I. 介绍
无蜂窝大规模多输入多输出(Cell-free massive multiple-input multiple-output,CF-mMIMO)[1]最近被提出作为一种有前途的第五代(B5G)无线通信技术。在CF-mMIMO网络中,有大量的接入点(access points,ap),每个接入点都有一个天线,分布在一个很大的区域上,使用相同的时频资源共同为用户服务。这种场景类似于操作无处不在的小蜂窝基站(BSs),但没有蜂窝边界约束(即蜂窝自由)。CF-mMIMO 通过利用分布式MIMO和大规模MIMO的优点,与传统的共址MIMO(co-located mMIMO)[1] -[3]相比,具有良好的传播特性(propagation properties)和更高的能源效率(enhanced energy efficiency,EE)性能。它只需要简单的信号处理,如基于部分信道状态信息(CSI)的局部共轭波束形成(local conjugate beamforming),就可以实现干扰抑制(interference mitigation)[3]。
在没有小区边界的CF-mMIMO中,用户可以自由连接一个或多个ap。确定用户—AP关联的任务称为合作簇形成(cooperation cluster formation)。对CF-mMIMO系统的动态协同聚类进行了研究[3]-[6]。Ngo等人[3]提出了一种以用户为中心(user-centric)的AP选择方案来降低回程功耗(backhaul power consumption),并提升网络的能源效率。Riera-Palou等人[4]使用K-means聚类算法开发了ap与用户之间的最优连接模式(optimal connectivity pattern),以最小化 pilot contamination。Le等人[5]开发了一种基于 K-means 聚类的学习的方案,其目标是最大化频谱效率(the spectral efficiency)。Björnson和Sanguinetti[6]提出了一种合作聚类框架(cooperation clustering framework),该框架可以随着用户数量的增加而扩展。
内容缓存(Content caching)是一种将流行的内容文件存储在网络边缘以提高网络吞吐量(network throughputs)和降低服务延迟的技术(service delays)。在各种启用缓存的网络[7]-[13]中,研究了缓存策略和用户关联。Wei et al.[7]考虑了一种联合用户调度和缓存策略,以使用深度强化学习(DRL)算法最小化蜂窝网络中的传输延迟。但是,只考虑了宏BS的集中缓存能力,并且每个用户只能关联一个BS。Li等[8]认为所有小型BSs和宏观BSs都可以缓存文件,旨在通过深度Q-learning找到最优的缓存策略,使整体能源效率最大化。然而,只考虑随机用户- bs关联。Sadeghi等人[9]使用Q-learning对单个单元而不是整个网络优化缓存策略。Yang等人[10]研究了由BSs、中继和设备对设备(D2D)通信设备组成的异构网络中的内容缓存。然而,请求的用户仅由最近的具有最大接收功率的节点提供服务。Jing et al.[11]考虑了启用缓存的小蜂窝网络中的缓存和用户关联,并通过将其分解为两个子问题来优化有效容量来解决问题。然而,在小区限制下,每个用户只能关联一个小小区BS。Chan和Chien[12]在分层异构网络中引入了联合缓存和用户关联设计概念,其中每个用户只允许与一个单天线BS关联。Lin等人[13]研究了支持协调多点(CoMP)的蜂窝网络(coordinated multipoint (CoMP)-enabled cellular networks)中的缓存策略,其中允许边缘用户(edge users)连接到附近的BSs,但仍然受到蜂窝结构的限制。
在这项工作中,我们考虑了以前未检查的单元结构限制的 CF-mMIMO 网络中联合协作聚类和内容缓存问题。目标是确定ap上的内容缓存和用户-AP关联,从而使网络EE,由可实现的网络总和速率(achievable network sum rate)除以网络功耗定义(the network power consumption)最大化。
请注意,这个问题涉及权衡。基于频道质量的 User-AP association 可以增加网络总和速率,但可能产生较低的内容命中率(content hit rates),因此从 backbone/backhaul 检索内容时需要额外的电力消耗。相比之下,基于AP缓存状态的 user-AP association 可以减少与内容检索(content retrieval)相关的功耗,但可能无法提供良好的网络速率。这激发了联合设计,正如本文所考虑的那样。论文的主要贡献总结如下:
-
我们提出了基于深度确定性策略梯度(deep deterministic policy gradient, DDPG)的方法来解决 CF-mMIMO 网络中复杂的联合合作聚类(joint cooperation clustering)和内容缓存问题,其中在大型网络中难以找到全局最优解。DDPG算法基于参与者-评论家网络体系结构(actor-critic network architecture),其中参与者由奖励(网络EE)训练,以输出良好的策略值(good policy values),即合作聚类和内容缓存策略(cooperation clustering and content caching strategies)。
-
