支持向量机&鸢尾花Iris数据集的SVM线性分类练习
摘要
鸢尾花Iris数据集的SVM线性分类练习
一、SVM基础
有关SVM的详细知识,大家可以参考这篇文章:
1、三种支持向量机
一般支持向量机可以分为三类:线性可分支持向量机(support vector machine in linearly separable case)、线性支持向量机(linear support vector machine )以及非线性支持向量机(non-linear support vector machine)这三个由简至繁的模型分别解决训练数据的三个不同情况。
在这里引入一张图片,近距离体会上述三种数据类型
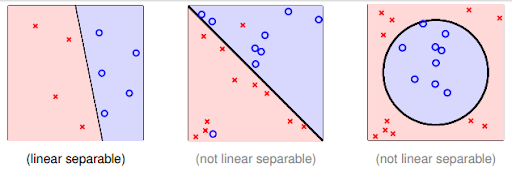
2、非线性支持向量机
当输入空间为欧式空间或离散集合、特征空间为希尔伯特空间时,核函数表示将输入从输入空间映射到特征空间得到的特征向量之间的内积。通过核方法可以学习非线性支持向量机,等价于在高维的特征空间中学习线性支持向量机。
通俗点理解就是,当我们的数据在其本身的空间里面没办法做到线性可分的时候,我们把他们以某种方式映射到高维空间,以期实现在高维中间线性可分。这样操作的要点是要选择合适的映射方式,也是就是要选对核函数。
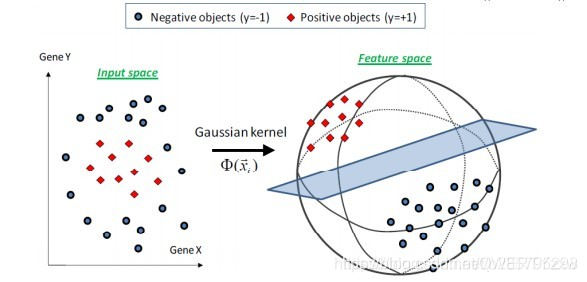

可以看到,原本在低维不可分的数据,映射到高维之后,就变得线性可分了。
二、鸢尾花实例
1、认识鸢尾花
iris数据集的中文名是安德森鸢尾花卉数据集,英文全称是Anderson’s Iris data set。iris包含150个样本,对应数据集的每行数据。每行数据包含每个样本的四个特征和样本的类别信息,所以iris数据集是一个150行5列的二维表。通俗地说,iris数据集是用来给花做分类的数据集,每个样本包含了花萼长度、花萼宽度、花瓣长度、花瓣宽度四个特征(前4列),我们需要建立一个分类器,分类器可以通过样本的四个特征来判断样本属于山鸢尾、变色鸢尾还是维吉尼亚鸢尾(这三个名词都是花的品种)。
2、鸢尾花实例演示
编译流程:
打开anaconda;

在home界面找到jupyter,launch;
进入编译软件界面,点击new下拉选择Python;
按图示操作界面
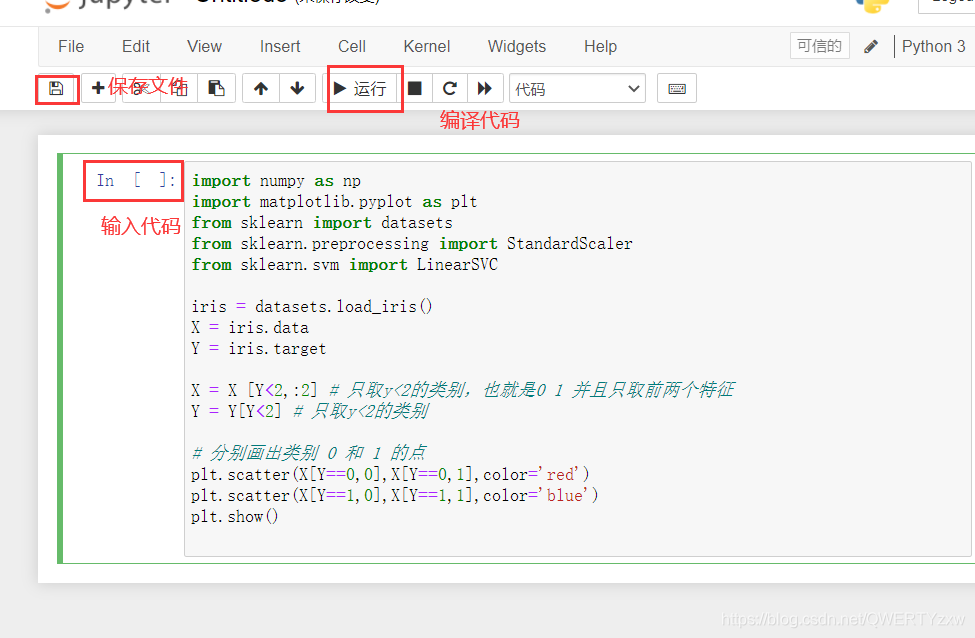
未经标准化的原始数据点分布
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
iris = datasets.load_iris()
X = iris.data
Y = iris.target
X = X [Y<2,:2] # 只取y<2的类别,也就是0 1 并且只取前两个特征
Y = Y[Y<2] # 只取y<2的类别
# 分别画出类别 0 和 1 的点
plt.scatter(X[Y==0,0],X[Y==0,1],color='red')
