0. 题目
MELGLOW: EFFICIENT WAVEFORM GENERATIVE NETWORK BASED ON LOCATION-VARIABLE CONVOLUTION
MELGLOW:基于位置可变卷积的高效波形生成网络

1. 摘要
最近的神经声码器通常使用类似WaveNet的网络来捕获波形的长期依赖性,但是需要大量参数才能获得良好的建模能力。在本文中,提出了一种有效的网络,称为位置可变卷积,以对波形的依赖性进行建模。与在WaveNet中使用统一卷积内核来捕获任意波形的依赖性不同,位置可变卷积利用内核预测器基于mel频谱生成多组卷积内核,其中每组卷积内核用于执行在相关波形间隔上进行卷积运算。结合WaveGlow和位置可变卷积,设计了一种有效的声码器,称为MelGlow。 LJSpeech数据集上的实验表明,在小模型尺寸下,MelGlow的性能优于WaveGlow,这证明了位置可变卷积的有效性和潜在的优化空间
关键词: speech synthesis, text-to-speech, neural vocoder, glow, location-variable convolution
语音合成,文本到语音,神经声码器,glow,位置可变卷积
2. 简介
最近,语音合成在人机交互领域中发挥着越来越重要的作用。 由于语音质量或等待时间的微小变化可能会对客户体验产生重大影响,因此语音产品设计必须有效地合成高质量的语音,特别是对于智能扬声器和对话机器人。 当前,一般语音合成管道由两个组件[1、2、3、4、5、6、7、8、9]组成:(1)语音特征预测模型,可将文本转换为时间对齐的语音特征 (例如mel频谱),以及(2)从语音特征生成原始波形的神经声码器。 我们的工作集中在第二种模型上,该模型可以有效地从Mel频谱中生成高质量的语音
传统语音声码器使用数字信号处理 (DSP)以很高的速率重建语音波形,但其质量始终受到限制[10、11、12、13]。在最近的研究中,已经对神经声码器进行了广泛的研究。 WaveNet [14],一种自回归生成模型,被提出来以高的时间分辨率合成高质量的语音。 WaveRNN [15]应用高效的递归神经网络以比实时快4倍的速度生成语音,并使用权重修剪技术使其可部署在移动CPU上。 LPCNet [16]将WaveRNN与线性预测相结合,可以显着提高语音合成的效率。并行WaveNet [17]和ClariNet [18]使用逆自回归流(IAF)[19]作为学生模型从自回归老师WaveNet中提取知识。 FloWaveNet [20]和WaveGlow [21]设计了一个基于流的网络[22]以生成高质量的语音并具有非常简单的训练过程。在[23]中,提出了GAN激励线性预测以生成波形,其中GAN发生器输出线性预测的整个激励信号。 MelGAN [24]和GAN-TTS [25]实现了生成对抗网络(GAN)[26]以直接生成波形。类似地,基于GAN,并行WaveGAN [27]提出了对抗损失和多分辨率STFT损失之间的联合优化方法[28],以捕获真实语音信号的时频分布。由于高效前馈发生器的设计,这些基于GAN的声码器可高度并行化
神经声码器的关键是如何进行长期建模 基于调节声学特征的波形依赖性。 在WaveNet [14]中,使用因果卷积来捕获波形的长期相关性。 mel频谱用作本地条件输入,并添加到门控激活单元中。 在[29]中,设计了音调相关的扩张卷积来提高WaveNet的音调可控性。 由于WaveNet的卓越性能,许多后续的神经声码器使用了扩张的卷积结构[27、25、30、31]。 尽管膨胀卷积使模型能够捕获波形的长期相关性,但在膨胀卷积的每一层中都需要大量的卷积核以捕获不同的时间相关特征以实现良好的性能
在这项工作中,我们提出了位置可变卷积 用于波形生成网络的设计,以便更有效地捕获长期依赖性。 详细地,内核预测器被设计为根据条件声学特征(例如,mel-频谱)来预测卷积内核的系数,并且波形的不同段使用不同的卷积内核来实现卷积操作。 该卷积方法用于重新设计WaveGlow [21]的网络结构,从而获得更有效的语音声码器,称为MelGlow。 LJSpeech数据集[32]上的实验表明,在有限数量的模型参数的情况下,MelGlow可获取更高质量的语音。 同时,随着模式大小的减小,MelGlow的性能下降速度明显比WaveGlow的速度下降
我们的作品的主要贡献如下:
- 提出了一种新的卷积方法,称为位置变量卷积,以有效地捕获长期依赖关系,其中卷积核的系数由核预测器根据条件输入进行预测
- 一种基于位置可变卷积设计的效率更高的语音声码器MelGlow,它在限制模型尺寸时显示出比WaveGlow更高质量的语音
- 通过实验分析了MelGlow的性能与参数数量之间的关系,这表明MelGlow在未来具有优化的巨大潜力
3. 其他-容易懂
我们提出位置变量卷积,以基于局部条件序列对输入序列的长期依赖性进行建模,其中卷积核的系数在整个卷积过程中都会发生变化
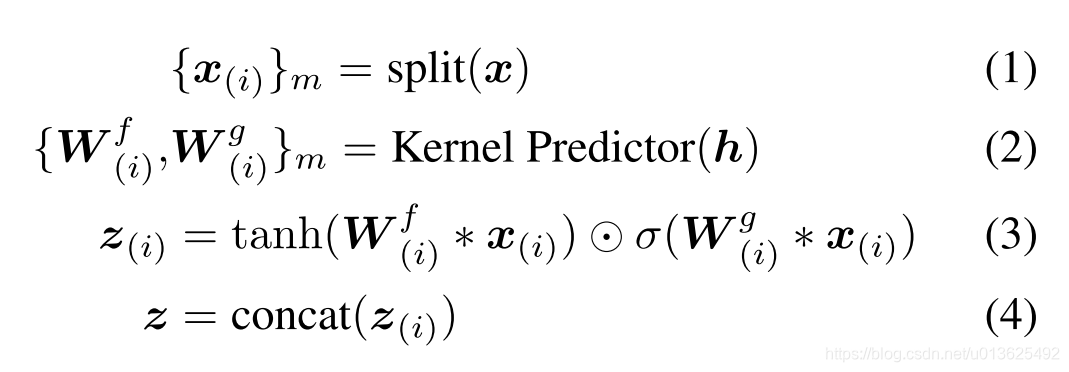
回顾使用数字信号处理(DSP)方法重构语音波形的传统声码器[10,11],一种流行的方法是线性预测声码器[10],它使用Levinson-Durbin算法来计算简单语音的线性预测系数。 极线性滤波器[33]根据声学特征。 线性预测器的预测过程与因果卷积的卷积过程相似,不同之处在于,线性预测器的系数是根据不同帧的声学特征计算的,并且因果卷积中的卷积核系数相同。 整个过程。 受此差异的启发,我们设计了一种具有可变卷积核系数的新颖卷积,可以更有效地对波形的长期依赖性进行建模

上图: 位置变量卷积中卷积过程的一个示例。 根据条件序列,内核预测器生成多组卷积内核,这些卷积内核用于对输入序列中的相关间隔执行卷积运算。 条件序列中的每个元素对应于输入序列中的4个元素

上图: Kernel Predictor
4. 其他-不容易懂