所提出的方法展示了良好的性能,在小型网络中接近最优的穷举搜索方法(optimal exhaustive search approach),并由于明智的联合设计(judicious joint design),在大型网络中优于基准(benchmarks),如基于信噪比(SNR)的聚类和基于流行度的缓存(popularity-based caching)。
论文的其余部分组织如下。Sec. II 描述了CF-mMIMO的系统模型和问题的表述。Sec. III 介绍了提出的 DRL-based 的方法。Sec. IV 给出了仿真结果和讨论。最后,Sec. V 对全文进行总结。
II. SYSTEM MODEL
A. 信号模型

我们考虑一个具有 M M M 个AP和 K K K 个用户(或用户设备,UE)的下行单元的大规模MIMO网络。 M \mathcal{M} M 和 K \mathcal{K} K 分别表示所有 AP 和 UE 的集合。图1描绘了一个拓扑的例子(example topology)。AP和UE各配置一根天线。每个AP通过物理光纤链路连接到地理上最近的中央处理单元(CPU)。在时分双工(TDD)操作下,选定的AP子集使用相同的时频资源共同服务于选定的UE子集[3]。设第 m m m 个AP与第 k k k 个UE之间的信道为 g m k = ( d m k / d 0 ) − α h m k g_{mk}= \left(d_{m k} / d_{0}\right)^{-\alpha} h_{m k} gmk=(dmk/d0)−αhmk,其中 d m k d_{mk} dmk 为第 m m m 个AP与第 k k k 个UE之间的距离, d 0 = min m , k d m k d_{0}=\min _{m, k} d_{m k} d0=minm,kdmk 为参考距离, α α α 为路径损耗指数( α ≥ 2 α≥2 α≥2), h m k ∼ C N ( 0 , 1 ) h_{m k} \sim \mathcal{C N}(0,1) hmk∼CN(0,1) 表示小尺度衰落。设 S k \mathcal{S}_k Sk 为第 k k k 个UE的服务AP集合, C m \mathcal{C}_m Cm 第 M M M 个AP所服务的 UE 集合。我们认为所有UE都保证被不超过 L ( L < M ) L (L < M) L(L<M) 个AP(即 ∣ S k ∣ ≤ L , ∀ k |S_k|≤L,∀k ∣Sk∣≤L,∀k)所服务,但不一定所有AP都在服务UE。因此,的集合所有服务(活动)AP和所有 UE 为 S = ⋃ k = 1 K S k \mathcal{S}=\bigcup_{k=1}^{K} \mathcal{S}_{k} S=⋃k=1KSk 和 C = ⋃ m = 1 M C m \mathcal{C}=\bigcup_{m=1}^{M} \mathcal{C}_{m} C=⋃m=1MCm。设 q k q_k qk 为该UE服务的 APs 发送给第 k k k 个UE的符号,其中 E [ ∣ q k ∣ 2 ] = 1 \mathbb{E}\left[\left|q_{k}\right|^{2}\right]=1 E[∣qk∣2]=1 且 E [ q k ] = 0 , ∀ k \mathbb{E}\left[q_{k}\right]=0, \forall k E[qk]=0,∀k, E [ q k q l ∗ ] = 0 , ∀ k ≠ l \mathbb{E}\left[q_{k} q_{l}^{*}\right]=0, \forall k \neq l E[qkql∗]=0,∀k=l (即,用于不同UE的符号是不相关的)。则第 m m m 个AP采用共轭波束形成(conjugate beamforming)[1]的发射信号可表示为:
x m = ∑ k ∈ C m ρ m k g ^ m k ∗ q k (1) x_{m}=\sum_{k \in \mathcal{C}_{m}} \sqrt{\rho_{m k}} \widehat{g}_{m k}^{*} q_{k}\tag{1} xm=k∈Cm∑ρmkg mk∗qk(1)
其中, g ^ m k \widehat{g}_{m k} g mk 是信道 g m k g_{m k} gmk 的估计值。
r k = ∑ m ∈ S g m k x m + w k = ∑ m ∈ S k g m k x m + ∑ m ∈ S k c g m k x m + w k = ∑ m ∈ S k ∑ k ′ ∈ C m ρ m k ′ g m k g m k ′ ∗ q k ′ + ∑ m ∈ S k c g m k x m + w k = ∑ m ∈ S k ρ m k ∣ g m k ∣ 2 q k ⏟ useful signal + ∑ m ∈ S ∑ k ′ ∈ C m , k ′ ≠ k ρ m k ′ g m k g m k ′ ∗ q k ′ + w k ⏟ interference plus noise (2) \begin{aligned} r_{k} & =\sum_{m \in \mathcal{S}} g_{m k} x_{m}+w_{k} \\ = & \sum_{m \in \mathcal{S}_{k}} g_{m k} x_{m}+\sum_{m \in \mathcal{S}_{k}^{c}} g_{m k} x_{m}+w_{k} \\ = & \sum_{m \in \mathcal{S}_{k}} \sum_{k^{\prime} \in \mathcal{C}_{m}} \sqrt{\rho_{m k^{\prime}}} g_{m k} g_{m k^{\prime}}^{*} q_{k^{\prime}}+\sum_{m \in \mathcal{S}_{k}^{c}} g_{m k} x_{m}+w_{k} \\ = & \underbrace{\sum_{m \in \mathcal{S}_{k}} \sqrt{\rho_{m k}}\left|g_{m k}\right|^{2} q_{k}}_{\text {useful signal }} \\ & +\underbrace{\sum_{m \in \mathcal{S}} \sum_{k^{\prime} \in \mathcal{C}_m, k^{\prime} \neq k} \sqrt{\rho_{m k^{\prime}}} g_{m k} g_{m k^{\prime}}^{*} q_{k^{\prime}}+w_{k}}_{\text {interference plus noise }} \end{aligned}\tag{2} rk====m∈S∑gmkxm+wkm∈Sk∑gmkxm+m∈Skc∑gmkxm+wkm∈Sk∑k′∈Cm∑ρmk′gmkgmk′∗qk′+m∈Skc∑gmkxm+wkuseful signal m∈Sk∑ρmk∣gmk∣2qk+interference plus noise m∈S∑k′∈Cm,k′=k∑ρmk′gmkgmk′∗qk′+wk(2)
R k = log 2 ( 1 + ∣ ∑ m ∈ S k ρ m k ∣ g m k ∣ 2 ∣ 2 ∑ k ′ ∈ C , k ′ ≠ k ∣ ∑ m ∈ S ρ m k ′ g m k g m k ′ ∗ ∣ 2 + σ w 2 ) . (3) R_{k}=\log _{2}\left(1+\frac{\left.\left.\left|\sum_{m \in \mathcal{S}_{k}} \sqrt{\rho_{m k}}\right| g_{m k}\right|^{2}\right|^{2}}{\sum_{k^{\prime} \in \mathcal{C}, k^{\prime} \neq k}\left|\sum_{m \in \mathcal{S}} \sqrt{\rho_{m k^{\prime}}} g_{m k} g_{m k^{\prime}}^{*}\right|^{2}+\sigma_{w}^{2}}\right) .\tag{3} Rk=log2 1+∑k′∈C,k′=k ∑m∈Sρmk′gmkgmk′∗ 2+σw2 ∑m∈Skρmk gmk 2 2 .(3)
这个公式(3)是有很大问题的。
网络的可达最大和速率为:
R s u m = ∑ k ∈ C R k . (4) R_{\mathrm{sum}}=\sum_{k \in \mathcal{C}} R_{k}.\tag{4} Rsum=k∈C∑Rk.(4)
B. Caching Model
C. Power Consumption Model
网络总功耗由三部分组成[14]:
- i)所有服务ap的发射功率,其中包括将ap缓存中的内容直接提供给 UEs 所需的功率,
- ii)APs 从CPU中检索缺失内容文件所需的功率,以及
- iii)CPU 从 backbone 下载缺失内容所需的功率。
对于 i) 来说,则所有服务ap的发射功率之和由 ∑ m ∈ S P m \sum_{m \in \mathcal{S}} P_{m} ∑m∈SPm 给出。
对于 ii),我们认为AP检索缺失内容文件所需的功率与不同缺失文件的数量成正比。当与一个AP相关联的多个终端请求相同的内容文件时,该AP只需要从CPU中检索缺失文件一次。设 F m m i s s = ( ⋃ k ∈ C m { f k } ) ∩ F m c \mathcal{F}_{m}^{\mathrm{miss}}=\left(\bigcup_{k \in \mathcal{C}_{m}}\left\{f_{k}\right\}\right) \cap \mathcal{F}_{m}^{c} Fmmiss=(⋃k∈Cm{ fk})∩Fmc 为第 m m m 个AP需要但未在第 m m m 个AP缓存的,终端共同请求的内容文件集, P backhaul P_{\text {backhaul }} Pbackhaul 为每个 AP 向CPU请求一个缺失内容文件所需的功率,其中包括 backhaul 功率(在AP - CPU链路中获取内容所需的功率)和电路功率。那么,所有从CPU检索内容的总功耗由 P backhaul ⋅ ∑ m ∈ S ∣ F m miss ∣ P_{\text {backhaul }} \cdot \sum_{m \in \mathcal{S}}\left|\mathcal{F}_{m}^{\text {miss }}\right| Pbackhaul ⋅∑m∈S Fmmiss 给出。
对于 iii),我们认为,如果与不同 APs 关联的两个终端请求相同的内容,而这些内容没有在各自的服务 APs上缓存,CPU 只需要下载此内容文件一次。设 P backbone P_{\text {backbone}} Pbackbone 为CPU从主干下载一个内容文件所需的功率。则 CPU 从骨干网下载内容的功耗为 P backbone ⋅ ∣ ⋃ m ∈ S F m miss ∣ P_{\text {backbone }} \cdot\left|\bigcup_{m \in \mathcal{S}} \mathcal{F}_{m}^{\text {miss }}\right| Pbackbone ⋅ ⋃m∈SFmmiss 。
注意,这种考虑可以通过在CPU上缓存特定内容来实际实现,CPU配备了一个缓存,其存储空间足够大,可以放置丢失的内容,但不足以容纳所有内容。
总结 i) -iii),网络总功耗
P total = ∑ m ∈ S P m + P backhaul ⋅ ∑ m ∈ S ∣ F m miss ∣ + P backbone ⋅ ∣ ⋃ m ∈ S F m miss ∣ (5) \begin{aligned} P_{\text {total }}= & \sum_{m \in \mathcal{S}} P_{m}+P_{\text {backhaul }} \cdot \sum_{m \in \mathcal{S}}\left|\mathcal{F}_{m}^{\text {miss }}\right| \\ & +P_{\text {backbone }} \cdot\left|\bigcup_{m \in \mathcal{S}} \mathcal{F}_{m}^{\text {miss }}\right| \end{aligned}\tag{5} Ptotal =m∈S∑Pm+Pbackhaul ⋅m∈S∑ Fmmiss +Pbackbone ⋅ m∈S⋃Fmmiss (5)
D. Problem Formulation
我们的设计目标是共同设计合作聚类, S 1 , S 2 , … , S K \mathcal{S}_{1}, \mathcal{S}_{2}, \ldots, \mathcal{S}_{K} S1,S2,…,SK,还有内容缓存, F 1 , F 2 , … , F M \mathcal{F}_{1}, \mathcal{F}_{2}, \ldots, \mathcal{F}_{M} F1,F2,…,FM,使得 R sum / P total R_{\text {sum }} / P_{\text {total }} Rsum /Ptotal 定义的网络能效(energy efficiency,EE)最大化。从数学上讲,设计问题是
max S 1 , S 2 , … , S K F 1 , F 2 , … , F M R sum P total s.t. ∣ S k ∣ ≤ L , ∀ k ∈ C , ∣ F m ∣ ≤ N , ∀ m ∈ S . \begin{aligned} \max _{\substack{\mathcal{S}_{1}, \mathcal{S}_{2}, \ldots, \mathcal{S}_{K} \\ \mathcal{F}_{1}, \mathcal{F}_{2}, \ldots, \mathcal{F}_{M}}} & \frac{R_{\text {sum }}}{P_{\text {total }}} \\ \text { s.t. } & \left|\mathcal{S}_{k}\right| \leq L, \forall k \in \mathcal{C}, \\ & \left|\mathcal{F}_{m}\right| \leq N, \forall m \in \mathcal{S} . \end{aligned} S1,S2,…,SKF1,F2,…,FMmax s.t. Ptotal Rsum ∣Sk∣≤L,∀k∈C,∣Fm∣≤N,∀m∈S.
请注意,在解决问题(6)时存在设计权衡(design tradeoffs)。完全基于 S 1 , S 2 , … , S K \mathcal{S}_{1}, \mathcal{S}_{2}, \ldots, \mathcal{S}_{K} S1,S2,…,SK 的设计,可能倾向于将第 k k k 个 UE 与提供最佳信道条件的 APs 子集 S k \mathcal{S}_k Sk 相关联,因为这可能会增加 R k R_k Rk,从而增加 R sum R_\text{sum} Rsum。
相比之下,一个设计完全基于 F 1 , F 2 , … , F M \mathcal{F}_{1}, \mathcal{F}_{2}, \ldots, \mathcal{F}_{M} F1,F2,…,FM 可能倾向于将第 k k k 个 UE 与最好地对齐内容缓存状态和用户请求的 APs 子集 S k \mathcal{S}_k Sk 相关联,因为这可能会增加命中事件(hit events),从而减少 P total P_{\text {total }} Ptotal 。
这激发(motivates)了联合设计。此外,对于具有大量 APs 和终端的大型网络,该问题变得棘手。因此,我们开发了基于强化学习(reinforcement learning,RL)的合作聚类和内容缓存策略,下一节将对此进行讨论。
III. REINFORCEMENT LEARNING METHOD
在本节中,我们详细阐述了如何通过 DDPG 算法来解决聚类和缓存的联合问题(joint problem of clustering and caching)。定义了所考虑的RL问题中的三个基本元素(action、state 和reward)。由于聚类和缓存策略的动态演变(dynamic evolutions)在制定 RL 问题时特别重要,因此相关参数将在后续中按时间索引。
A. Action, Observation State, and Reward Function