plt.scatter(X[Y==1,0],X[Y==1,1],color='blue')
plt.show()
编译运行

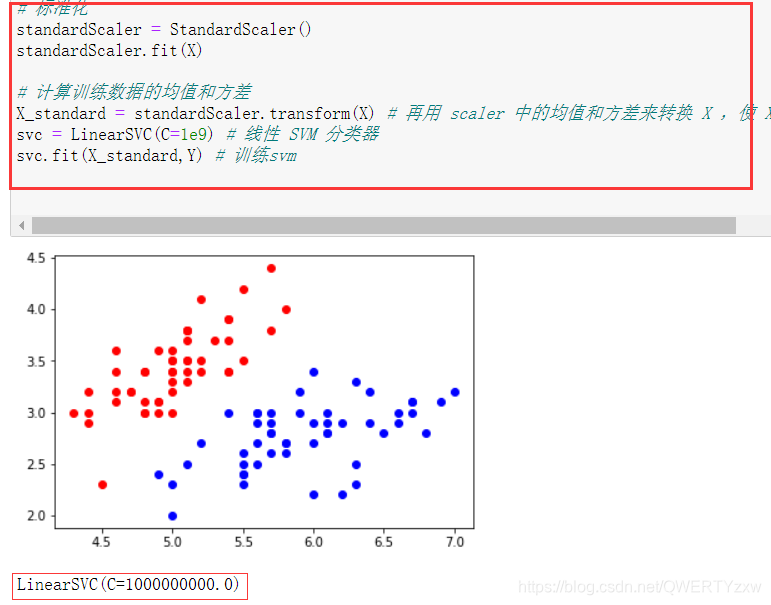
数据标准化
# 标准化
standardScaler = StandardScaler()
standardScaler.fit(X)
# 计算训练数据的均值和方差
X_standard = standardScaler.transform(X) # 再用 scaler 中的均值和方差来转换 X ,使 X 标准化
svc = LinearSVC(C=1e9) # 线性 SVM 分类器
svc.fit(X_standard,Y) # 训练svm
编译运行
绘制决策边界
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1) )
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz,linewidth=5, cmap=custom_cmap) # 绘制决策边界
plot_decision_boundary(svc,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
编译运行
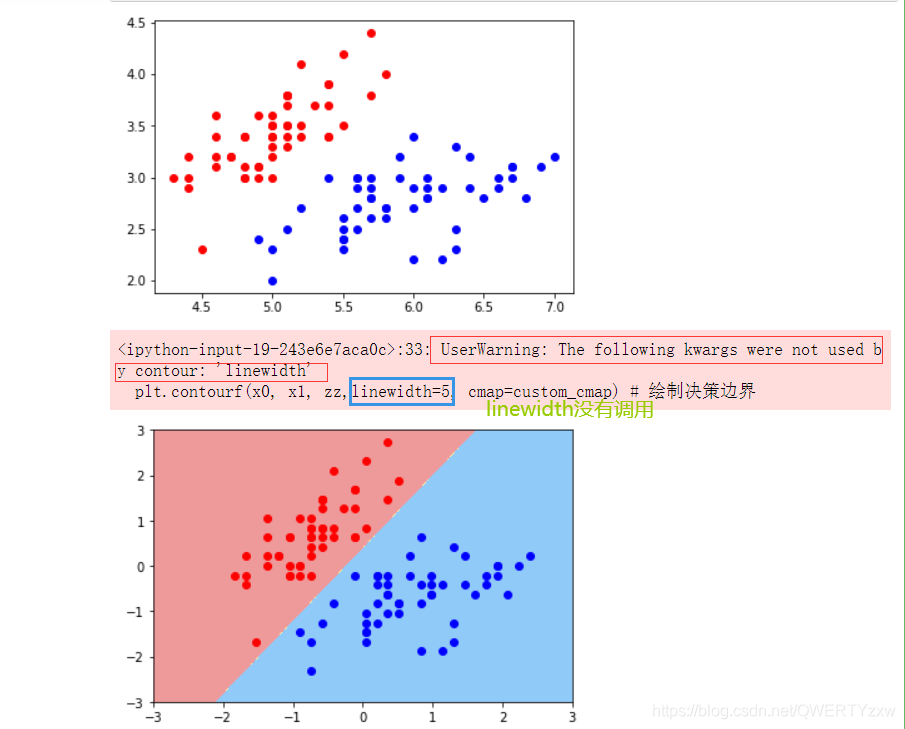
出现如图所示的warning,移除linewith=5
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1) )
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
from matplotlib.colors import ListedColormap
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap) # 绘制决策边界
plot_decision_boundary(svc,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
查看编译结果;
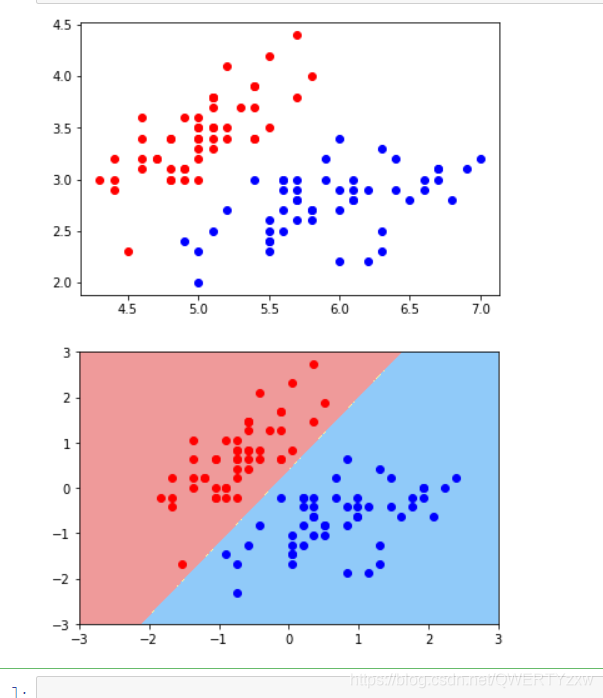
C C 是控制正则项的重要程度,再次实例化一个svc,并传入一个较小的 C C
svc2 = LinearSVC(C=0.01)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
编译运行
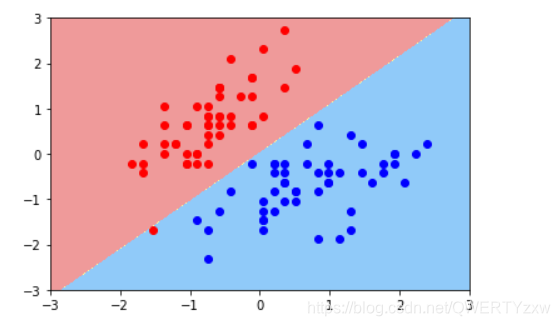
1、可以很明显的看到和第一个决策边界的不同,在这个决策边界汇总,有一个红点是分类错误的;
2、CC越小容错空间越大;
