Rethinking Atrous Convolution for Semantic Image Segmentation
目前的问题:
当前DCNN在语义分割的两个挑战:
1由连续池化操作或卷积所导致的特征分辨率降低,这使得DCNNs能够在不断增加的抽象特征表示中学习。然而,这种局部图像变换的不变性可能会妨碍密集的预测任务,因为在这些任务中需要详细的空间信息。
2另一个困难来自存在多个尺度的物体
相关工作:
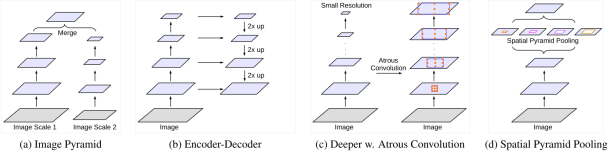
1.为解决问题1,DppeLab-v2提出的atrous convolution(洞卷积),已被证明是有效的语义图像分割,洞卷积可以在不需要学习额外参数的情况下,控制特征响应在DCNNs中计算的分辨率。如下图,具体讲解见DeepLab-v2.

2.为解决问题2,目前常用的方法为以下4种:
本文重新探讨了洞卷积的应用,这使能够在级联模块和空间金字塔池的框架内有效地扩大感受野,以纳入多尺度上下文。尤其是,本文提出的模块由具有不同速率和批量归一化层的洞卷积组成,并尝试以级联或并行方式布置模块(特别是ASPP)。我们讨论了在以极高的速率应用3×3洞卷积时遇到的一个重要的实际问题,由于图像边界效应,该卷积无法捕获远程信息,有效地简单地退化为1×1卷积,并将图像合并到ASPP模块中。
方法:
1.Atrous Convolution for Dense Feature Extraction(一种用于稠密特征提取的洞卷积算法)
见DeepLab-v2
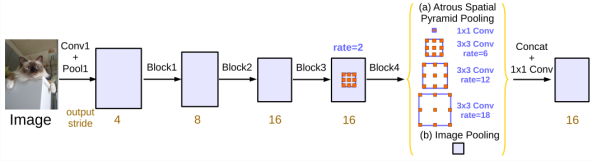
2.Going Deeper with Atrous Convolution(对洞卷积进一步深入)

在以Res net为backbone中,在上图a可以看出,consecutive striding对于语义分割是不利的,因为破坏了细节信息,b中,当output stride= 16时,在Block 3之后采用r> 1的洞卷积。同时,Multi-grid Method(多重网格法)定义了b中rate的大小,Block4-Block7中定义了Multi-Grid = (r1, r2, r3)为单位速率和相应速率的乘积,当output stride = 16和Multi-Grid =(1,2,4)时,三个convolutions在block4中的rate分别为= 2·(1,2,4)=(2,4,8)
3.Atrous Spatial Pyramid Pooling(ASPP)
本文改进后的并行级联ASPP框架:
成果:
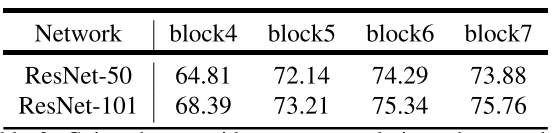
在PASCAL VOC 2012数据集中的测试结果(均采用going deeper with atrous convolution):
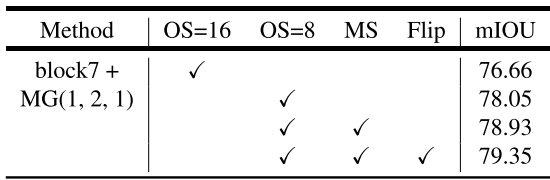
下表改变了output-stride、backbone、block、multi-grid。以m-Iou为评价标准进行测试。


下表中,MG: Multi-grid. OS: output stride. MS: Multi-scale inputs during test(多尺度输入). Flip: Adding left-right flipped inputs(添加左右翻转的输入).COCO: Model pretrained on MS-COCO(在MS-COCO数据集预训练)
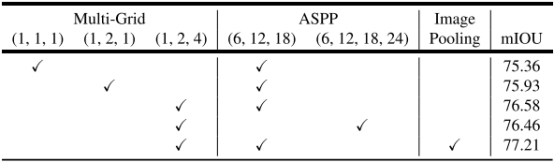
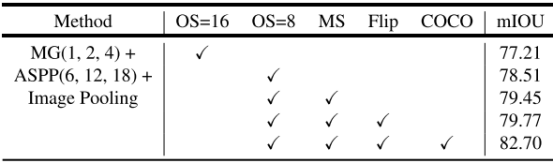
下表展示了不同方法下的m-Iou数值,特别注意的是DeepLab-v3中移去了v2中的CRF,反而实验效果更好。

下图为应用本模型的实验成果,最后一行为失败模型:

