Commonsense Knowledge Aware Conversation Generation with Graph Attention
文章目录
-
会议:IJCAI 2018
-
任务:开放域对话生成
-
代码:项目地址
1. Motivation
在对话任务中引入常识知识,作为现实世界的背景知识,可以强化模型对对话上下文的语义理解,从而生成更合适且更具有信息性的回复。
过去的引入外部知识的工作存在两个不足:
(1)它们高度依赖于非结构化文本的质量,或者受限于小规模、特定领域的知识;
(2)它们通常单独地、独立地利用知识三元组(实体),而不是将知识三元组看作图中的一个整体。因此,它们无法通过链接的实体和关系来表示图的语义。
2. Main idea
本文提出了常识知识感知的对话模型CCM,给定一个用户post,模型首先从知识库中检索相关知识图然后通过一个静态图注意力机制来编码图,以此来增强对用户Post的语义理解。
然后,在文本生成阶段,模型通过动态图注意力机制,专注地读取检索到的知识图以及每个图中的知识三元组,以促进更好的生成。这是第一个尝试在对话生成任务中使用大规模常识知识的工作。而且,不同于现有的模型—它们独立、分别地使用知识三元组,本文的模型将每个图视为一个整体,这样可以编码知识图谱中更多结构化的、连通的语义信息。
3. Model

3.1 知识检索
以用户的post作为查询,到知识库中检索出一系列图G,每个图包括一系列三元组,每个三元组包括:头实体、关系、尾实体。注意,只检索其邻近节点和关系。并且,每个单词只检索出一个图。
使用TransE来表征知识库中的关系和实体,为了填补知识库和非结构化对话文本的鸿沟,使用一个MLP:
k = ( h ; r ; t ) = M L P ( T r a n s E ( h ; r ; t ) ) \textbf{k} = (\textbf{h};\textbf{r};\textbf{t}) = MLP(TransE(h; r; t)) k=(h;r;t)=MLP(TransE(h;r;t))
即用TransE对三元组进行编码,然后使用MLP进行转换得到最终的三元组嵌入。
3.2 静态图注意力机制
知识图向量通过静态图注意力机制静态表征了输入X中相应单词的知识图。
具体而言,以TransE编码后的三元组向量作为输入,生成一个知识图向量。
这里用的是Bahdanau加性注意力模型,但是根据三元组的场景进行了改进,注意力权重衡量了关系r和头部实体、尾部实体的关联(没太看懂这里这么做的作用),最终生成的知识图向量是由头向量和尾向量和注意力得分的加权和。

3.3 知识解释器
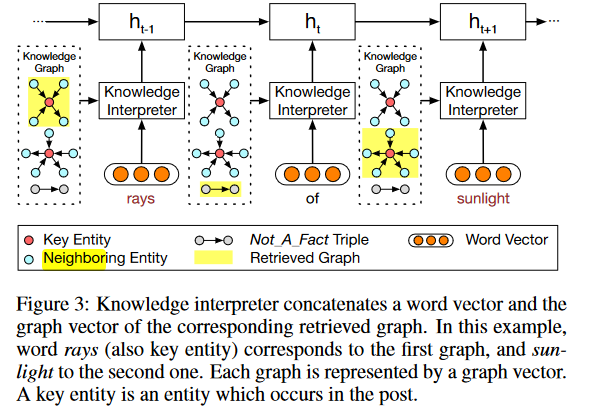
知识解释器以用户的post和检索到的图G作为输入,通过将词嵌入和它对应的知识图向量拼接,以获取每个单词的知识感知表示,然后送入到GRU中。
3.4 知识感知的生成器

知识感知的生成器主要有两个作用:
(1)选择性地读取检索到的图,得到一个图感知的上下文向量,并利用该向量更新解码器的状态。
(2)从检索到的图中自适应地选择一个通用词或实体进行词语生成。
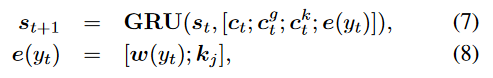
其中, c t c_t ct是编码器通过注意力机制生成的上下文向量, c t g c_t^g ctg和 c t k c_t^k ctk分别是上下文向量和知识图向量进行注意力计算得到的。
3.5 动态图注意力机制
动态图注意力机制是分层的,首先,给定解码器的当前状态 s t s_t st,它计算和全部知识图向量的注意力:

注意力权重衡量了解码器状态 s t s_t st和知识图向量 g i g_i gi的联系。
随后,计算 s t s_t st与每个知识图向量的所有三元组之间的注意力,使用的是双线性注意力打分函数:

最终加权时,要将第一层计算到的每个知识图向量的权重和图中每个三元组的权重乘起来。即先关注特定的图,再在这个图中关注特定的三元组。
解码时,选择一个词表中的词或实体词进行生成,即引入了Copy机制,这里可以参考PGN指针生成网络::
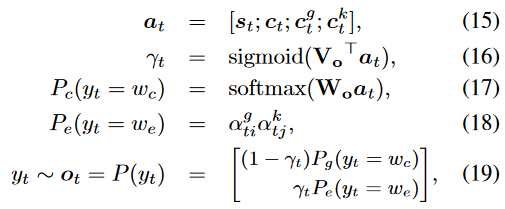
3.6 损失函数

这里应用一个监督信号作为teach-force是选择一个实体词还是一个通用词。损失函数的前一项是交叉熵损失函数,后一项是监督信号, q t ∈ { 0 , 1 } q_t \in \{0,1\} qt∈{
0,1},用于监督选择实体词或通用词的概率。