数据背景
由Fisher在1936年整理,包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度)),特征值都为正浮点数,单位为厘米。目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾))。
测试代码
新建lr_riis.py文件,编写代码
# -*- coding:utf-8 -*-
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
def load_data():
iris = datasets.load_iris()
print(iris.keys())
n_samples, n_features = iris.data.shape
print((n_samples, n_features))
print(iris.data[0])
print(iris.target.shape)
print(iris.target)
print(iris.target_names)
print("feature_names:", iris.feature_names)
def main():
load_data()
if __name__ == '__main__':
main()运行结果为:
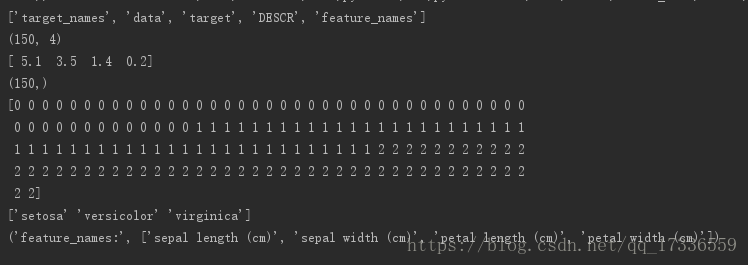
由结果可知:
iris中有5个key值
iris.data 包含了四个特征值,例如[5.1, 3.5, 1.4, 0.2]
iris.target为目标值
iris.feature_names为特征名称
模型预测实践
重新更新下代码
# -*- coding:utf-8 -*-
import numpy as np
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
def load_data():
# 共150条数据,训练120条,测试30条,进行2,8分进行模型训练
# 每条数据类型为 x{nbarray} [6.4, 3.1, 5.5, 1.8]
inputdata = datasets.load_iris()
# 切分,测试训练2,8分
x_train, x_test, y_train, y_test = \
train_test_split(inputdata.data, inputdata.target, test_size = 0.2, random_state=0)
return x_train, x_test, y_train, y_test
def main():
# 训练集x ,测试集x,训练集label,测试集label
x_train, x_test, y_train, y_test = load_data()
# l2为正则项
model = LogisticRegression(penalty='l2')
model.fit(x_train, y_train)
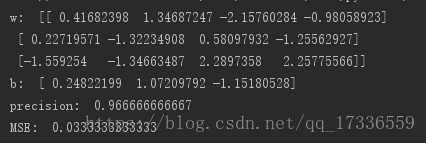
print "w: ", model.coef_
print "b: ", model.intercept_
# 准确率
print "precision: ", model.score(x_test, y_test)
print "MSE: ", np.mean((model.predict(x_test) - y_test) ** 2)
if __name__ == '__main__':
main()
运行结果为: