提供了其他一些图形数据加载 API 调用的提示示例,它们可以根据输入的文本语句从(本地)文件中检索和加载所请求的图形数据。
4.3.2 图属性推理。
图结构化数据可能具有各种属性,如直径、密度、中心和最短路径等,这些属性可以捕捉图数据的不同特征,在现实世界的图结构化数据中有着广泛的应用。要推理这类图属性,通常要求模型不仅要知道属性定义,还要有很强的逻辑推理和数学计算能力来计算这类属性。对于现有的语言模型,无论是掩码语言模型还是自回归语言模型,都很难以(几乎不可能)根据输入图进行如此复杂的属性推理过程。
在本文中,为了使 LLM 具备图属性推理能力,我们引入了一组外部 API,语言模型可以调用这些 API 对这些属性进行推理。为了说明 Graph-ToolFormer 是如何处理此类图属性推理任务的,我们将以图 1 中所示的小型棒棒糖图(左上角的绿色图)为例进行说明。
![]()
其中加载的图也可以用符号 Gl. 为简单起见,在下面的部分中,我们还将以上述加载的棒棒糖图为例,向读者介绍图属性推理 API
顺序和大小
从形式上看,给定一个图,如加载的棒棒糖图G = (V,E),其顺序表示图中节点的数量,即 |V|,其大小表示图中链接的数量,即 |E|。我们可以将推理棒棒糖图的阶数和大小属性的 API 调用表示为
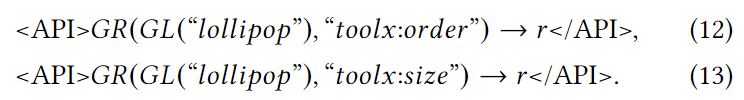
如果已通过其他应用程序接口调用预加载了棒棒糖图,则可将其称为 Gl,上述应用程序接口调用也可简化如下
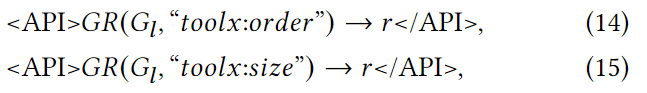
其中,符号GR()表示 "图形推理 "函数名称的缩写,参数 "order "和 "size "表示要推理的图形属性。toolx : desired_property "表示使用 toolx 工具包推理所需的图形属性。toolx 是本文基于 networkx 为 Graph-ToolFormer 创建的图属性计算工具包,我们将在下一个实验部分介绍本文使用的图推理模型和工具包的更多信息。符号"→"表示图属性推理 API 调用的输出结果将包含在输出语句中。如前所述,API 调用的返回输出结果标记"→"实际上是可选的,是否包含取决于推理上下文和应用任务。
密度:
图密度表示图中现有链接数与图中节点间潜在链接数之比。如果输入的棒棒糖图 G= (V, E) 是有向图,其密度可表示为![]() ;如果是无向图,其密度可表示为
;如果是无向图,其密度可表示为 ![]() 。计算图密度的 API 调用形式如下
。计算图密度的 API 调用形式如下
![]()
其中布尔参数 "is -directed(有向)"在密度计算中区分了有向图和无向图。
最短路径
图中两个节点之间的最短路径是通过图中的节点和链接连接它们的长度最短的路径。图中从 1 到 2 的最短路径长度的推理 API 调用可以表示为
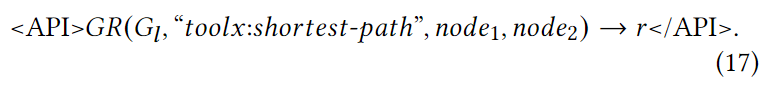
同时,图中所有节点的最短路径平均长度可通过以下应用程序接口调用获得
![]()
除了平均最短路径长度之外,我们还可以推理出图的最大最短路径长度和最小最短路径长度,如下所示
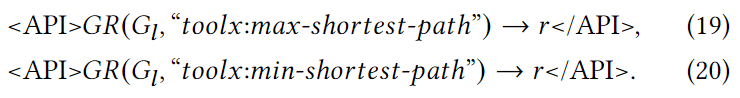
偏心率
给定一个连通图,如棒棒糖图G = (V,E),对于节点vi ∈ V,其偏心率表示与图中任何其他节点vj ∈ V 之间的最大图距。根据这一定义,对于断开的图,所有节点都被定义为具有无限偏心率。我们可以通过以下两个 API 调用计算整个图(即图中的所有节点)或特定节点的偏心率:
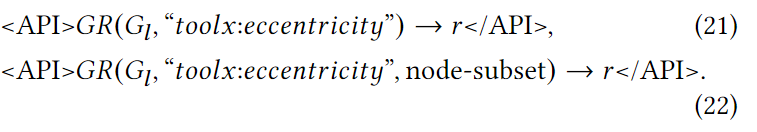
基本图形推理 API 调用摘要: 根据我们上面的描述,读者应该已经注意到这些图属性可能需要非常复杂的逻辑推理。通过一些初步的实验测试,目前的 LLM(如 ChatGPT 和 LLaMA)无法很好地处理它们。同时,上述推理属性(如最短路径)在现实世界的图推理任务(如交通网络推理和交通路线规划)中也有非常广泛的应用。目前,由于 LLM 无法为空间交通数据提供正确的推理结果(如估算不同地点之间的行车距离和时间),因此一直备受诟病。有了上述基于交通网络属性的最短路径 API 调用,我们就能为 LLM 处理此类查询提供更精确的推理结果。为了将其纳入语言模型,我们还在表 1 中展示了上述 API 调用的一些示例,这些示例可以从指定数据源加载图数据,并对上文讨论的一些通用图属性进行推理
4.3.3 高级图推理任务。
除了基本的图属性推理任务外,本文还将研究几种结构更为复杂的真实世界图数据高级推理任务,其中包括:(1) 基于书目网络的学术论文主题推理;(2) 基于蛋白质图结构的蛋白质函数推理;(2) 基于推荐系统的顺序产品推荐推理;(4) 基于在线社交网络的社交社区推理;(5) 基于知识图的语义推理。对于本文未研究的许多其他高级图推理任务,只需对 Graph-ToolFormer 框架稍作改动,就能通过在推理提示中添加相应的 API 调用,将它们有效地整合到 Graph- ToolFormer 中。Graph-ToolFormer 框架可以作为承载以 LLM 为通用接口的各种图形推理应用任务的骨干。在第 7 节中,我们还将在本文最后为读者介绍一些潜在的未来研究机会。
书目论文主题推理:
