论文解读:Selective Attention for Context-aware Neural Machine Translation
当前诸多的神经机器翻译工作着力于句子级别(sentence-level)的sequence2sequence,很少考虑到整个文档级别(document-level)的上下文信息,本文作者Sameen Maruf、Andre F. T. Martins和Gholamreza Haffari在原有Transformer模型的基础上,提出一种基于自顶向下的可以结合文档上下文级别的Attention和单词级别(word token)的Attention。在三个英语-德语翻译基准数据集上进行实验,超越诸多baseline models。
一、相关背景
1、NMT模型
机器翻译的目标是对输入的原始句子转换为目标翻译句子,传统方法是通过分类模型对原始句子进行建模,并通过自回归模型构造对应翻译目标句子的分布,设原始句子为 ,目标句子为 ,其中 表示前 个已经预测的目标单词:
而神经机器翻译(NMT)的目标则是通过神经网络的Encoder2Decoder结构构造这个目标函数,其中 为神经网络的超参数。
1、Document-level NMT模型
基于文档上下文的机器翻译任务则是考虑到整个文档内所有句子上下文,作者认为基于文档级别的机器翻译目标是:
其中 表示所有对应文档内所有句子的集合, 表示除去第 个句子的其他句子。
二、提出的方法
作者提出的模型主要以Transformer为原型基础上进行了改进,首先加入了文档级别的上下文表征(即对文档内的所有句子进行上下文表征),并与字符级别进行合并,提出多层上下文注意力(Hierarchical Context Attention module),另外将该模块嵌入在Encoder和Decoder中,分别提出Monolingual context integration in Encoder和Bilingual context integration in Decoder。
1、Ducument-level Context layer
不同于Transformer只能对一个句子进行翻译工作,作者提出Hierarchical Context Attention module,基于本模块可以同时学习所有句子的特征信息。如图所示:
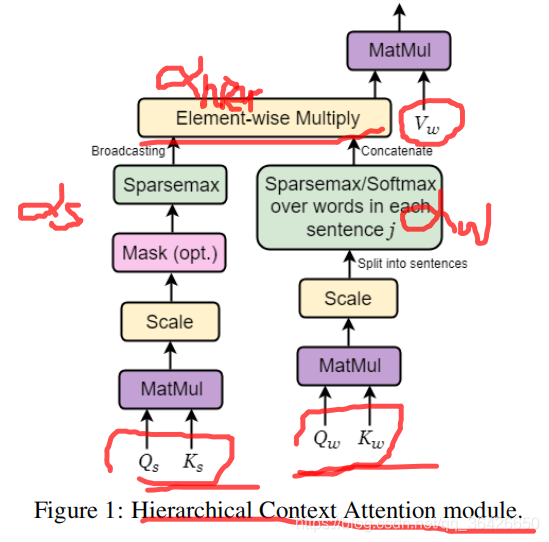
Hierarchical Context Attention module(H-Attention)的输入包括五个部分为
,
,
,
,
,其中 下标
分别表示句子级别和单词级别。如图所示,模块左侧为句子级别的Attention,用于对整个文档进行表征,Attention公式为:
其中 为 的维度, 为稀疏概率激活函数, 则是对每个句子学习一个权重。因此可知,该部分是试图在翻译当前某个句子的时候,有侧重的选择这个文档中其他句子作为额外信息;
模块中右侧则为单词级别,其旨在翻译某个句子中的某个词时,在预测当前词时有侧重的选择整个句子中其他单词作为额外信息,起到对齐的作用,Attention公式为:
其中 表示文档中第 个句子的单词 对应的key。
另外图中Element-wise Multiply部分是将句子级别的Attention和单词级别的Attention结合起来,因此可以得到一个权重矩阵,表示为 。因为每个 是针对单词的,因此输入的value只有单词级别的 ,整个Hierarchical Context Attention module模块的输出为 。
参考Transformer中的mult-head机制,作者也提出多头注意力:
其中
2、Integrated Model
基于上下文表征模块如何嵌套在Encoder和Decoder中,作者分别提出两个方法:
Monolingual context integration in Encoder(Encoder Stack)

Bilingual context integration in Decoder(Decoder Stack)
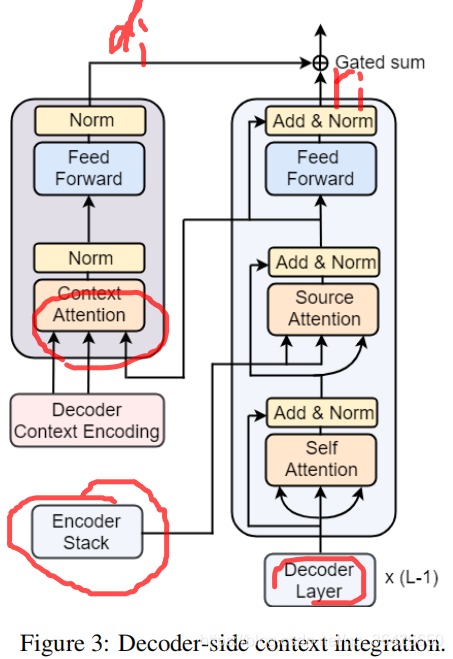
模块中的部分与Transformer的一致,其中作者去掉了mask机制,因为作者设计的模型是可以正向和反向翻译,因此不需要mask机制。另外Gated Sum表示门控求和,公式为:
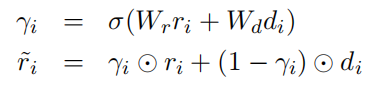
其非常类似于LSTM和GRU中的门控单元,
分别表示Ducument-level Context layer
得到的值
和Encoder(或Decoder)的输出。
特别说明的是,不论是Transformer还是本作者提出的模型,解码器(Decoder Stack)部分均为自回归模型,输入则为已经预测的单词(通常为上一个单词的向量),输出则为一个概率分布,表示单词库中每个单词的概率。