在 t th t\text{th} tth 时隙,agent 的动作 a t a_t at 同时涉及聚类和缓存。设指标 a m k , t ∈ { 0 , 1 } a_{mk,t}∈\{0,1\} amk,t∈{ 0,1} 和 a m f , t ∈ { 0 , 1 } a_{mf,t}∈\{0,1\} amf,t∈{ 0,1} 分别表示第 m m m 个AP—第 k k k 个 UE 关联状态和第 m m m 个AP—第 f f f 个文件缓存状态,其中“1”表示关联成功或缓存,”0“表示相反的意思。
那么,智能体(agent)的动作 a t a_t at 可以定义为 a t = { a t c l , a t c a } a_{t}=\left\{a_{t}^{c l}, a_{t}^{c a}\right\} at={ atcl,atca},其中集合 a t c l = { a m k , t c l : m ∈ M , k ∈ K } a_{t}^{c l}=\left\{a_{m k, t}^{c l}:m \in \mathcal{M}, k \in \mathcal{K}\right\} atcl={ amk,tcl:m∈M,k∈K} 和 a t c a = { a m f , t c a : m ∈ M , f ∈ F } a_{t}^{c a}=\left\{a_{m f, t}^{c a}: m \in \mathcal{M}, f \in \mathcal{F}\right\} atca={ amf,tca:m∈M,f∈F} 分别包含表示第 t t t 个时隙的聚类和缓存整体结果的指标。注意,动作 a t a_t at 唯一地确定了集合 S k \mathcal{S}_{k} Sk、 C m \mathcal{C}_{m} Cm 和 F m \mathcal{F}_{m} Fm,即 S k = { m : a m k , t c l = 1 , m ∈ M } \mathcal{S}_{k}=\left\{m: a_{m k, t}^{c l}=1, m \in \mathcal{M}\right\} Sk={ m:amk,tcl=1,m∈M}, C m = { k : a m k , t c l = 1 , k ∈ K } \mathcal{C}_{m}=\left\{k: a_{m k, t}^{c l}=1, k \in \mathcal{K}\right\} Cm={ k:amk,tcl=1,k∈K}, F m = { f : a m f , t c a = 1 , f ∈ F } \mathcal{F}_{m}=\left\{f: a_{m f, t}^{c a}=1, f \in \mathcal{F}\right\} Fm={ f:amf,tca=1,f∈F}。
所考虑的RL中的 state 应该是CPU的可收集信息集(collectable information set),可用于计算奖励函数(reward function)。在本工作中,第 t t t 个时隙的观察状态(observation state)定义为信道增益 G t = { g m k , t : m ∈ M , k ∈ K } G_t=\left\{g_{m k, t}: m \in \mathcal{M}, k \in \mathcal{K}\right\} Gt={ gmk,t:m∈M,k∈K},前一个时隙的聚类和缓存动作,以及每个终端的文件请求历史的集合。用户请求统计 e t e_t et 定义为 e t = { e k f , t : k ∈ K , f ∈ F } e_{t}=\left\{e_{k f, t}: k \in\right. \mathcal{K}, f \in \mathcal{F}\} et={ ekf,t:k∈K,f∈F},其中 e k f , t = ∑ t ′ = 1 t 1 f k , t ′ = f e_{k f, t}=\sum_{t^{\prime}=1}^{t} \mathbf{1}_{f_{k, t^{\prime}}=f} ekf,t=∑t′=1t1fk,t′=f 为第 k k k 个终端到时间 t t t 时刻时的第 f f f 个文件的下载次数。观察状态表示为
s t ≜ { G t , e t , a t − 1 } (7) s_{t} \triangleq\left\{G_{t}, e_{t}, a_{t-1}\right\}\tag{7} st≜{ Gt,et,at−1}(7)
遵循(6a)中的问题目标,在第 t t t 个时隙的奖励函数定义为
r ( s t , a t ) ≜ R s u m , t P t o t a l , t r\left(s_{t}, a_{t}\right) \triangleq \frac{R_{\mathrm{sum}, t}}{P_{\mathrm{total}, t}} r(st,at)≜Ptotal,tRsum,t
其中, R s u m , t R_{\mathrm{sum}, t} Rsum,t 和 P t o t a l , t P_{\mathrm{total}, t} Ptotal,t 分别由式(4)和式(5)给出,附加下标 t t t 强调动态行为(dynamic behaviors)。注意,总的速率 R s u m , t R_{\mathrm{sum}, t} Rsum,t 取决于通道条件 G t G_{t} Gt 和聚类结果 a t c l a_{t}^{c l} atcl ,而总功率 P t o t a l , t P_{\mathrm{total}, t} Ptotal,t 取决于缓存结果 a t c a a_{t}^{c a} atca。
B. Deep Deterministic Policy Gradient Approach
由于 CF-mMIMO 网络中潜在的大量 UEs 和 APs 需要相当大的动作空间(action spaces),传统深度Q网络(deep Q network,DQN)学习联合聚类和缓存策略需要较长的训练时间,因此无法有效地捕获系统动态(system dynamics)。在这项工作中,采用深度确定性策略梯度(deep deterministic policy gradient, DDPG)算法来实现快速稳定的学习[15]。从本质上讲,DDPG网络遵循了行动者批评(actor-critic)方法,将额外的目标网络(target-network)与原始评估网络(evaluation-network)相结合,以提高收敛速度和稳定性。
参与者部分的目的是使用一个确定性策略 μ ( s t ∣ θ μ ) \mu\left(s_{t} \mid \theta^{\mu}\right) μ(st∣θμ) 在每个时隙产生一个动作,该策略由一个权重为 θ μ \theta^{\mu} θμ 的深度神经网络(DNN)学习。权重 θ μ \theta^{\mu} θμ 更新是为了找到最佳的确定性策略 μ ( s t ∣ θ μ ) \mu\left(s_{t} \mid \theta^{\mu}\right) μ(st∣θμ) 基于动作-价值函数,即预期的长期奖励定义为(expected long-term reward):
Q ( s t , a t ) ≜ E [ R t ∣ s t , a t ] (9) Q\left(s_{t}, a_{t}\right) \triangleq \mathbb{E}\left[R_{t} \mid s_{t}, a_{t}\right]\tag{9} Q(st,at)≜E[Rt∣st,at](9)
其中 R t R_t Rt 是累积的打折未来奖励(cumulative discounted future reward) R t ≜ ∑ i = t ∞ γ i − t r ( s i , a i ) R_t \triangleq \sum_{i=t}^{\infty} \gamma^{i-t} r\left(s_{i}, a_{i}\right) Rt≜∑i=t∞γi−tr(si,ai), γ ∈ [ 0 , 1 ] γ∈[0,1] γ∈[0,1] 是折现因子(discount factor)。通常情况下, θ μ θ^\mu θμ 由梯度上升法(gradient ascent method)更新
θ μ ← θ μ + α μ ∇ θ J ( θ ) ∣ θ = θ μ (10) \theta^{\mu} \leftarrow \theta^{\mu}+\left.\alpha^{\mu} \nabla_{\theta} J(\theta)\right|_{\theta=\theta^{\mu}}\tag{10} θμ←θμ+αμ∇θJ(θ)∣θ=θμ(10)
其中 α μ \alpha^{\mu} αμ 是学习率并且
J ( θ ) ≜ E s t [ Q ( s t , μ ( s t ∣ θ ) ) ] (11) J(\theta) \triangleq \mathbb{E}_{s_{t}}\left[Q\left(s_{t}, \mu\left(s_{t} \mid \theta\right)\right)\right]\tag{11} J(θ)≜Est[Q(st,μ(st∣θ))](11)
is the objective with the expectation taken with respect to s t s_{t} st。请注意,(9)中的动作-价值函数允许递归关系
Q ( s t , a t ) = r ( s t , a t ) + γ E [ Q ( s t + 1 , a t + 1 ) ] (12) Q\left(s_{t}, a_{t}\right)=r\left(s_{t}, a_{t}\right)+\gamma \mathbb{E}\left[Q\left(s_{t+1}, a_{t+1}\right)\right]\tag{12} Q(st,at)=r(st,at)+γE[Q(st+1,at+1)](12)
在 critic 部分需上式确定 Q ( s t , μ ( s t ∣ θ μ ) ) Q\left(s_{t}, \mu\left(s_{t} \mid \theta^{\mu}\right)\right) Q(st,μ(st∣θμ))。更具体地说,评论家评估动作值函数 Q ( s t , μ ( s t ∣ θ μ ) ∣ θ Q ) Q\left(s_{t}, \mu\left(s_{t} \mid \theta^{\mu}\right) \mid \theta^{Q}\right) Q(st,μ(st∣θμ)∣θQ) 使用权重为 θ Q \theta^{Q} θQ 的单独DNN。通常,权重 θ Q \theta^{Q} θQ 使用更新
θ Q ← θ Q − α Q ∇ θ L ( θ ) ∣ θ = θ Q (13) \theta^{Q} \leftarrow \theta^{Q}-\left.\alpha^{Q} \nabla_{\theta} L(\theta)\right|_{\theta=\theta^{Q}}\tag{13} θQ←θQ−αQ∇θL(θ) θ=θQ(13)
其中 α Q α^Q αQ 是学习率并且
L ( θ ) = E [ ( Q ( s t , a t ∣ θ ) − y t ) 2 ] (14) L(\theta)=\mathbb{E}\left[\left(Q\left(s_{t}, a_{t} \mid \theta\right)-y_{t}\right)^{2}\right]\tag{14} L(θ)=E[(Q(st,at∣θ)−yt)2](14)
是均方贝尔曼误差函数的均方值,其中目标为
y t = r ( s t , a t ) + γ Q ′ ( s t + 1 , μ ′ ( s t + 1 ∣ θ μ ′ ) ∣ θ Q ′ ) (15) y_{t}=r\left(s_{t}, a_{t}\right)+\gamma Q^{\prime}\left(s_{t+1}, \mu^{\prime}\left(s_{t+1} \mid \theta^{\mu^{\prime}}\right) \mid \theta^{Q^{\prime}}\right)\tag{15} yt=r(st,at)+γQ′(st+1,μ′(st+1∣θμ′)∣θQ′)(15)
改编自(12)中的递归关系。(15)中的上标 ′ \prime ′ 用来表示(15)中产生 y t y_t yt 的动作-价值函数是由单独的目标网络(target-network)提供的。相比之下,(14)中的 Q ( s t , a t ∣ θ ) Q\left(s_{t}, a_{t} \mid \theta\right) Q(st,at∣θ) 则由原始的评估网络(original evaluation-network)提供。评估网络和目标网络的结合使DDPG算法趋于稳定[15]。
请注意,实际上,(11)和(14)中的期望可以用样本均值近似(approximated by sample mean),因为很难知道 s t s_t st 的精确概率分布,其中随机样本是从存储元组 b i ≜ ( s i , a i , r i , s i + 1 ) b_{i} \triangleq\left(s_{i}, a_{i}, r_{i}, s_{i+1}\right) bi≜(si,ai,ri,si+1) 的 replay buffer D \mathcal{D} D 中提取的, i = t − D + 1 , … , t i=t-D+1, \ldots, t i=t−D+1,…,t。replay buffer D \mathcal{D} D 具有有限的缓冲区大小 D D D,其中缓存了 D D D 个最近的动作(actions)和相应的状态和奖励。
最终,执行软更新(soft updates)来进一步稳定目标评分网络(target critic network) θ Q ′ ← τ θ Q ′ + ( 1 − τ ) θ Q \theta^{Q^{\prime}} \leftarrow \tau \theta^{Q^{\prime}}+(1-\tau) \theta^{Q} θQ′←τθQ′+(1−τ)θQ 和目标演员网络(target actor network) θ μ ′ ← τ θ μ ′ + ( 1 − τ ) θ μ \theta^{\mu^{\prime}} \leftarrow \tau \theta^{\mu^{\prime}}+(1-\tau) \theta^{\mu} θμ′←τθμ′+(1−τ)θμ,其中 τ ≪ 1 \tau \ll 1 τ≪1 。在算法1中总结了完整的DDPG过程。

IV. SIMULATION RESULTS
A. Simulation Settings
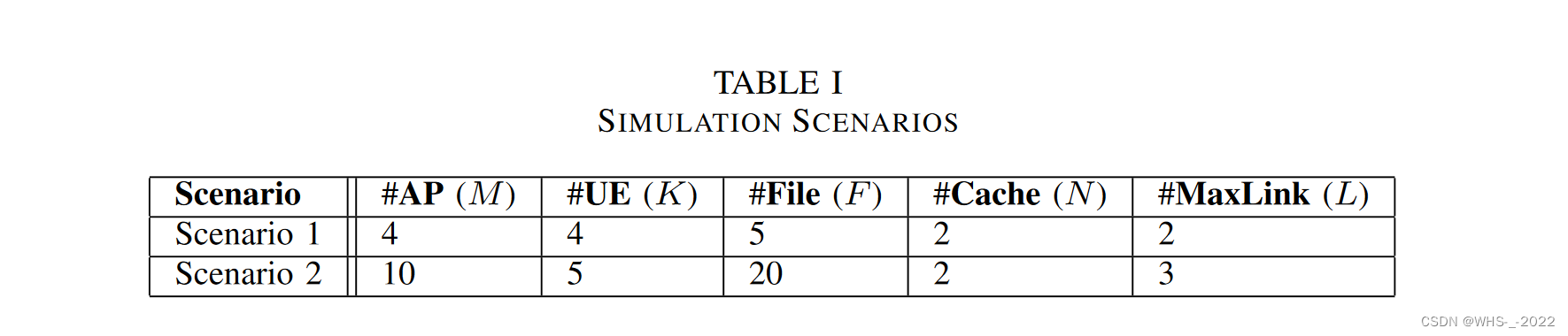
我们考虑如表1所示的两种场景,UEs 和 APs 均匀分布在 1 k m 2 1\text{ }\mathrm{km}^2 1 km2 范围内,其中一个AP锚定在参考坐标 ( 0 , 0 ) (0,0) (0,0)。在评估阶段,UEs 和 APs 的位置是固定的。为每个 UE 随机生成内容偏好向量(content preference vector),用户请求由 Zipf 因子 β = 1 β= 1 β=1[9],[10],[16]的内容偏好向量生成。在评估阶段,用户请求保持固定。路径损耗指数为 α = 2 α= 2 α=2,小尺度衰落系数 h m k ∼ C N ( 0 , 1 ) h_{m k} \sim \mathcal{C} \mathcal{N}(0,1) hmk∼CN(0,1) 服从时变模型[17]。
h m k ( t + 1 ) = 1 − ϵ 2 × h m k ( t ) + ϵ × n m k ( t ) (16) h_{m k}(t+1)=\sqrt{1-\epsilon^{2}} \times h_{m k}(t)+\epsilon \times n_{m k}(t)\tag{16} hmk(t+1)=1−ϵ2×hmk(t)+ϵ×nmk(t)(16)
其中 n m k ( t ) ∼ C N ( 0 , 1 ) n_{m k}(t) \sim \mathcal{C N}(0,1) nmk(t)∼CN(0,1), ϵ ∈ [ 0 , 1 ] \epsilon \in[0,1] ϵ∈[0,1] 是信道变异系数,在所有模拟中都设为 ϵ = 0.01 \epsilon=0.01 ϵ=0.01。
我们将所有 APs 的发射功率设置为 P m = 10 m W P_{m}=10 \mathrm{~mW} Pm=10 mW, P backhaul = P backbone = 500 m W P_{\text {backhaul }}=P_{\text {backbone }}=500 \mathrm{~mW} Pbackhaul =Pbackbone =500 mW[8]。每个终端处的热噪声功率由下式推导[1]
σ w 2 = Bandwidth × K B × T 0 × noise figure (W) (17) \sigma_{w}^{2}=\text { Bandwidth } \times K_{B} \times T_{0} \times \text { noise figure (W) }\tag{17} σw2= Bandwidth ×KB×T0× noise figure (W) (17)
其中 Bandwidth \text { Bandwidth } Bandwidth 设置为 20 MHz 20 \text{~MHz} 20 MHz, K B = 1.381 × 1 0 − 23 K_{B}=1.381 \times 10^{-23} KB=1.381×10−23, T 0 = 300 K T_0= 300\text{~K} T0=300 K,噪声系数 9 dB 9 \text{~dB} 9 dB,这导致 σ w 2 = 7.457 × 1 0 − 13 W \sigma_{w}^{2}=7.457 \times10^{-13} \mathrm{~W} σw2=7.457×10−13 W。actor 和 critic 网络都使用了两个隐藏层的DNNs,分别有400和300个神经元,以及tanh激活函数。
我们将所提出的RL方法与三种固定策略基准(fixed strategy benchmarks),称为BM1、BM2和BM3,以及仅适用于小场景(即场景1)的最优蛮力(BF)算法进行比较:
-
- BM1:基于信噪比的聚类策略,SNR-based clustering policy(第 k k k 个 UE 连接到所有AP中 ∣ g m k ∣ 2 \left|g_{m k}\right|^{2} ∣gmk∣2 最高的 l ≤ L l≤L l≤L 个 APs)和基于本地流行度的缓存策略,local-popularity-based caching policy(连接到第 m m m 个AP的特定 UEs 中最流行的 N N N 个文件缓存在第 m m m 个AP上)。
-
- BM2:基于信噪比的集群策略(与BM1相同)和基于全局流行度的缓存策略(所有终端中最流行的 N N N 文件在所有AP上缓存)。
-
- BM3:基于缓存的集群策略(一个终端连接到 l ≤ L l≤L l≤L 个AP,这些 APs 的前一个时隙的缓存最符合终端的文件请求)和基于全局流行度的缓存策略(与BM2相同)。
-
- BF:对所有集群/缓存组合进行穷举搜索,并找到产生最高EE的组合。
B. Results and Discussion
图2显示了场景1的结果。可以看出,BF、提出的RL和BM1( l = 1 l = 1 l=1)表现出相当的EE性能,显著高于所有其他方案。这种差异是由于不同程度的文件缺失以及在不同方案中(5)的第二项和/或第三项的不同值所带来的功耗上的近两个数量级的差异(图2(c))。
提出的 RL 优于所有基准测试,并且与这些基准测试不同,它不需要用户偏好信息(user preference information)。
BM1在EE方面优于BM2,因为虽然它们使用相同的集群策略实现相同的求和速率,但BM1基于本地流行度的缓存策略导致更少的文件丢失,从而降低了功耗。更具体地说,在BM1中,不同的AP可以根据文件在AP自己的服务网络 C m \mathcal{C}_m Cm 中的流行程度来缓存不同的文件,而在BM2中,所有AP都根据文件在整个网络中的流行程度来缓存相同的文件。
BM2在EE方面优于BM3,因为在这种情况下,由于基于信噪比的聚类,BM2在实现更高的和速率方面的优势超过了BM3由于基于缓存的聚类而在实现降低网络功耗方面的优势。BM3求和速率的波动是由于其在选择最匹配终端文件请求的AP时随机关联 l l l 个AP的机制。比较BM1( l = 1 l = 1 l=1)和BM1 ( l = 2 l = 2 l=2), BM1(l = 2)的EE性能会下降,因为对一个 AP 来说,它越来越难以将其缓存的文件与来自所有相关终端的文件请求相匹配,并且更多的文件丢失和更高的功耗主导了性能。
图2在t = 5时BF、RL和BM1 (l = 1)的快照如图3所示。BF找到ee最优策略。RL和BM1发现了类似的策略,其中RL规定了额外的UE2-AP4关联,这导致总和速率和EE的轻微增加。RL可能收敛于局部最优,或者在训练阶段的探索过程中没有探索最优动作,导致RL与BF之间存在观察到的差距。
V. CONCLUSION
在本文中,我们提出了一种基于 DDPG 的方法来解决缓存启用的CF-mMIMO网络中的联合合作聚类和内容缓存问题。DDPG框架遵循actor-critic网络架构,以增强收敛速度和稳定性。actor在每个时隙产生一个与聚类和缓存策略相对应的动作,critic评估与该动作相对应的预期累积奖励。所提出的方法在小型网络中展示了可验证的、接近最优的性能,在实际的、潜在的大型网络中,与固定策略基准相比,表现优越。