书目网络[47]定义了一种复杂的图结构数据,其中涉及各种实体,如学术论文、作者、机构和出版地,以及这些实体之间的各种链接,如引文链接、作者链接、隶属关系链接和出版链接。本部分将讨论基于书目网络的学术论文主题推理任务。一篇论文的主题不仅可以通过其自身的文本描述来推断,还可以通过被其引用/引用的其他论文来推断,这就要求图推理模型既要利用论文的原始文本特征,又要利用论文之间广泛的引文链接。从形式上看,根据前面第 3.2 节中提供的术语定义,我们可以将书目网络表示为 = (V,E),可以通过应用程序接口 调用 进行加载
![]()
每篇论文在书目网络中被表示为一个节点vi∈V,它有原始特征向量 x 和标签向量 y。原始特征向量包括论文的文本信息(如标题或摘要),标签向量表示论文的主题。现有的图神经网络(GNN)通过学习原始特征和连接邻域信息的表征来推断论文主题[19 , 60],这些信息可进一步用于推断主题标签向量。对于本文介绍的 Graph- ToolFormer 模型,我们将使用预先训练好的 Graph-Bert [ 60 ] 作为书目网络的默认主题推断模型。根据上述描述,我们可以通过以下 API 调用通过图神经网络模型来表示论文主题推理:
![]()
函数符号![]() 表示这是一个采用 Graph-Bert 模型[60]的论文主题推理应用程序接口。实际上,本文提出的 Graph-ToolFormer 框架是一个通用框架。除 Graph-Bert 模型外,许多其他现有的图神经网络模型也可用于学术论文主题推理。根据所提供的源代码,读者可以对 Graph-ToolFormer 进行定制,包括更多不同的图模型可用于完成自己的图推理任务。
表示这是一个采用 Graph-Bert 模型[60]的论文主题推理应用程序接口。实际上,本文提出的 Graph-ToolFormer 框架是一个通用框架。除 Graph-Bert 模型外,许多其他现有的图神经网络模型也可用于学术论文主题推理。根据所提供的源代码,读者可以对 Graph-ToolFormer 进行定制,包括更多不同的图模型可用于完成自己的图推理任务。
蛋白质分子功能推理: 蛋白质和化学分子功能推理[52] 是生物化学研究领域几十年来一直在研究的经典问题,在现实世界中具有重要的应用价值,如帮助设计一些新药来治疗现有的一些罕见疾病。蛋白质功能推断并非易事,因为同源蛋白质往往同时具有几种不同的功能。此外,这种预测需要对某些突变进行微调,但对其他突变则要稳健。研究人员一直在利用机器学习模型对这一问题进行探索,并且已经开发了一个相对庞大的蛋白质功能数据库[ 48 ]。然而,与现实世界中存在的蛋白质数量相比,数据库中包含的已知功能的特定蛋白质仍然非常有限。在图学习中,根据蛋白质分子的结构推断其功能也得到了广泛的研究。因此,在本部分中,我们也将其作为图推理任务纳入 Graph-ToolFormer 中。
