摘要
本文提出了一种端到端可训练的快速场景文本检测器,名为TextBoxes,它可以在单个网络正向通道中以高精度和高效率检测场景文本,除标准非最大抑制外,不涉及后处理。TextBoxes在文本定位精度方面优于其他竞争方法,并且速度更快,每张图片只需0.09s便可快速实现。此外,与文本识别器相结合,TextBoxes明显优于最先进的文字识别和端到端文本识别任务。
1、引言
场景文本是自然场景中最普遍的视觉对象之一。 它经常出现在道路标志,车牌,产品包等中。阅读场景文字有助于实现许多有用的应用程序,例如基于图像的地理定位。尽管与传统OCR相似,但由于前景文本和背景对象的大量变化以及不可控制的光照条件等,场景文本阅读更具挑战性。
由于不可避免的挑战和复杂性,传统的文本检测方法倾向于涉及多个处理步骤,例如, 字符/单词候选生成(Neumann and Matas 2012; Jaderberg et al。2016),候选过滤和分组。他们经常最终努力让每个模块正常工作,需要很多努力来调整参数和设计启发式规则,同时也放慢了速度 检测速度。受目标检测最新发展的启发(Liu et al。2016; Ren et al。2015),我们建议通过一个端到端可训练的单一神经网络直接预测字边界框来检测文本。
我们在本文中的主要贡献是一个快速和准确的文本检测器,称为TextBoxes,它基于完全卷积网络(LeCun et al。1998)。文本框通过联合预测文本存在和协调偏移到默认框(Liu et al。2016)直接输出多个网络层的文字边界框的坐标。最后的输出是所有框的聚合,然后是标准的非最大抑制过程。为了处理词汇纵横比的巨大变化,我们设计了几种新颖的初始样式(Szegedy et al。2015)输出层,它们利用不规则卷积核和默认盒。我们的检测器既能提供高精度和高效率,而且在单量程输入上只有一个正向通道,而且在多量程输入上具有多个通道,甚至具有更高的精度。此外,我们认为文字识别有助于将文本与背景进行区分,特别是当单词被限制在给定集合(即词典)时。我们采用成功的文本识别算法CRNN(Shi,Bai和Yao2015)与TextBoxes结合。识别器不仅提供了额外的识别输出,而且通过其语义级别的意识来规范文本检测,从而进一步提高了文字识别的准确性。TextBoxes和CRNN的组合产生了文字识别和端到端文本识别任务的最先进的表现性能,这似乎是一种简单而有效的解决方案,可用于强大的文本阅读。
总之,本文的贡献有三个方面:首先,我们设计了一个端到端的可训练神经网络模型,用于场景文本检测。其次,我们提出了一种词语识别/端到端识别框架, 第三,我们的模型在保持其计算效率的同时实现了高度竞争的结果。
2、相关工作
直观地说,场景文本阅读可以进一步分为两个子任务:文本检测和文本识别。 前者旨在将图像中的文本进行定位,主要是以文字框的形式; 后者可将单词图像裁剪成机器可解释的字符序列。 我们在本文中涵盖了这两项任务,但更注重检测。
基于基本的检测目标,以前的文本检测方法大致可以分为三类:
1)基于字符:首先检测个体角色,然后将其分组为单词(Neumann and Matas 2012; Pan,Hou,and Liu 2011; Yao et al。2012; Huang,Qiao and Tang 2014)。例如,(Neumann和Matas 2012)通过对极值区域进行分类来查找字符。 之后,通过穷举搜索方法将检测到的字符分组;
2)基于文字:用类似的一般对象检测方法直接打字(Jaderberg et al。2016; Zhong et al。2016; Gomez-Bigorda and Karatzas 2016)。 (Jaderberg et al。2016)提出了一个基于R-CNN的框架(Girshick et al。2014)。首先,候选词是由类别不可知的提案生成器生成的。 然后,这些建议被随机森林分类器分类。 最后,采用用于边界框回归的卷积神经网络来改进边界框。 (Gupta,Vedaldi和Zisserman 2016)改进了YOLO网络(Redmon et al。2016),但仍采用过滤和回归步骤来进一步消除误报;
3)基于文本行:文本行被检测到,然后分解成文字。例如,(Zhang等,2015)提出利用它们的对称特征来检测文本行。此外,(Zhang et al。2016)用完全卷积网络定位文本行(Long,Shelhamer和Darrell,2015)。
TextBoxes是基于文字(word)的。与(Jaderberg et al.2016)相比,它包含三个检测步骤,每个步骤还包括多个算法,TextBoxes享有更简单的路线。我们只需要训练一个网络端到端。
TextBoxes的灵感来源于SSD(Liu et al。2016),它是目标检测领域的一项新发展.SSD旨在检测图像中的一般对象,但不能识别具有极高宽高比的字。我们在文本框中提出了文本框图层来解决这个问题 ,这大大提高了性能。
我们采用称为CRNN(Shi,Bai和Yao 2015)的文本识别器与TextBoxes一起进行词语识别和端到端识别。CRNN直接输出给定输入图像的字符序列,并且也是端对端可训练的。此外,我们使用CRNN的置信度来规范TextBox的检测输出。注意也可以采用其他识别器,如(Jaderberg 等2016)。
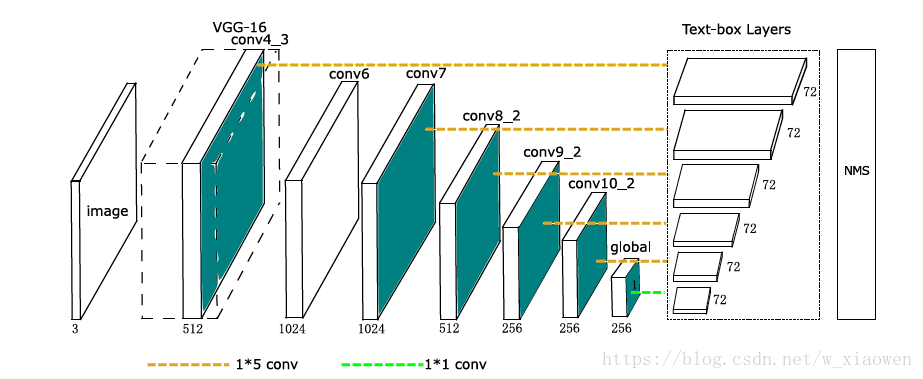
图1:TextBoxes Architecture.TextBoxes是一个28层完全卷积网络,其中13个是从VGG-16继承的。9个额外的卷积层被附加在VGG-16层之后。文本框层连接到6个卷积层 。在每个地图位置,文本框图层预测72个向量,这是12个默认框的文本存在分数(2-d)和偏移量(4-d)。 对所有文本框图层的聚合输出应用非最大抑制。
3、用TextBoxes检测文本
3.1架构
TextBoxes的体系结构如图1所示。它继承了流行的VGG-16体系结构(Simonyan和Zisserman 2014),保持从conv1_1到conv4_3的层次。最后两个完全连接的VGG-16层被转换为通过参数下采样卷积层(Liu et al。2016)。 它们之后是一些额外的卷积和合并层,即conv6到pool11。多个输出层(我们称之为文本框图层)被插入到最后和一些中间卷积层之后。它们的输出被聚合并经历非最大抑制(NMS)过程。输出层也是卷积的。总而言之,TextBoxes仅包含卷积和合并图层,因此完全卷积。它适用于训练和测试中的任意大小的图像。
3.2 文本框层
文本框图层是TextBoxes的关键组件。 文本框图层同时预测文本的存在和边界框,以输入特征图为条件。 在每个地图位置,它以卷积方式输出分类得分和偏移量到其关联的默认框。假设图像和特征地图尺寸分别是(wim; him)和(wmap; hmap)。 在关联默认框b0 =(x0; y0; w0; h0)的地图位置(i; j)上,文本框层预测(Δx;Δy;Δw;Δh; c) ,表示用置信度c检测框b =(x; y; w; h),其中
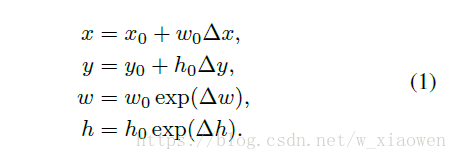
在训练阶段,根据(Liu et al。2016)的匹配方案,将真是标签字框按照框重叠匹配到默认框。每个地图位置与多个不同大小的默认框相关联。它们有效地划分字 通过它们的比例和长宽比,允许TextBoxes学习特定的回归和分类权重,以处理类似大小的单词。因此,默认框的设计高度针对特定任务。
与普通对象不同,单词倾向于具有较大的宽高比。因此,我们包括具有较大宽高比的“长”默认框。具体而言,我们定义了默认框的6种宽高比,包括1,2,3,5,7和10。然而,这使得默认框在水平方向上密集而垂直稀疏,这导致了较差的匹配框。为了解决这个问题,每个默认框设置了垂直偏移。默认框的设计如图2所示。
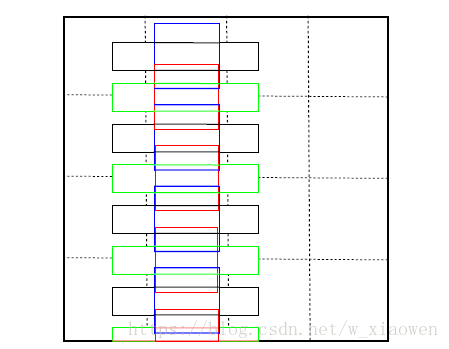
图2:4×4网格的默认框图示。为了更好的可视化,只绘制了宽高比为1和5的默认框的一列。 其余的纵横比为2,3,7和10,它们的放置方式相似。 黑色(宽高比:5)和蓝色(宽高比:1)默认方框位于其单元中央。 绿色(宽高比:5)和红色(宽高比:1)框分别具有相同的纵横比和垂直偏移(单元高度的一半)。
此外,在文本框图层中,我们采用了不规则的1 * 5卷积滤波器而不是标准的3 * 3卷积滤波器。这种初始形式(Szegedy et al。2015)滤波器产生矩形接收场,更适合具有更大纵横比的字, 还避免了方形感受野会带来的嘈杂信号。
3.3 学习
我们采用与(Liu et al。2016)相同的损失函数。令x为匹配指示矩阵,c为置信度,l为预测位置,g为地面实况位置。具体而言,对于第i个 默认框和第j个基本事实,Xij = 1表示匹配,而Xij = 0否则,损失函数定义为:
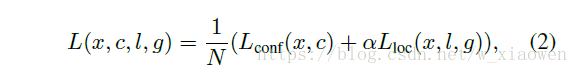
其中N是匹配groundtruth框的默认框的数量,以及α设置为1。我们采用Lloc的平滑L1损失(Girshick 2015)和Lconf的2级softmax损失。
3.4 多尺度输入
3.5 非最大抑制
(未完待续……)