人脸关键点:DAN-Deep Alignment Network: A convolutional neural network for robust face alignment
DAN-Deep Alignment Network,发表于CVPR-2017。很纳闷DAN取名中的D,为什么是deep,如果是深度学习的deep,岂不是很无区分性?有知道的朋友请告诉我这个D是什么意思~
DAN从名字上看不出来这个网络的创新点在哪里。
创新点:
1.与以往的级联模型不同,网络模型输入是整张人脸图,可获取更多信息。
2.谁不想用更多的信息呢? 还不是因为有问题,但是DAN怎么解决这个问题的呢? 那就是 关键点热图(landmark heatmap)。landmark heatmap是本文的重点,这个东西贯穿全文。
———————————————正文——————————–
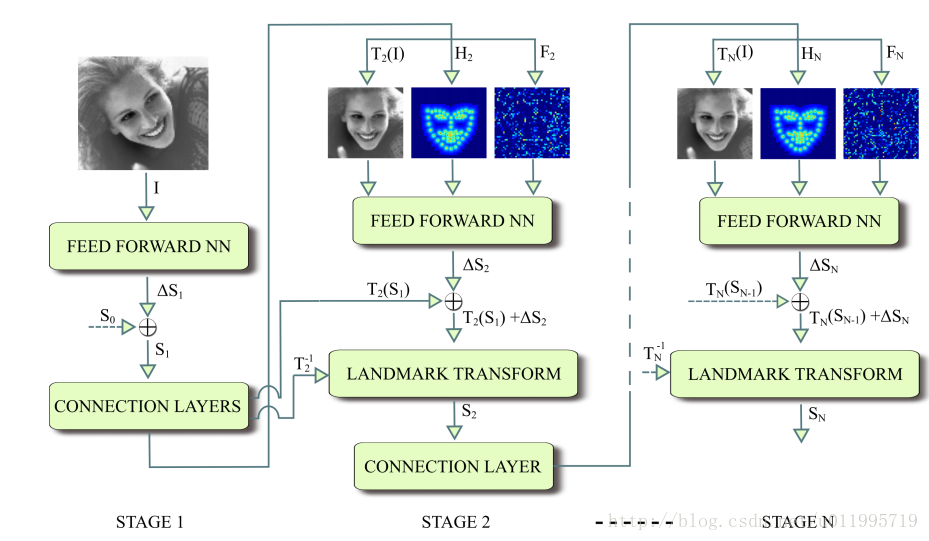
2017年,Kowalski等人提出一种新的级联深度神经网络——DAN(Deep Alignment Network),与以往级联神经网络输入的是图像的某一部分不同,DAN各阶段网络的输入均为整张图片。当网络均采用整张图片作为输入时,DAN可以有效的克服头部姿态以及初始化带来的问题,从而得到更好的检测效果。之所以DAN能将整张图片作为输入,是因为其加入了关键点热图(Landmark Heatmaps),关键点热图的使用是本文的重要创新点。DAN基本框架如图所示:
DAN包含多个阶段,每一个阶段含三个输入和一个输出,输入分别是被矫正过的图片、关键点热图和由全连接层生成的特征图,输出是面部形状(face shape)。其中,CONNECTION LAYER的作用是将本阶段得输出进行一系列变换,生成下一阶段所需要的三个输入,具体操作如下图所示: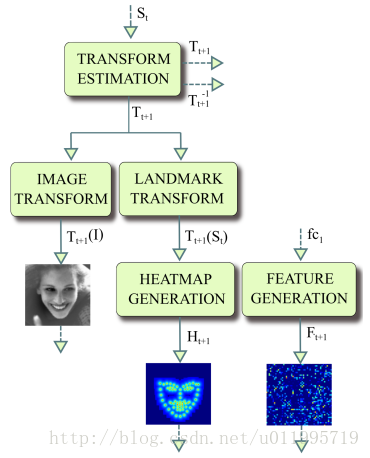
从第一阶段开始讲起,第一阶段的输入仅有原始图片,和S0。面部关键点的初始化即为S0,S0是由所有关键点取平均得到。第一阶段输出S1,对于第二阶段,首先S1由第一阶段的CONNECTION LAYERS进行转换,分别得到转换后图片T2(I)、S1所对应的热图H2和第一阶段fc1层输出,这三个东西正是第二阶段的输入。如此周而复始,直到最后一个阶段输出SN。文中给出在数据集IBUG上,经过第一阶段后的T2(I)、T2(S1)和特征图,如图所示: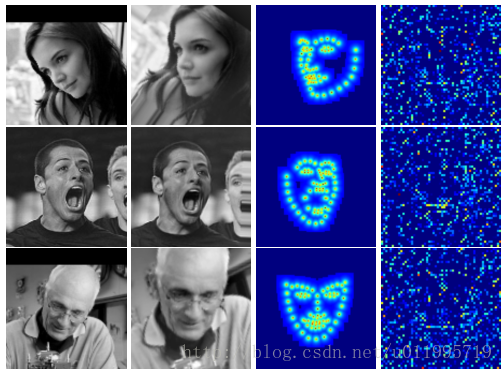
从图中发现,DAN要做的“变换”,就是把图片给矫正了,尤其是一行,那么DAN对姿态变换具有很好的适应能力,或许就得益于这个“变换”。至于DAN采用何种“变换”,需要到代码中具体探究。
接下来看一看,St是如何由St-1以及该阶段CNN得到,先看St计算公式:
其中 ΔStΔSt是由CNN输出的,各阶段CNN网络结构如图所示: 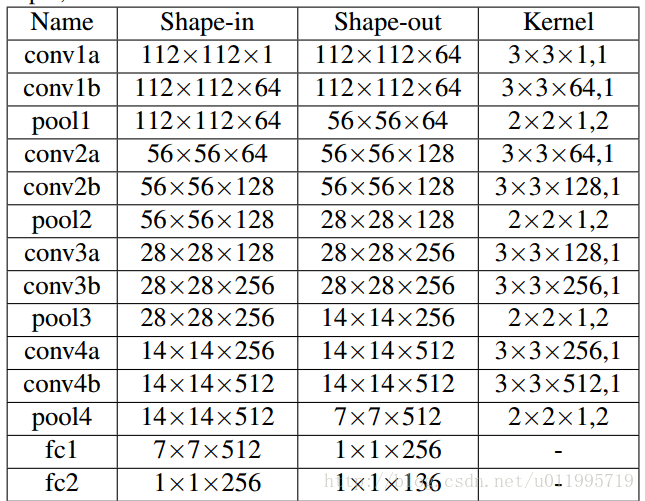
该CNN的输入均是经过了“变换”TtTt的操作,因此得到的偏移量 ΔStΔSt是在新特征空间下的偏移量,在经过偏移之后应经过一个反变换T−1tTt−1 还原到原始空间。而这里提到的新特征空间,或许是将图像进行了“矫正”,使得网络更好的处理图像。
关键点热度图的计算就是一个中心衰减,关键点处值最大,越远则值越小,公式如下: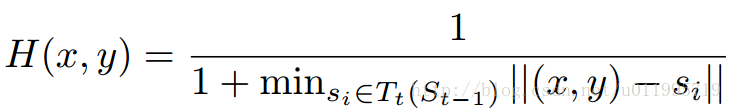
为什么需要从fc1层生成一张特征图?文中提到“Such a connection allows any information learned by the preceding stage to be transferred to the consecutive stage.”其实就人为给CNN增加上一阶段信息。
总而言之,DAN是一个级联思想的关键点检测方法,通过引入关键点热图作为补充,DAN可以从整张图片进行提取特征,从而获得更为精确的定位。
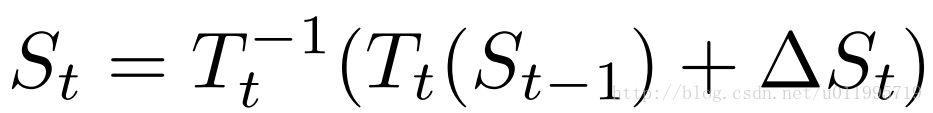
参考博客推荐:
http://blog.csdn.net/zjjzhaohang/article/details/78100465
http://blog.csdn.net/shuzfan/article/details/77839176
DAN-Deep Alignment Network,发表于CVPR-2017。很纳闷DAN取名中的D,为什么是deep,如果是深度学习的deep,岂不是很无区分性?有知道的朋友请告诉我这个D是什么意思~
DAN从名字上看不出来这个网络的创新点在哪里。
创新点:
1.与以往的级联模型不同,网络模型输入是整张人脸图,可获取更多信息。
2.谁不想用更多的信息呢? 还不是因为有问题,但是DAN怎么解决这个问题的呢? 那就是 关键点热图(landmark heatmap)。landmark heatmap是本文的重点,这个东西贯穿全文。
———————————————正文——————————–
2017年,Kowalski等人提出一种新的级联深度神经网络——DAN(Deep Alignment Network),与以往级联神经网络输入的是图像的某一部分不同,DAN各阶段网络的输入均为整张图片。当网络均采用整张图片作为输入时,DAN可以有效的克服头部姿态以及初始化带来的问题,从而得到更好的检测效果。之所以DAN能将整张图片作为输入,是因为其加入了关键点热图(Landmark Heatmaps),关键点热图的使用是本文的重要创新点。DAN基本框架如图所示:
DAN包含多个阶段,每一个阶段含三个输入和一个输出,输入分别是被矫正过的图片、关键点热图和由全连接层生成的特征图,输出是面部形状(face shape)。其中,CONNECTION LAYER的作用是将本阶段得输出进行一系列变换,生成下一阶段所需要的三个输入,具体操作如下图所示:
从第一阶段开始讲起,第一阶段的输入仅有原始图片,和S0。面部关键点的初始化即为S0,S0是由所有关键点取平均得到。第一阶段输出S1,对于第二阶段,首先S1由第一阶段的CONNECTION LAYERS进行转换,分别得到转换后图片T2(I)、S1所对应的热图H2和第一阶段fc1层输出,这三个东西正是第二阶段的输入。如此周而复始,直到最后一个阶段输出SN。文中给出在数据集IBUG上,经过第一阶段后的T2(I)、T2(S1)和特征图,如图所示:
从图中发现,DAN要做的“变换”,就是把图片给矫正了,尤其是一行,那么DAN对姿态变换具有很好的适应能力,或许就得益于这个“变换”。至于DAN采用何种“变换”,需要到代码中具体探究。
接下来看一看,St是如何由St-1以及该阶段CNN得到,先看St计算公式:
其中 ΔStΔSt是由CNN输出的,各阶段CNN网络结构如图所示:
该CNN的输入均是经过了“变换”TtTt的操作,因此得到的偏移量 ΔStΔSt是在新特征空间下的偏移量,在经过偏移之后应经过一个反变换T−1tTt−1 还原到原始空间。而这里提到的新特征空间,或许是将图像进行了“矫正”,使得网络更好的处理图像。
关键点热度图的计算就是一个中心衰减,关键点处值最大,越远则值越小,公式如下:
为什么需要从fc1层生成一张特征图?文中提到“Such a connection allows any information learned by the preceding stage to be transferred to the consecutive stage.”其实就人为给CNN增加上一阶段信息。
总而言之,DAN是一个级联思想的关键点检测方法,通过引入关键点热图作为补充,DAN可以从整张图片进行提取特征,从而获得更为精确的定位。
参考博客推荐:
http://blog.csdn.net/zjjzhaohang/article/details/78100465
http://blog.csdn.net/shuzfan/article/details/77839176