与书目网络不同,蛋白质分子图的尺寸要小得多,并且数据集中也会存在多个这样的图实例。更重要的是,蛋白质分子图的特征和标签都是关于整个分子图,而不再是关于单个节点。正如 3.2 节中介绍的,我们可以将研究的蛋白质分子图集表示为 G = {g1, g2, · · · , },可以通过以下图加载 API 调用来加载它
![]()
对于数据集 G 中的每个分子图实例G = (V , E ),还会有与每个蛋白质分子图实例相关的原始特征和标签。例如,对于图实例gi ∈ G,我们可以用 x 表示其原始特征,用 y 表示其标签,其中标签向量将表示其对应的函数。根据蛋白质图结构及其原始特征,我们可以定义以下用于蛋白质分子函数推理的 API 调用:
![]()
这将称为[ 58 ]中提出的预训练图神经网络 SEG-Bert。SEG-Bert 的全称是 "Segmented Graph- Bert"[ 58 ],它扩展了用于分子图表征学习的 Graph-Bert 模型。除了 Graph-ToolFormer 中使用的 SEG-Bert 模型之外,读者还可以定制 Graph- ToolFormer 框架,将其他图模型也纳入其中,以解决分子图推理任务。
顺序推荐系统推理: 在大数据时代,随着越来越多的在线和离线数据产生,从这些大数据源中手动搜索信息已变得不可行,我们可能需要推荐系统[28 ]来自动为我们推荐所需的信息。基于历史记录,顺序推荐系统旨在推断出用户可能感兴趣的下一个(或多个)项目,这可能会导致用户未来的购买行为或这些项目的评论评分得分。
4.4 Prompt Augmentation with ChatGPT
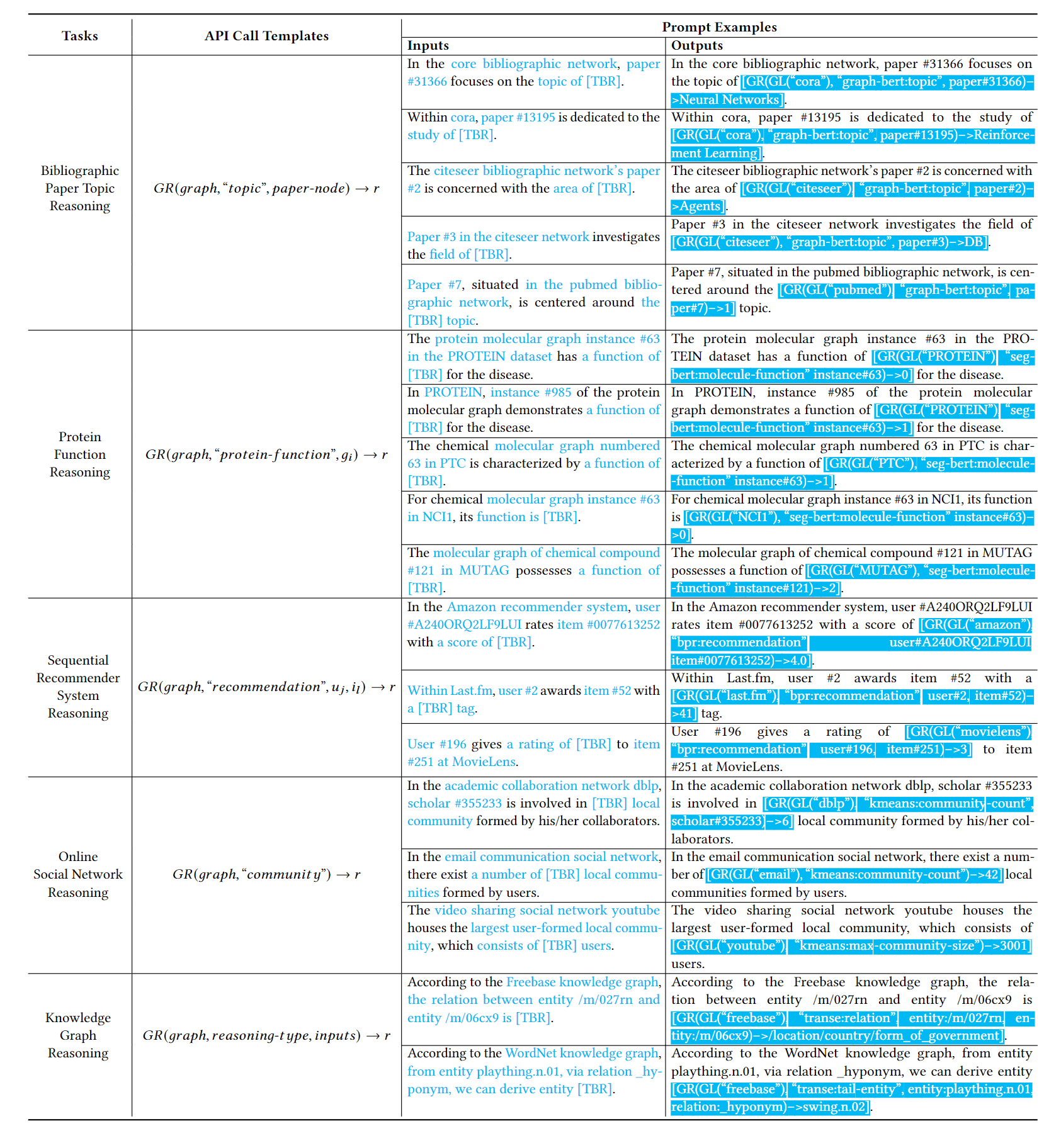
对于表1和表2中提供的提示示例,它们只能涵盖有关如何使用API调用来执行不同图形推理任务的少数示例。如此少量的实例不足以对现有的LLM 进行微调。在本文中,我们建议使用 ChatGPT (gpt-3.5-turbo) 来增强提示实例,它已经在许多不同的语言学习任务中表现出了出色的少样本和零样本上下文学习能力 [5]
4.4.1 图形加载提示数据集生成。
与[34]类似,为了帮助生成提示示例,我们还为ChatGPT提供了详细的说明以指定其系统角色。这里,我们可以以图数据加载API调用为例。提供给 ChatGPT 的说明和prompt示例如下。根据指令和提示示例,我们将要求 ChatGPT 生成图数据加载prompt数据集.
指令: 您的任务是在一段内置文本中添加图形加载函数的 API 调用,以实现具体的图形数据加载。该函数应有助于根据提及的图形名称及其节点和链接加载所需的图形结构化数据。您可以通过写入"[GL(graph-name, nodes, links)]"来调用图形加载 API,其中 "graph-name "表示目标图数据,“节点”和“链接”是提到的节点和链接。如果未提及特定节点或链接,则 API 将为“节点”和“链接”参数写入“所有节点”和“所有链接”。如果仅指定节点,API 将在“nodes”参数条目中列出提到的节点,并在“links”参数条目中写入“所有相关链接”。如果仅指定链接,则 API 将为“nodes”参数条目写入“所有相关节点”,并为“links”参数条目列出提到的链接。下面是一些加载图形结构化数据的 API 调用示例。在这些示例中,输出将重复输入,并在最合适的位置插入 API 调用。
输入:苯环分子图的结构苯环含有六边形。
• 输出:苯环的[GL(“苯环”)]分子图的结构包含一个六边形。
• 输入:乙醛分子图中存在碳-氧双键。
• 输出:乙醛分子图中存在[GL("乙醛-分子-图", {碳, 氧}, {(碳, 氧)})] 碳-氧双键。
• 输入:棒棒糖图看起来像勺子。
• 输出:[GL("lollipop-graph", "all Node", "all links")] lollipop 图看起来像一把勺子。
• 输入:Cora 书目网络中的第 10 篇论文介绍了 Transformer 模型。 • 输出:参考书目网络中的[GL("cora", {Paper#10}, "all related cite links")] paper#10 介绍了Transformer 模型。
• 输入:胰岛素是一种小球状蛋白质,含有两条长氨基酸链。
• 输出:[GL(“胰岛素-蛋白质-图”,“所有原子节点”,“所有原子键链接”)] 胰岛素是一种小球状蛋白质,含有两条长氨基酸链
输入:在 IMDB 推荐系统中,David 对《复仇者联盟》电影的评分为 10 星。
• 输出:在 [GL("imdb-recommender-system", {"David", "The Avengers"}, {("David", "The Avengers")})] IMDB 推荐系统中,David 对《复仇者联盟》电影评分为10星。
• 输入:在现有的在线社交应用中,Tiktok 让用户可以轻松地通过直播视频进行在线社交。
• 输出:现有在线社交应用中,[GL(“tiktok-social-network”,“所有用户和视频节点”,“所有用户-视频链接和用户-用户链接”)] Tiktok 使用户可以轻松地通过直播视频在线社交。
• 输入:根据Freebase 知识图谱,唐纳德·特朗普于1946 年出生于纽约牙买加医院医疗中心。
• 输出:根据 [GL("freebase", {"Donald Trump", "Jamaica Hospital Medical Center", "New York"}, {("Donald Trump", "Jamaica Hospital Medical Center"), ( 《牙买加医院医疗中心》、《纽约》)})】Freebase知识图谱,唐纳德·特朗普1946年出生于纽约牙买加医院医疗中心。
查询:根据说明和示例,请生成 5000 个这样的输入输出对,用于现实世界的图形数据加载。请确保加载的数据位于图形结构中,并且 API 调用插入到提到的图或提到的节点或链接之前。
根据说明、示例和查询,通过调用 Chat- GPT API,我们获得了一个包含 5 000 个输入输出对实例的提示数据集。经过人工删除不完整实例和简单校对,数据集中保留了约 2 803 个图形数据加载 API 调用的输入输出对,这些数据将用于稍后介绍的微调。
4.4.2 图推理提示数据集生成。
对于其他图形推理提示,通过类似的指令和提示示例,我们可以使用ChatGPT生成大量类似的输入输出对。同时,与图加载API调用略有不同,为了确保图推理提示有效,我们建议通过提前调用图推理工具包来手动编写所有输入语句。例如,对于 Cora 书目网络中论文,其主题是 "神经网络",我们将对其输入语句进行如下编排:
输入: Cora 中的第一篇论文的主题是神经网络。
我们会将此类输入提供给 ChatGPT,并要求它帮助将图形推理 API 调用插入到带有查询的语句中。
查询:根据说明和示例,通过对输入的图形推理 API 调用生成输出。请确保API调用插入在最合适的位置
根据查询和输入语句,ChatGPT 将返回以下输出:
• 输出:Cora 中的第一篇论文的主题为 [GR(GL("cora", "all paper nodes","all citation links"), "topic", {Paper#1})神经网络。
