前言
本文主要记录了一些经典的卷积网络架构,以及相应的pytorch代码。
提示:以下是本篇文章正文内容,下面案例可供参考
一、ResNeXt
1.1 网络结构
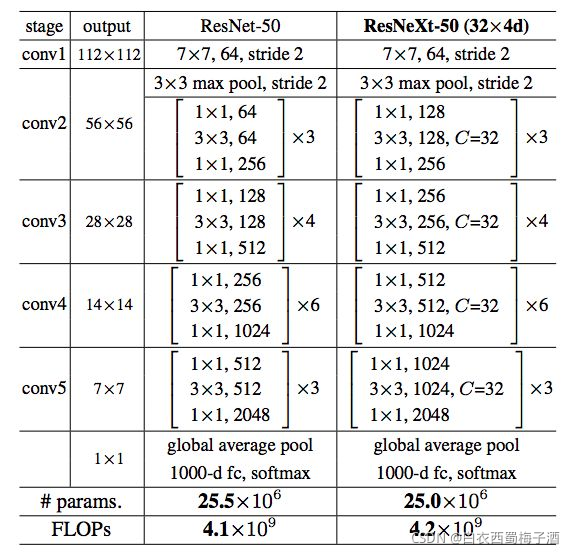
论文的一些思路
1.借鉴了VGG的堆叠卷积核以及GooleNet的Inception分支卷积的思想。
Inception结构主要就是分割-转换-合并策略,在不增加计算负载的情况下,增加网络的宽度和深度。
Inception结构可以看做是某个精心定制的网络结构,但较多的超参数,让其难以很快的应用到新的数据集中。论文通过想要解决上述问题,希望设计一种简单的结构有着较好的通用型。
(重复层(layers)的策略,同时使用一种简单、可扩展的方式来利用分割-转换-合并策略)
多分支卷积和分组卷积结合,再加上相应的集成策略
补充 使用上述结构需要block的depth>2
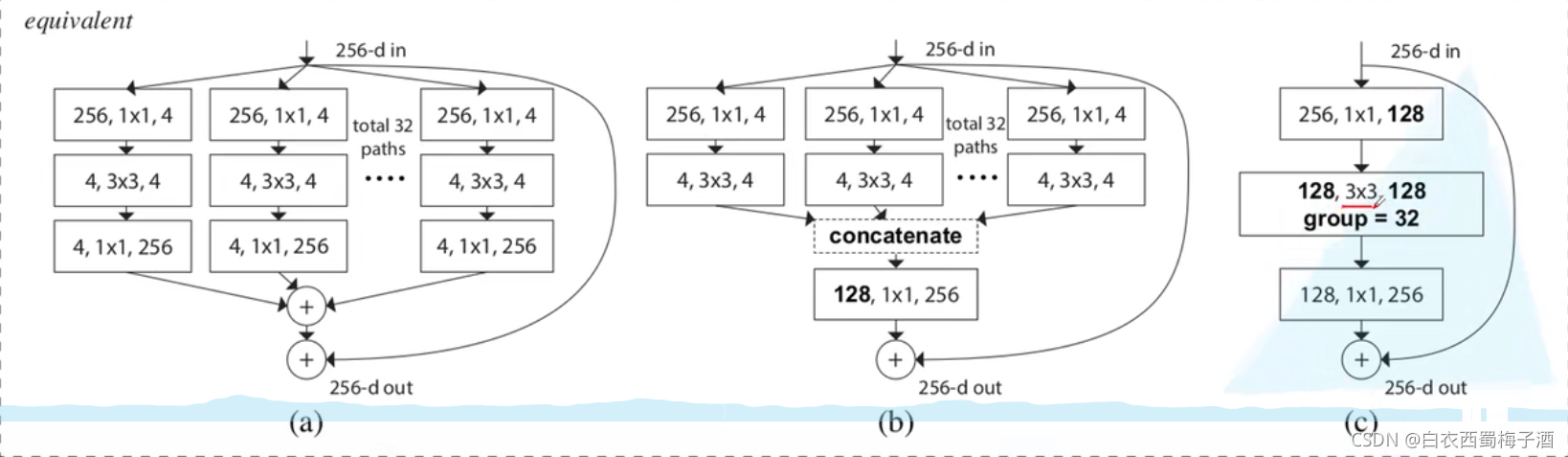
亮点
1.借鉴Inception的“分割-变换-聚合”策略,却用相同的拓扑结构组建ResNeXt模块
2.分组卷积降低了对于通道数的卷积,从而减少了参数(但是也丢了不少特征,所以为什么会更好?Inception系列论文中有部分描述,没有理论证明)
补充:对应Inception的思考:
全连接:split-transform-merge
Inception将上述操作人工设定,而ResNext则是将人工变为固定,(丢弃了不同尺寸得到的特诊。)
https://zhuanlan.zhihu.com/p/51075096
1.2 代码
(其中的分组卷积可以看做是将其主卷积分成各个组进行卷积操作,groups是conv2的分组个数,width_per_group是conv2的分组后的每个组的卷积核个数,会变)
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from torch.utils.data import DataLoader
class ResNet(nn.Module):
def __init__(self,block,block_num,num_classes=1000,groups=1,width_per_group=1):
super(ResNet,self).__init__()
self.groups=groups
self.width_per_groups=width_per_group
self.in_channel=64
self.conv1=nn.Conv2d(3,self.in_channel,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1=nn.BatchNorm2d(self.in_channel)
self.relu=nn.ReLU(inplace=True)
self.maxpool=nn.MaxPool2d(kernel_size=3,stride=2,padding=1)
self.layer1=self._make_layer(block,64,block_num[0],stride=1)
self.layer2=self._make_layer(block,128,block_num[1],stride=2)
self.layer3=self._make_layer(block,256,block_num[2],stride=2)
self.layer4=self._make_layer(block,512,block_num[3],stride=2)
self.avgpool=nn.AdaptiveAvgPool2d((1,1))
self.fc=nn.Linear(512*block.expansion,1000)
def _make_layer(self,block,channel,block_num,stride=1):
shortcut=None
## 意味着第一层为虚线残差结构即需要调整维度
if stride!=1 or self.in_channel!=channel*block.expansion:
shortcut=nn.Sequential(
nn.Conv2d(self.in_channel,channel*block.expansion,kernel_size=1,stride=stride,bias=False),
nn.BatchNorm2d(channel*block.expansion)
)
layers=[]
## 每个conv的第一层
layers.append(block(self.in_channel,channel,shortcut,stride=stride,groups=self.groups,width_per_groups=self.width_per_group))
self.in_channel=channel*block.expansion
for _ in range(block_num):
layers.append(block(self.in_channel,channel,groups=self.groups,width_per_groups=self.width_per_group))
return nn.Sequential(*layers)
def forward(self,x):
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.maxpool(x)
x=self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
class BasicBlock(nn.Module):
expansion=1
def __init__(self,in_channel,out_channel,stride=1,shortcut=None,**kwags):
super(BasicBlock,self).__init__()
self.conv1=nn.Conv2d(in_channels=in_channel,out_channels=out_channel,stride=1,kernel_size=3,padding=1,bias=False)
self.bn1=nn.BatchNorm2d(out_channel)
self.relu=nn.ReLU(inplace=True)
self.conv2=nn.Conv2d(in_channels=out_channel,out_channels=out_channel,kernel_size=3,padding=1,bias=False)
self.bn2=nn.BatchNorm2d(out_channel)
self.shortcut=shortcut
def forward(self,x):
x_shortcut=x
if self.shortcut is not None:
x_shortcut=self.shortcut(x)
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.conv2(x)
x=self.bn2(x)
x+=x_shortcut
out=self.relu(x)
return out
class BottleNeck(nn.Module):
expansion=4
def __init__(self,in_channel,out_channel,stride,shortcut,groups=1,width_per_group=64):
super(BottleNeck,self).__init__()
width=int(out_channel*(width_per_group/64))*groups
self.conv1=nn.Conv2d(in_channels=in_channel,out_channels=width,stride=1,kernel_size=1,bias=False)
self.bn1=nn.BatchNorm2d(out_channel)
self.conv2=nn.Conv2d(in_channels=width,out_channels=width,stride=stride,kernel_size=3,bias=False,groups=groups)
self.bn2=nn.BatchNorm2d(out_channel)
self.conv3=nn.Conv2d(in_channels=width,out_channels=out_channel*self.expansion,stride=1,kernel_size=1,bias=False)
self.bn3=nn.BatchNorm2d(out_channel*self.expansion)
self.relu=nn.ReLU(inplace=True)
self.shortcut=shortcut
def forward(self,x):
x_shortcut=x
if self.shortcut is not None:
x_shortcut=self.shortcut(x)
x=self.conv1(x)
x=self.bn1(x)
x=self.relu(x)
x=self.conv2(x)
x = self.bn2(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x+=x_shortcut
return self.relu(x)
def resnet101(num_classes=1000):
return ResNet(BottleNeck,[3,4,23,3],num_classes)
def resnext101(num_classes=1000):
groups=32
width_per_group=8
return ResNet(BottleNeck, [3, 4, 23, 3], num_classes,
groups=groups,
width_per_group=width_per_group
)
二、MobileNetV3
2.1 网络结构
网络结构

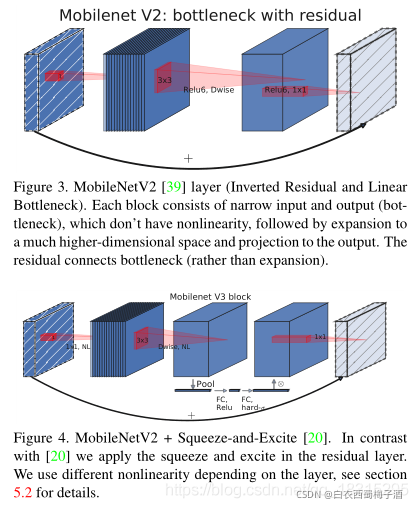
论文的思路
文章想要在移动端开发较好的计算机视觉架构,优化在移动设备上的准确性延迟。
回顾以往的结构
MobileNetV1使用深度可分离卷积(DW)来显着提高计算效率。 MobileNetV2通过引入具有反向残差和线性瓶颈(线性组合,relu非线性在低维度会丢失许多数据)的资源有效块来对此进行扩展。而MnasNet网络则在MobileNetV2上引入了注意力模块(基于挤压和激励的轻量级注意力模块?)
作者通过NAS搜索和NetAdapt来寻找网络的最优模型,然后将对模型中的注意力模块进行修改,将其使用的用h-swish代替swish激活函数,h-sigmoid代替sigmoid以降低计算量,降低计算的复杂度。
同时对于网络结构中计算成本较为昂贵的倒残差结构中的最后一层1*1卷积移到最终平均池化层之外,然后删除其中的投影和过滤层。
然后将第一个卷积层即过滤层中的过滤器个数,从32个减少到16个。
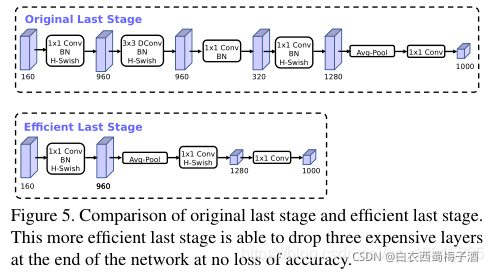
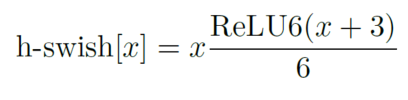
亮点
1.使用NAS搜索来构建全局的网络结构,然后利用NetAdapt算法来对每层的核数量进行优化和微调。
NAS搜索(Neural Architecture Search)
给定一个称为搜索空间的候选神经网络结构集合,用某种策略从中搜索出最优网络结构。神经网络结构的优劣即性能用某些指标如精度、速度来度量,称为性能评估。
具体过程如下所示

2.修改激活函数,同时精简网络的结构。
拓展文献
1.NAS搜索综述
2.NetAdapt
3.MnasNet
2.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.utils.data import DataLoader
from typing import Callable,List,Optional
from functools import partial
from torch.tensor import Tensor
def _make_divisible(ch,divisor=8,min_ch=None):
if min_ch is None:
min_ch=divisor
## 找到最接近对应倍数的整数(可向上,可向下)
new_ch=max(min_ch,int(ch+divisor/2)//divisor*divisor)
if new_ch <0.9*ch:
new_ch+=divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self,in_planes:int ,out_planes:int,kernel_size:int=3,stride:int =1,
groups:int =1,norm_layer:Optional[Callable[...,nn.Module]]=None,
activation_layer:Optional[Callable[...,nn.Module]]=None
):
## 计算padding
padding=(kernel_size-1)//2
if norm_layer is None:
norm_layer=nn.BatchNorm2d
if activation_layer is None:
activation_layer=nn.ReLU6
super(ConvBNActivation, self).__init__(nn.Conv2d(in_planes,out_planes,
kernel_size=kernel_size,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer(inplace=True)
)
## SE模块
class SqueezeExcitaion(nn.Module):
def __init__(self,input_c:int,squeeze_factor:int=4):
super(SqueezeExcitaion,self).__init__()
sequeeze_c=_make_divisible(input_c//squeeze_factor,8)
self.fc1=nn.Conv2d(input_c,sequeeze_c,1)
self.fc2=nn.Conv2d(sequeeze_c,input_c,1)
def forward(self,x:Tensor)-> Tensor:
scale=F.adaptive_avg_pool2d(x,output_size=(1,1))
scale=self.fc1(scale)
scale=F.relu(scale,inplace=True)
scale=self.fc2(scale)
scale=F.hardsigmoid(scale)
return scale*x
## width_factor 控制channel的超参数
class InvertedResidualConfig:
def __init__(self,
input_c:int,
output_c:int,
expsize:int,
kernel_size:int,
use_se:bool,
activation_func:str,
stride:int,
width_factor:float
):
self.input_c=self.changeSize(input_c,width_factor)
self.output_c=self.changeSize(output_c,width_factor)
self.kernel_size=kernel_size
self.use_se=use_se
self.use_hs=activation_func=="HS"
self.stride=stride
self.expsize=self.changeSize(expsize,width_factor)
@staticmethod
def changeSize(ch:int,factor:float,divisor:int=8):
return _make_divisible(ch*factor,divisor)
class InvertedResidual(nn.Module):
def __init__(self,
cfg:InvertedResidualConfig,
norm_layer:Callable[...,nn.Module]
):
super(InvertedResidual,self).__init__()
if cfg.stride not in [1,2]:
raise ValueError('illegal stride value')
if cfg.output_c==cfg.input_c and cfg.stride==1:
self.use_shortcut=True
layers:List[nn.Module]=[]
activation_func=nn.Hardswish if cfg.use_hs else nn.ReLU
if cfg.input_c!=cfg.expsize:
layers.append(ConvBNActivation(cfg.input_c,
cfg.expsize,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=activation_func
))
layers.append(ConvBNActivation(cfg.expsize,
cfg.expsize,
groups=cfg.expsize,
kernel_size=cfg.kernel_size,
stride=cfg.stride,
norm_layer=norm_layer,
activation_layer=activation_func
))
if cfg.use_se:
layers.append(SqueezeExcitaion(cfg.expsize))
layers.append(ConvBNActivation(cfg.expsize,
cfg.output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Identity
))
self.block=nn.Sequential(*layers)
self.out_channel=cfg.output_c
self.is_strided=cfg.stride>1
def forward(self,x:Tensor)->Tensor:
result=self.block(x)
if self.use_shortcut:
result+=x
return result
class MobileNetV3(nn.Module):
def __init__(self,inverted_setting:List[InvertedResidualConfig],
last_channel:int,
num_classes:int=1000,
block:Optional[Callable[...,nn.Module]]=None,
norm_layer:Optional[Callable[...,nn.Module]]=None
):
super(MobileNetV3,self).__init__()
if not inverted_setting:
raise ValueError("The Inverted_setting should not be empty")
elif not isinstance(inverted_setting,List) and all([isinstance(s,InvertedResidualConfig) for s in inverted_setting]):
raise TypeError("illegal type of Inverted_setting ")
if block is None:
block=InvertedResidual
if norm_layer is None:
norm_layer=partial(nn.BatchNorm2d,eps=0.001,momentum=0.01)
layers:List[nn.Module]=[]
firstconv_output_c=inverted_setting[0].input_c
layers.append(ConvBNActivation(3,firstconv_output_c,
kernel_size=3,stride=2,norm_layer=norm_layer,
activation_layer=nn.Hardswish
))
for cnf in inverted_setting:
layers.append(block(cnf,norm_layer))
lastconv_input_c=inverted_setting[-1].output_c
## 论文中固定为6倍
lastconv_output_c=6*lastconv_input_c
layers.append(ConvBNActivation(lastconv_input_c,
lastconv_output_c,
kernel_size=1,
norm_layer=norm_layer,
activation_layer=nn.Hardswish
))
self.features=nn.Sequential(*layers)
self.avgpool=nn.AdaptiveAvgPool2d(1)
self.classifier=nn.Sequential(nn.Linear(lastconv_output_c,last_channel),
nn.Hardswish(inplace=True),
nn.Dropout(0.2,inplace=True),
nn.Linear(last_channel,num_classes)
)
def forward_impl(self,x:Tensor)->Tensor:
x=self.features(x)
x=self.avgpool(x)
x=torch.flatten(x,1)
x=self.classifier(x)
return x
def forward(self,x:Tensor)->Tensor:
return self.forward_impl(x)
def mobilenet_v3_large(num_classes:int=100,reduced_tail:bool=False)->MobileNetV3:
width_multi=1.0 ## 控制对应的通道衰减数
bneck_conf=partial(InvertedResidualConfig,width_factor=width_multi)
changeSize=partial(InvertedResidualConfig.changeSize,factor=width_multi)
## pytorch官方设置的参数,用于控制后面三层的参数数量
reduce_divider=2 if reduced_tail else 1
inverted_residual_setting=[
bneck_conf(16,3,16,16,False,"RE",1),
bneck_conf(16,3,64,24,False,"RE",2),
bneck_conf(24,3,72,24,False,"RE",1),
bneck_conf(24,5,72,40,True,"RE",2),
bneck_conf(40,5,120,40,True,"RE",1),
bneck_conf(40,5,120,40,True,"RE",1),
bneck_conf(40,3,240,80,False,"HS",2),
bneck_conf(80,3,200,80,False,"HS",1),
bneck_conf(80,3,184,80,False,"HS",1),
bneck_conf(80,3,184,80,False,"HS",1),
bneck_conf(80,3,480,80,True,"HS",1),
bneck_conf(112,3,672,112,True,"HS",1),
bneck_conf(112,5,672,160//reduce_divider,True,"HS",2),
bneck_conf(160//reduce_divider,5,960//reduce_divider,160//reduce_divider,True,"HS",1),
bneck_conf(160//reduce_divider,5,960//reduce_divider,160//reduce_divider,True,"HS",1)
]
last_channel=changeSize(1280//reduce_divider)
return MobileNetV3(inverted_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)
def mobilenet_v3_small(num_classes:int=100,reduced_tail:bool=False)->MobileNetV3:
width_multi=1.0 ## 控制对应的通道衰减数
bneck_conf=partial(InvertedResidualConfig,width_factor=width_multi)
changeSize=partial(InvertedResidualConfig.changeSize,factor=width_multi)
## pytorch官方设置的参数,用于控制后面三层的参数数量
reduce_divider=2 if reduced_tail else 1
inverted_residual_setting=[
bneck_conf(16,3,16,16,True,"RE",2),
bneck_conf(16,3,72,24,False,"RE",2),
bneck_conf(24,3,88,24,False,"RE",1),
bneck_conf(24,5,96,40,True,"RE",2),
bneck_conf(40,5,240,40,True,"HS",1),
bneck_conf(40,5,240,40,True,"HS",1),
bneck_conf(40,5,120,48,True,"HS",1),
bneck_conf(48,5,144,48,True,"HS",1),
bneck_conf(48,5,288,96//reduce_divider,False,"HS",1),
bneck_conf(96//reduce_divider,5,576//reduce_divider,96//reduce_divider,True,"HS",1),
bneck_conf(96//reduce_divider,5,576//reduce_divider,96//reduce_divider,True,"HS",1)
]
last_channel=changeSize(1024//reduce_divider)
return MobileNetV3(inverted_setting=inverted_residual_setting,
last_channel=last_channel,
num_classes=num_classes)