3、可以通过svc.coef_获取学习到的权重系数,svc.intercept_ 获取偏差。
代码汇总:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.preprocessing import StandardScaler
from sklearn.svm import LinearSVC
from matplotlib.colors import ListedColormap # 导入 ListedColormap 包
iris = datasets.load_iris()
X = iris.data
y = iris.target
X = X [y<2,:2] # 只取y<2的类别,也就是0 1 并且只取前两个特征
y = y[y<2] # 只取y<2的类别
# 分别画出类别 0 和 1 的点
plt.scatter(X[y==0,0],X[y==0,1],color='red')
plt.scatter(X[y==1,0],X[y==1,1],color='blue')
plt.show()
# 标准化
standardScaler = StandardScaler()
standardScaler.fit(X)
# 计算训练数据的均值和方差
X_standard = standardScaler.transform(X) # 再用 scaler 中的均值和方差来转换 X ,使 X 标准化
svc = LinearSVC(C=1e9) # 线性 SVM 分类器
svc.fit(X_standard,y) # 训练svm
def plot_decision_boundary(model, axis):
x0, x1 = np.meshgrid( np.linspace(axis[0], axis[1], int((axis[1]-axis[0])*100)).reshape(-1,1), np.linspace(axis[2], axis[3], int((axis[3]-axis[2])*100)).reshape(-1,1) )
X_new = np.c_[x0.ravel(), x1.ravel()]
y_predict = model.predict(X_new)
zz = y_predict.reshape(x0.shape)
custom_cmap = ListedColormap(['#EF9A9A','#FFF59D','#90CAF9'])
plt.contourf(x0, x1, zz, cmap=custom_cmap) #绘制决策边界
plot_decision_boundary(svc,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
svc2 = LinearSVC(C=0.01)
svc2.fit(X_standard,y)
plot_decision_boundary(svc2,axis=[-3,3,-3,3]) # x,y轴都在-3到3之间
# 绘制原始数据
plt.scatter(X_standard[y==0,0],X_standard[y==0,1],color='red')
plt.scatter(X_standard[y==1,0],X_standard[y==1,1],color='blue')
plt.show()
3、使用多项式特征和核函数
处理非线性数据
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
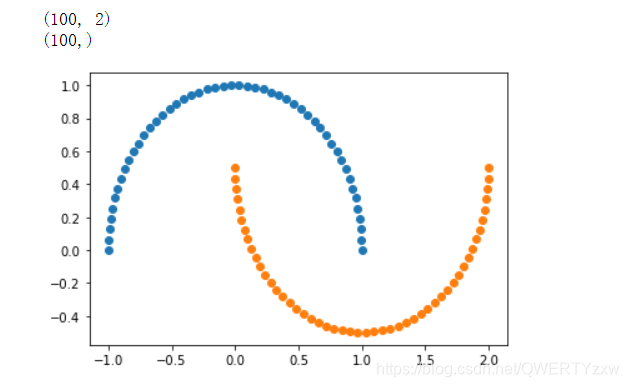
X,y = datasets.make_moons() #使用生成的数据
print(X.shape) # (100,2)
print(y.shape) # (100,)
#接下来绘制下生成的数据
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
编译运行
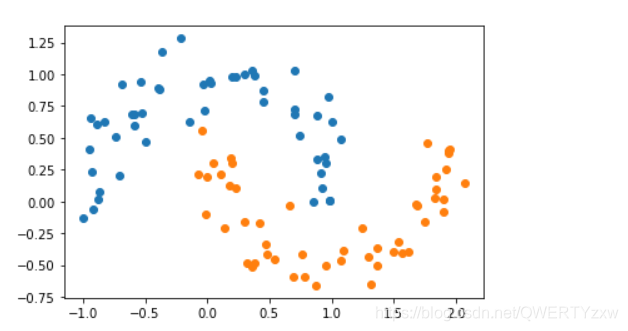
增加一些噪声点;
X, y = datasets.make_moons(noise=0.15,random_state=777) #随机生成噪声点,random_state是随机种子,noise是方差
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
编译运行
接下来通过多项式特征的SVM来对它进行分类
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree,C=1.0):
return Pipeline([ ("poly",PolynomialFeatures(degree=degree)),#生成多项式
("std_scaler",StandardScaler()),#标准化
("linearSVC",LinearSVC(C=C))#最后生成svm
])
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X,y)
plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
编译运行
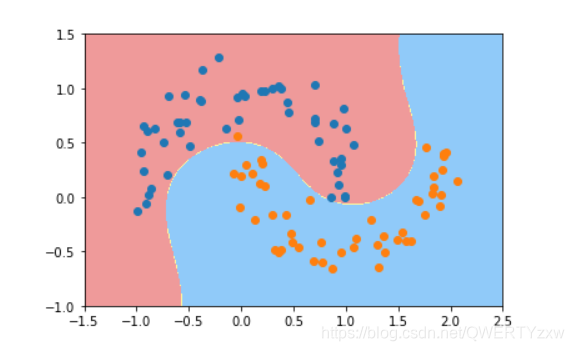
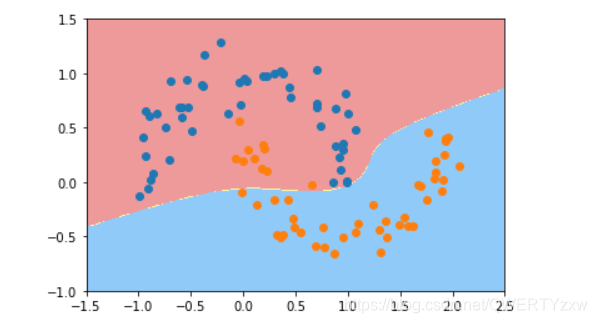
我们可以看到生成的边界不在是线性的直线了。
使用核技巧来对数据进行处理,使其维度提升,使原本线性不可分的数据,在高维空间变成线性可分的。再用线性SVM来进行处理
from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([ ("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly")) # poly代表多项式特征
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
编译运行
代码汇总:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
X, y = datasets.make_moons(noise=0.15,random_state=777) #使用生成的数据
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
from sklearn.preprocessing import PolynomialFeatures,StandardScaler
from sklearn.svm import LinearSVC
from sklearn.pipeline import Pipeline
def PolynomialSVC(degree,C=1.0):
return Pipeline([ ("poly",PolynomialFeatures(degree=degree)),#生成多项式
("std_scaler",StandardScaler()),#标准化
("linearSVC",LinearSVC(C=C))#最后生成svm
])
poly_svc = PolynomialSVC(degree=3)
poly_svc.fit(X,y)
plot_decision_boundary(poly_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
from sklearn.svm import SVC
def PolynomialKernelSVC(degree,C=1.0):
return Pipeline([ ("std_scaler",StandardScaler()),
("kernelSVC",SVC(kernel="poly")) # poly代表多项式特征
])
poly_kernel_svc = PolynomialKernelSVC(degree=3)
poly_kernel_svc.fit(X,y)
plot_decision_boundary(poly_kernel_svc,axis=[-1.5,2.5,-1.0,1.5])
plt.scatter(X[y==0,0],X[y==0,1])
plt.scatter(X[y==1,0],X[y==1,1])
plt.show()
1、这种方式也生成了一个非线性的边界;
2、这里SVC(kernel="poly")有个参数是kernel,就是核函数
三、总结与参考资料
1、总结
我对鸢尾花的相关基础知识了解的并不多,有兴趣的朋友可以参考文章上面的链接进行深入学习。