除了使用 ChatGPT 对 API 调用进行注释并生成上述输出之外,我们还使用 ChatGPT 在不改变语义的情况下以另一种方式重写了输入语句。例如,对于上图所示的输入语句,我们还得到了如下几个重写版本:
输入: Cora 中的第一篇文章以神经网络为主题。
- 输入: Cora 中的首篇论文以神经网络为主题。
- 输入: Cora 专辑中最重要的论文涉及神经网络领域。
- 输入: Cora 的创刊号以神经网络为主题。
这些经过重新措辞的输入也将再次输入 ChatGPT,用于 API 调用注释。这一过程将针对基本图属性推理任务和高级图推理任务中研究的所有节点/图实例进行,以生成输入输出prompt对数据集。根据生成的数据集,我们将运行 ChatGPT 生成的 API 调用,并将图推理 API 函数的返回结果与语句中的真值进行比较。对于 (1) 无法运行 API 调用或 (2) 无法返回正确结果的输出,将从数据集中过滤掉。最后,过滤后的 ChatGPT 增强生成数据集将用于 LLMs 微调,其统计信息将在后面的实验部分提供。同时,对于本文未研究的其他图推理任务,其推理 API 调用数据集的生成方法与上述类似
4.5 LLMs Fine-Tuning for Graph Reasoning
基于上述增强型图形推理提示数据集,我们将在本部分介绍如何对现有的预训练 LLM 进行微调,以便 LLM 可以学习如何使用 API 工具来处理图推理任务。从形式上看,如表 1 和表 2 中的提示示例所示,给定带有标记序列(即 ![]() )的输入语句,Graph-ToolFormer 中的 LLMs 的目标是找出插入 API 调用的最合适位置,即前面第 4.2 节中介绍的
)的输入语句,Graph-ToolFormer 中的 LLMs 的目标是找出插入 API 调用的最合适位置,即前面第 4.2 节中介绍的![]() 。主要挑战在于:(1) 精确确定插入 API 调用的最合适位置;(2) 正确选择用于调用的 API 函数;(3) 从上下文中精确提取参数并将其输入函数。在本节中,我们将解决所有这三个难题。
。主要挑战在于:(1) 精确确定插入 API 调用的最合适位置;(2) 正确选择用于调用的 API 函数;(3) 从上下文中精确提取参数并将其输入函数。在本节中,我们将解决所有这三个难题。
4.5.1 API 调用插入位置预测。
对于所提供的输入语句,可能存在多个插入 API 调用的潜在位置。与 [43 ]选择前 k 个位置生成 API 调用数据不同,本文旨在确定最有可能插入 API 调用的位置。从形式上看,基于预先训练好的语言模型,给定输入语句 w = [w1, w2, - - - , ],我们可以在 括号(其中i∈ {1, 2, - - - , n})位置(即标记wi-1 和 )之间插入 API 调用,概率为
![]()
一旦 LLM 在 氛围位置生成了特殊的开头标记 <API>,模型就会知道它应该在这里插入一个 API 调用。在 <API> 标记之后、特殊结束标记 </API> 之前生成的所有标记都将是 API 调用函数名或输入参数。对于具有最新概率的位置索引,![]() ,它将被选为插入 API 调用的最合适位置。
,它将被选为插入 API 调用的最合适位置。
4.5.2 API 调用域和函数选择。
与[43]中研究的极少数 API 调用函数不同,本文研究的图推理 API 更加多样化,这可能会给框架的实现和调整带来挑战。一方面,随着更多的图形推理任务和 API 函数被纳入 LLM 的调优,图形推理 API 函数的搜索空间将呈指数级增长,这就增加了选择正确和最佳 API 函数进行调用的难度。另一方面,不同图形推理任务的某些 API 函数甚至可能共享相似的函数名,这可能会误导 Graph-ToolFormer 在 API 调用中选择正确的函数。此外,不同的图形推理任务可能会调用不同工具包中的不同 API 函数,有些任务可能需要在后端预加载不同的图形函数和训练有素的模型。我们可能还希望在 API 调用中指定要加载的训练有素的图模型和图工具包,这样 Graph-ToolFormer 就可以在生成阶段提前预加载模型和工具包,从而降低整个图推理的时间成本。因此,根据前面展示的图推理 API 调用示例,我们建议对第 4.2 节中介绍的图推理 API 调用模板稍作修改如下:
![]()
![]()
