关键词
bi-directional attention
来源
arXiv 2016.11.05
问题
利用 multi-stage 信息对文章进行编码,同时尝试两个方向上的 attention 来提高 RC 性能。
文章思路
BiDAF 文中分为六步
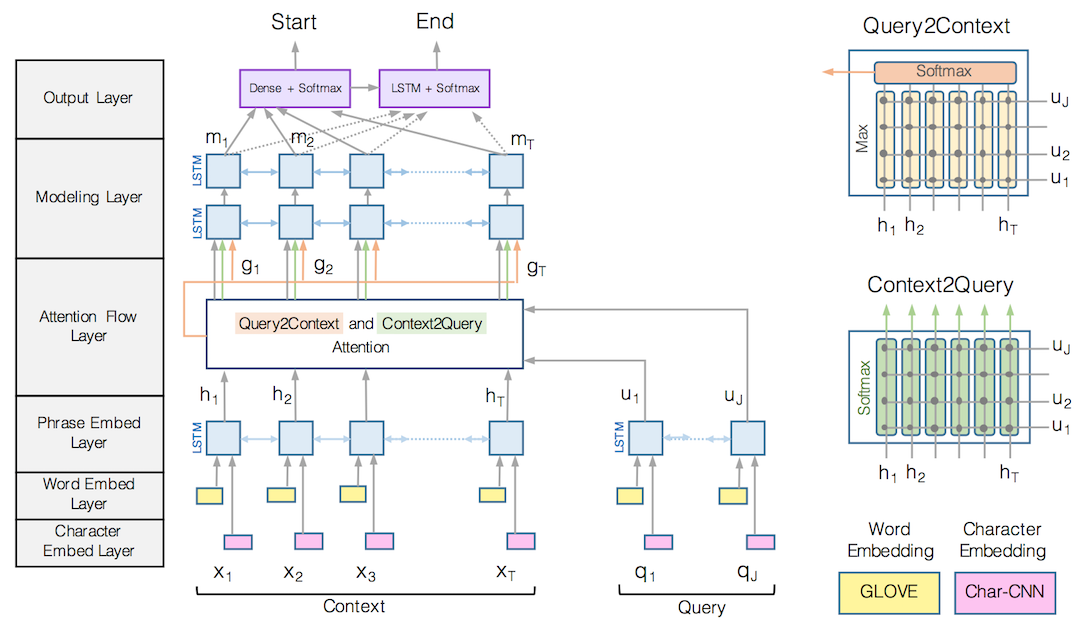
- Character Embedding Layer
- 利用 character level CNN 将每个词映射到一个高维向量空间
- Word Embedding Layer
- 利用 GloVe 将每个词映射到一个高维向量空间
然后把 character embedding 和 word embedding 拼接起来,通过两层 Highway Network 处理后得到 passage 矩阵和 query 矩阵,再输入到后面的层次。
- Phrase Embedding Layer
- 将前两步拼接得到的结果利用 Bi-LSTM 进行编码,以获得 contextual embeding,分别得到 passage 矩阵 H
Attention Flow Layer
定义相似度矩阵 S
如下
其中 ∘ 表示 element-wise multiplication, wT(s) 表示一个可训练的向量,可以把后面的向量映射为一个标量。后面的相似度计算均采用这里定义的公式。
Context-to-query Attention (C2Q) 这个方向的 attention 需要确定对于每一个 passage 中的词, query 中哪个词与它最接近。将 query 中每个词与 passage 中的一个词计算相似度,然后经 softmax 归一化后,计算 query 向量加权和。结果作为对应于 passage 这个词的问题表示向量,最后得到矩阵 U˜
。
Query-to-context Attention (Q2C) 这个方向的 attention 需要确定对于每一个 query 中的词,哪一个 passage 中的词和它最相似,也就是对于回答比较重要。取每列最大值,然后将这些最大值经 softmax 归一化后,计算 passage 向量加权和。将这个向量平铺 Vpassage
(passage 词汇个数) 次得到矩阵 H˜。
最终将这三个矩阵按如下方法拼接起来:
这样就得到了每个 passage 中词的 query-aware representation。Modeling Layer将 G 中的向量再次经过一个 Bi-LSTM 得到矩阵 M
Output Layer这一步预测 span 的开始位置和结束位置,如下
其中 M2 表示将 M 输入到另外一个 Bi-LSTM 中的结果, wT(pstart) 和 wT(pend)
- 都是可训练的向量。
训练目标采用
资源
论文地址:https://arxiv.org/abs/1611.01603
数据地址:https://rajpurkar.github.io/SQuAD-explorer/
相关工作
- Glove
- 这是一种不同于 word2vec 利用全局信息训练词向量的方式。word2vec 虽然取得了不错的效果,但模型上仍然存在明显的缺陷,比如没有考虑词序,没有考虑全局的统计信息等等。而 GloVe 将全局词-词共现矩阵进行了分解,训练得到词向量。但是相比 LSI 采用的词-文档矩阵,词-词共现矩阵更加稠密,模型中对低频词和高频词的影响做了一定地弱化处理。
- HighWay Networks
-
这种网络给原来的 FNN 加了 gate。原来的 FNN 是这样的
y=H(x,WH)
其中 H 表示非线性变换。而 Highway Networks 则又加了两个非线性变换变成
其中 T 是 transform gate, C 是 carry gate。一般取 C=1−T
-
。
这种网络最大的优点是能够利用 SGD 训练更深的网络,在实验中,即使加到 100 层也能够有效训练。
简评
文中采用新的 attention 机制,从实验效果来看确实提高了效果,在 development set 和 test set 上分别取得了 77.8% 和 78.1% 的 F-score。同时在 development set 上去掉 C2Q 与 去掉 Q2C 相比,分别下降了 12 和 10 个百分点,也就是说 C2Q 这个方向上的 attention 更为重要。
这篇文章中的 attention 计算后流动到下一层中,而不是像 Memory Networks 里面动态计算 attention。这么做一方面可以减少早期加权和造成的损失,另一方面也能够将之前错误 attention 的信息恢复。