其中,API 函数的相应 "域 "是 API 函数调用中特定图形推理任务的前缀。域可以是所使用的工具包名称,也可以是预先训练好的特定模型名称。例如,在表 1 和表 2 所示的图推理 API 调用中,我们将使用本文基于 networkx toolkit2 开发的 toolx 进行图属性推理,可将相应参数表示为 "toolx:property-names";至于使用 Graph-Bert 进行主题推理的文献[60 ],我们可将相应参数表示为 "graph-bert:topic"。在其他一些情况下,如果没有指定域,我们将直接使用默认域中的函数来完成图推理任务。关于在 API 调用中定义 "domain:function "条目所使用的预训练图模型的更多信息,将在下文第 5 节中提供给读者。
换句话说,在语句中插入 API 函数调用时,我们需要同时推断出 API 调用的域和函数名。在推理阶段,当 LLM 生成域时,系统甚至可以在整个 API 调用输出语句生成完成之前,在后端预加载域代码。同时,它还能让 LLMs 选择在 API 调用中使用的最佳域,因为要完成相同的图推理任务,会存在几种不同的方法,它们在效果和效率方面的表现也各不相同。
4.7 LLMs Inference and Graph Reasoning Query Parsing, Execution and Post-Processing
最后,在本节的最后,我们将详细介绍如何使用 Graph-ToolFormer 中经过微调的 LLMs 来处理各种图形推理任务。如图 3 所示,基于多个功能模块的图推理过程有几个重要步骤,包括:(1)基于 LLMs 的输出查询语句生成;(2)查询提取和解析;(3)查询执行;(4)图数据中心;(5)图模型中心;(6)图任务中心;(7)工作存储器;(8)推理输出后处理。在本小节中,我们将为读者介绍这些步骤以及 Graph-ToolFormer 中使用的相关功能模块/中枢。
4.7.1 LLMs 推理。
基于提示数据集,我们已经在前面的小节中讨论了如何在 Graph-ToolFormer 中对 LLMs 进行微调,它能够为输入的状态元素生成图推理查询语句输出。在应用经过微调的 LLMs 进行推理时,给定任何图形推理输入语句,LLMs 都会将输入语句投射到相应的输出语句上,并用 API 调用进行注释。我们还提供了一个推理过程示例如下

同时,通过将基于问答的提示数据集纳入 LLMs 微调,Graph-ToolFormer 还能为输入的问题查询生成图推理语句,例如

对于绝大多数图形推理输入语句和问题,Graph-ToolFormer 中的 LLM 可以在输出的正确位置添加正确的图形推理 API 调用(我们将在下文第 5 节中说明实验结果)。这些生成的带有 API 调用的输出语句将被送入下面的解析器模块,以提取图形推理查询。
4.7.2 查询解析器模块。
由于 Graph-ToolFormer 允许嵌套和顺序 API 调用,因此解析 LLM 生成的输出图推理查询绝非易事。在这里,我们可以将输出查询“[GR(GL("cora"),"graph-bert:topic",{Paper#1})–
>r]以上小节介绍的 LLM 生成的查询为例。Graph-ToolFormer 框架引入了一个查询解析器模块,该模块能够识别查询并将其解析为执行器模块可识别和执行的标准格式。查询的预期解析结果将包括两个部分
函数调用解析: 为了区分语句中的普通文本查询和图形推理 API 调用查询,我们将使用正则表达式来识别和解析查询。使用以下 python 正则表达式可以有效识别查询的函数调用部分
![]()
将检测 API GR/GL 函数标记以及 API 调用中的参数。对于 API 调用中的参数,如果我们发现存在任何嵌套 API 调用(通过检测括号标记(和)),我们将递归解析嵌套 API 调用
输出插入解析: 输出插入标记"->r "的提取将更加容易,这也可以通过正则表达式来识别,即

对于本文研究的 API 调用,如果存在"->r "标签,我们将替换查询文本,将图形推理结果插入原文中;否则,查询将仅在后台执行,其结果将记录在工作存储器中,稍后再引入。
例如,对于由 LLM 生成的示例查询"[GR(GL("cora"), "graph-bert:topic",{Paper#1})- >r]",其嵌套解析结果可由 Graph-ToolFormer 框架中的查询解析器模块表示为"((GR, [(GL, ["cora"]), "graph-bert: topic", {Paper#1}]), [True])",其中 "True "标记表示存在输出插入标记"->r",即"->r"。 e., 我们需要在输出语句中用推理结果替换查询文本
4.7.3 图形推理中心。
在对解析查询进行推理之前,所有图形加载和推理 API 工具包和模型都将预先加载并随时可用。此外,所有要加载的图数据都将被组织成统一格式,以便图加载 API 函数能够处理。具体来说,我们在 Graph-ToolFormer 框架中引入了几个中心,分别承载各种图数据集、预训练图模型和图推理任务。
图形数据集中心: 将在 Graph-ToolFormer 框架中使用的一组预处理图形数据集将被组织到图形数据集中心。所有这些数据集都将采用统一的格式,并允许 Graph- ToolFormer 框架和预训练的图形模型在推理过程中访问所需的信息。在附录中,我们将介绍 Graph-ToolFormer 源代码所使用的标准数据组织格式。
具体来说,图数据集中心托管的数据集包括
– 图属性推理数据集:GPR;
– 书目网络数据集:Cora、Pubmed、Citeseer;
– 分子图数据集:蛋白质、Mutag、Nci1、Ptc;
– 在线社交网络数据集:Twitter、Foursquare;
– 推荐系统数据集:Amazon、Last-FM、Movielens;
– 知识图数据集:WordNet、Freebase。关于本文研究的图数据集的更多详细信息将在下面第 5 节讨论实验时介绍
图模型中心:在 Graph-ToolFormer 框架中,我们还定义了一个图模型中心,用于托管多个(即用型)图工具和预训练的图神经网络模型。具体来说,Graph-ToolFormer框架包含的图模型包括
– Toolx:本文基于networkx创建,用于属性计算;
– Graph-Bert [60]:为图表示和节点分类而构建;
– SEG-Bert [58]:为图表示和图实例分类而构建;
– KMeans [26]:为图分区和节点聚类而构建;
– BPR [42]:为链接排名和推荐而构建;
– TransE [4]:为图实体/关系搜索而构建。
关于这些模型的更多详细信息将在下面的第 5 节中介绍。这些图模型将实现基本的图推理函数,这些函数将在提供的图数据集上的特定图推理任务中被调用
图任务中心:最后,图任务中心将定义Graph-ToolFormer框架中要研究的具体图推理任务。正如前面3.3节中介绍的,大多数图推理任务可以简化为几个非常基本的图学习任务,例如(1)图属性计算,(2)节点分类,(3)图分类,(4) )图分区/聚类,(5)链接预测/排名和(6)图搜索任务。对于4.3节中介绍的所有面向应用的图推理任务,即(1)图属性推理,(2)书目论文主题推理,(3)分子图函数推理,(4)社交网络社区推理,(5)推荐系统推理和(6)知识图推理,我们将它们简化为图任务中心中非常基本的图学习任务。
除了上面提到的中心之外,在 Graph- ToolFormer 框架内,我们还有一个额外的中心,用于托管 LLM,以便根据从与最终用户的交互中获得的输入生成图形推理 API。LLM 中心将托管一组用于图形推理任务的微调语言模型。具体来说,在本文所研究的 Graph-ToolFormer 框架中,可以将多个 LLM(如 GPT-J 6B 8bit)纳入中枢,用于输出图形推理语句的生成。
4.7.4 查询执行器模块。
此外,生成输出将通过检测和启动其中的 API 调用进行进一步的后处理。根据是否需要输出 API 调用的返回结果,执行器 Graph-ToolFormer 还将进一步在语句中用返回结果替换 API 调用。例如,对于第 4.7.1 节中提到的示例,根据解析结果"((GR, [(GL, ["cora"]), "graph-bert:topic", {Paper#1}]), [True])",Graph-ToolFormer 将识别并执行如下查询
外部函数: "GR",即外层函数用于图形推理。-
外部函数参数: "[(GL,["cora"]),"graph-bert:topic",{Paper#1}]"。".
- 参数 1:"(GL, ["cora"])", 第一个参数是嵌套 API 调用。
∗ 内部函数: "GL",即内部函数用于图形加载。
∗ 内部函数参数:"["cora"]",即图形加载 API 将加载 Cora 网络数据集。
- 参数 2:""graph-bert:topic"",第二个参数表示外部推理函数,旨在利用 Graph-Bert 模型推断出主题。
- 参数 3:"{Paper#1}",第三个参数表示外部推理函数的重点是输入图数据集中的 "Pa-per#1"。
- 输出插入标签: "True"(真),即此查询需要将此查询结果替换并插入到语句中
在对文本中的查询进行解析后,Graph-ToolFormer 中的查询执行器模块将根据所提供的图数据和参数调用相应的 API 函数来执行查询,即 "Graph-Bert.topic(cora, {Paper#1})",该函数将返回图推理查询结果,即神经网络,作为书目论文主题推理查询的输出结果。此外,由于查询中存在输出插入标记"->r",Graph-ToolFormer 中的查询执行器模块也将用推理结果替换查询标记序列,Graph-ToolFormer 的最终输出结果如下: