文章目录
前言
本文主要记录了一些经典的卷积网络架构,以及相应的pytorch代码。提示:以下是本篇文章正文内容,下面案例可供参考
一、ShuffleNet
1.1 ShuffleNetV1
1.1.1 网络结构
网络整体参数

网络结构

Channel Shuffle操作

1.1.2 论文思路
shuffleNet 主要解决在移动端平台的计算机视觉识别任务。作者发现密集的1*1卷积计算的代价高昂,于是采用分组卷积使通道稀疏连接来减少计算复杂度,但同样,他也减少了组间卷积的信息交流。作为解决,提出了channel shuffle的操作,以增强各个分组间的特征的组合。
分组卷积与channel Shuffle

通过将通道数进行混洗,来加强对应的组间的特征交流和组合。
利用该种操作,作者提出了专门为小型网络设计的ShuffleNet单元,

由于具有通道混洗的逐点分组卷积,可以高效地计算ShuffleNet单元中的所有分量,这也意味着在给定计算预算下,shuffleNet可以使用channel更大的特征图。
同时类似于ResNet的瓶颈结构,作者将瓶颈结构中的通道数设置为输出通道的1/4。
当组数相对较大(例如,g = 8)时,具有信道混洗的模型在性能上优于对应的模型,这表明了跨组信息交换的重要性。
1.1.3 总结与亮点
1.Channel Shuffle
2.修改的网路结构,即使用group conv代替1*1卷积。
1.2 ShuffleNetV2
1.2.1 网络结构
网络整体参数

网络结构

1.2.2 论文思路
作者提出对于度量计算复杂度的常用指标浮点运算数(FLOPs)只是一种间接的指标,通常无法与直接指标如速度或延迟划等号。
比如对与速度有着较大影响的内存访问成本(MAC)就几乎不会对FLOPs有着太大的影响。还有平台也是类似的,并行化程度的不同也会对于相同FLOPs有着不同的效果。
对此作者实验如下

其中Elementwise是指对于单个元素的操作比如RELU激活,concate等。
由此,作者提出了设计高效网络架构的基本原则。
1.相同的通道宽度可最小化内存访问成本(MAC)(输入输出通道数相同)
2.过度的组卷积会增加 MAC;
3.网络碎片化(例如 GoogLeNet 的多路径结构)会降低并行度;
4.元素级运算不可忽视。
基于此作者得出了如何得到一个高效网络架构
1.使用「平衡」的卷积(相同的通道宽度,逐点组卷积)
2.考虑使用组卷积的成本(使用小的分组)
3.降低碎片化程度(减少并行)
4.减少元素级运算(捷径连接)
于是作者对于ShuffleNetV1网络进行改进,得到如下网络结构

即取消组卷积,增加Channel split,然后将Channel Shuffle 移动至Concate之后。(这样可以将Channel Shuffle 和concate以及Relu操作看做一次元素操作)
1.2.3 总结和亮点
1.提出FLOPs不是衡量网络计算复杂度的直接指标
2.提出了设计高效网络结构的原则
3.基于上述原则改进了ShuffleNetV1网络结构
参考文献
1.ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
2.ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design
1.2 代码
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from typing import List,Callable
## channel shuffle 操作
def channel_shuffle(x:Tensor,groups:int)->Tensor:
batch_size,num_channel,height,weight=x.size()
channels_per_group=num_channel//groups
x=x.view(batch_size,groups,channels_per_group,height,weight)
## transpose 会导致tensor不连续,需要使用contiguous
x=torch.transpose(x,1,2).contiguous()
x=x.view(batch_size,-1,height,weight)
return x
class InvertedResidual(nn.Module):
def __init__(self,input_c:int ,output_c:int,stride:int):
super(InvertedResidual,self).__init__()
if stride not in [1,2]:
raise ValueError("illegal stride value")
self.stride=stride
assert output_c%2==0
## 两个分支的特征channel相同
branch_features=output_c//2
assert (self.stride!=1) or (input_c==branch_features<<1)
if self.stride==2:
self.branch1=nn.Sequential(
self.depthwise_conv(input_c,input_c,kernel_size=3,stride=self.stride,padding=3),
nn.BatchNorm2d(input_c),
nn.Conv2d(input_c,branch_features,kernel_size=1,stride=1,bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
else:
self.branch1=nn.Sequential()
self.branch2=nn.Sequential( nn.Conv2d(input_c if self.stride>1 else branch_features,branch_features,stride=1,kernel_size=1,padding=0,bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True),
self.depthwise_conv(branch_features,branch_features,kernel_size=3,stride=self.stride,padding=1),
nn.BatchNorm2d(branch_features),
nn.Conv2d(branch_features,branch_features,kernel_size=1,padding=0,stride=1,bias=False),
nn.BatchNorm2d(branch_features),
nn.ReLU(inplace=True)
)
@staticmethod
def depthwise_conv(input_c:int,output_c:int,kernel_size:int,stride:int=1,padding:int=0,bias:bool=False)->nn.Conv2d:
return nn.Conv2d(input_c,output_c,kernel_size,stride,padding,groups=input_c,bias=bias)
def forward(self,x:Tensor)->Tensor:
if self.stride==1:
## 分成一半
x1,x2=x.chunk(2,dim=1)
out=torch.cat((x1,self.branch2(x2)),dim=1)
else:
out=torch.cat((self.branch1(x),self.branch2(x)),dim=1)
out=channel_shuffle(out,2)
return out
class ShuffleNetV2(nn.Module):
def __init__(self,stage_repeat:List[int],stage_out_channel:List[int],num_classes:int,inverted_residual:Callable[...,nn.Module]=InvertedResidual):
super(ShuffleNetV2,self).__init__()
if len(stage_repeat)!=3:
raise ValueError()
if len(stage_out_channel)!=5:
raise ValueError()
self._stage_out_channels=stage_out_channel
input_channels=3
output_channels=self._stage_out_channels[0]
self.conv1=nn.Sequential(
nn.Conv2d(input_channels,output_channels,kernel_size=3,stride=2,padding=1,bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
input_channels=output_channels
self.maxpool=nn.MaxPool2d(kernel_size=3,padding=1,stride=2)
self.stage2:nn.Sequential()
self.stage3:nn.Sequential()
self.stage4:nn.Sequential()
stage_name=["stage{}".format(i) for i in [2,3,4]]
for name, repeats,output_channels in zip(stage_name,stage_repeat,self._stage_out_channels[1:]):
seq=[inverted_residual(input_channels,output_channels,2)]
for i in range(repeats-1):
seq.append(inverted_residual(output_channels,output_channels,1))
## 设置每stage的结构
setattr(self,name,nn.Sequential(*seq))
input_channels=output_channels
output_channels=self._stage_out_channels[-1]
self.conv5=nn.Sequential(
nn.Conv2d(input_channels,output_channels,kernel_size=1,padding=0,bias=False),
nn.BatchNorm2d(output_channels),
nn.ReLU(inplace=True)
)
self.fc=nn.Linear(output_channels,num_classes)
def _forward_impl(self,x:Tensor)->Tensor:
x=self.conv1(x)
x=self.maxpool(x)
x=self.stage2(x)
x=self.stage3(x)
x=self.stage4(x)
x=self.conv5(x)
x=x.mean([2,3]) ##global pool
x=self.fc(x)
return x
def forward(self,x:Tensor)->Tensor:
return self._forward_impl(x)
def shufflenet_v1_x1_0(num_classes:int=1000):
model=ShuffleNetV2(stage_repeat=[4,8,4],
stage_out_channel=[24,116,232,464,1024],
num_classes=num_classes
)
return model
def shufflenet_v1_x0_5(num_classes:int=1000):
model=ShuffleNetV2(stage_repeat=[4,8,4],
stage_out_channel=[24,48,96,192,1024],
num_classes=num_classes
)
return model
二、EfficientNet
2.1 网络结构
网络整体参数

具体的网络结构如下(MobileNetV3网络结构)

2.1.1 论文思路
本文作者研究了卷积神经网络的模型缩放尺度以及如何平衡网络的深度、宽度和分辨率来得到更好的结果,并提出了一种新的尺度缩放的方法,来统一的缩放所有的维度。
不同的放缩方式如下

从直观上来理解,这种复合增大的方法是有意义的,因为如果输入图像是更大的话,那么网络就需要更多的层来增加感受野并且也需要更多的通道在更大的图像上捕捉更细粒度的图案。
补充:
1.根据以往的经验,增加网络的深度depth能够得到更加丰富、复杂的特征并且能够很好的应用到其它任务中。但网络的深度过深会面临梯度消失,训练困难的问题。
2.增加网络的width能够获得更高细粒度的特征并且也更容易训练,但对于width很大而深度较浅的网络往往很难学习到更深层次的特征。
3.增加输入网络的图像分辨率能够潜在得获得更高细粒度的特征模板,但对于非常高的输入分辨率,准确率的增益也会减小。并且大分辨率图像会增加计算量。
作者通过以下实验发现在相同的浮点计算数(FLOPs)下,同时增加depth和输入图片分辨率大小r时效果最好。

作者在论文中对整个网络的运算进行了抽象
得到了如下的优化问题

而后,作者提出了一个混合缩放的方法,在这个方法中使用了一个混合因子去进行缩放,

1.FLOPs与depth的关系:当depth翻倍时,FLOPs也翻倍。
2.FLOPs与width的关系:当width翻倍,FLOPs会翻四倍
3.FLOPs与resolution的关系:当resolution翻倍,FLOPs会翻四倍
由此可以得到总的FLOPs倍率
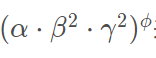
作者在对应的网络上利用NAS来搜索对应的α、β、γ三个参数。
搜索步骤如下:

2.1.2 总结和亮点
1.分析了对于网络缩放的效果,包括网络深度depth,网络宽度channel以及网络的输入图像的分辨率
2.利用NAS来搜索网络的最优参数
参考文献
1.EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
2.EfficientNet网络详解
2.2 代码
import copy
import math
import torch
from typing import List,Callable,Optional
import torch.nn as nn
import torch.nn.functional as F
from torch import Tensor
from collections import OrderedDict
from functools import partial
def _make_divisible(ch:float,divisor:int=8,min_ch=None):
if min_ch is None:
min_ch=divisor
## 将输入的channels 调整到最近的8的整数倍的数值 当ch=12 时为16
new_ch=max(min_ch,int(ch+divisor/2)//divisor*divisor)
## 调整后的channel不能减少超过10%
if new_ch<0.9*ch:
new_ch+=divisor
return new_ch
class ConvBActivation(nn.Sequential):
def __init__(self,in_channel:int,out_channel:int,kernel_size:int=3,stride:int=1,groups:int=1,
norm_layer:Optional[Callable[...,nn.Module]]=None,
activation_layer:Optional[Callable[...,nn.Module]]=None):
padding=(kernel_size-1)//2
if norm_layer is None:
norm_layer=nn.BatchNorm2d
if activation_layer is None:
activation_layer=nn.SiLU
super(ConvBActivation,self).__init__(
nn.Conv2d(in_channel,out_channel,kernel_size=kernel_size,stride=stride,padding=padding,groups=groups,bias=False),
norm_layer(out_channel),
activation_layer(inplace=True)
)
## se 模块,第二个全连接层为block输入的1/4,输出与expand_c相同(inputchannel)
class SqueezeExcitation(nn.Module):
def __init__(self,input_c:int,expend_c:int,sequeeze_factor:int=4):
super(SqueezeExcitation,self).__init__()
squeeze_c=input_c//sequeeze_factor
self.fc1=nn.Conv2d(expend_c,squeeze_c,1)
self.ac1=nn.SiLU(inplace=True)
self.fc2=nn.Conv2d(squeeze_c,expend_c,1)
self.ac2=nn.Sigmoid()
def forward(self,x):
scale=F.adaptive_avg_pool2d(x,output_size=(1,1))
scale=self.fc1(scale)
scale=self.ac1(scale)
scale=self.fc2(scale)
scale=self.ac2(scale)
return scale*x
class InvertedResidualConfig:
def __init__(self,kernel:int,
input_c:int,
out_c:int,
expanded_ratio:int,
stride:int,
use_se:bool,
drop_rate:float,
index:str,
width_coefficient:float
):
##width_coefficient 宽度因子
self.input_c=self.adjust_channels(input_c,width_coefficient)
self.expand_c=self.input_c*expanded_ratio
self.kernel=kernel
self.out_c=self.adjust_channels(out_c,width_coefficient)
self.use_se=use_se
self.stride=stride
self.drop_rate=drop_rate
self.index=index
@staticmethod
def adjust_channels(channels:int,width_factor:float):
return _make_divisible(channels*width_factor,8)
class InvertedResidual(nn.Module):
def __init__(self,
cnf:InvertedResidualConfig,
norm_layer:Callable[...,nn.Module]):
super(InvertedResidual,self).__init__()
if cnf.stride not in [1,2]:
raise ValueError()
self.use_shortcut=(cnf.stride==1 and cnf.input_c==cnf.out_c)
layers=OrderedDict()
activation_layer=nn.SiLU
if cnf.expand_c!=cnf.input_c:
layers.update({
"expand_conv":ConvBActivation(cnf.input_c,cnf.expand_c,kernel_size=1,norm_layer=norm_layer,activation_layer=activation_layer)})
layers.update({
"dwconv":ConvBActivation(cnf.expand_c,cnf.expand_c,kernel_size=cnf.kernel,groups=cnf.expand_c,norm_layer=norm_layer,activation_layer=activation_layer)})
if cnf.use_se:
layers.update({
"se":SqueezeExcitation(cnf.input_c,cnf.expand_c)})
layers.update({
"project_conv":ConvBActivation(cnf.expand_c,cnf.out_c,kernel_size=1,norm_layer=norm_layer,activation_layer=nn.Identity)})
self.block=nn.Sequential(layers)
self.out_channels=cnf.out_c
self.is_stride=cnf.stride>1
## 只有大于0
if cnf.drop_rate>0:
self.dropout=nn.Dropout2d(p=cnf.drop_rate,inplace=True)
else:
self.dropout=nn.Identity()
def forward(self,x:Tensor)->Tensor:
result=self.block(x)
result=self.dropout(result)
if self.use_shortcut:
result+=x
return result
class EfficientNet(nn.Module):
def __init__(self,
width_factor:float,
depth_factor:float,
num_classes:int=1000,
dropout_rate:float=0.2,
drop_connect_rate:float=0.2,
block:Optional[Callable[...,nn.Module]]=None,
norm_layer:Optional[Callable[...,nn.Module]]=None
):
super(EfficientNet,self).__init__()
default_cnf=[[3,32,16,1,1,True,drop_connect_rate,1],
[3,16,24,6,2,True,drop_connect_rate,2],
[5,24,40,6,2,True,drop_connect_rate,2],
[3,40,80,6,2,True,drop_connect_rate,3],
[5,80,112,6,1,True,drop_connect_rate,3],
[5,112,192,6,2,True,drop_connect_rate,4],
[3,192,320,6,1,True,drop_connect_rate,1]
]
## 缩放后的深度
def round_repeats(repeats):
return int(math.ceil(depth_factor*repeats))
if block is None:
block=InvertedResidual
if norm_layer is None:
norm_layer=partial(nn.BatchNorm2d,eps=1e-1,momentum=0.1)
adjust_channels=partial(InvertedResidualConfig.adjust_channels,width_factor=width_factor)
bneck_conf=partial(InvertedResidualConfig,width_coefficient=width_factor)
b=0
num_blocks=float(sum(round_repeats(i[-1]) for i in default_cnf))
inverted_resdual_setting=[]
for stage,args in enumerate(default_cnf):
cnf=copy.copy(args)
for i in range(round_repeats(cnf.pop(-1))):
if i >0:
cnf[-3]=1 ## stride
cnf[1]=cnf[2] ##input_c=output_c
cnf[-1]*=b/num_blocks ##dropout rate
index=str(stage-1)+chr(i+97) ## 1a,2a,2b ## 记录
inverted_resdual_setting.append(bneck_conf(*cnf,index))
b+=1
layers=OrderedDict()
layers.update({
"stem_conv":ConvBActivation(3,adjust_channels(32),kernel_size=3,stride=2,norm_layer=norm_layer)})\
for cnf in inverted_resdual_setting:
layers.update({
cnf.index:block(cnf,norm_layer=norm_layer)})
last_conv_input_c=inverted_resdual_setting[-1].out_c
last_conv_output_c=adjust_channels(1280)
layers.update({
"top":ConvBActivation(last_conv_input_c,last_conv_output_c,1,norm_layer=norm_layer)})
self.features=nn.Sequential(*layers)
self.avgpool=nn.AdaptiveAvgPool2d(output_size=(1,1))
classifier=[]
if dropout_rate>0:
classifier.append(nn.Dropout(p=dropout_rate))
classifier.append((nn.Linear(last_conv_output_c,num_classes)))
self.classifier=nn.Sequential(*classifier)
def _forward_impl(self,x):
x=self.features(x)
x=self.avgpool(x)
x=torch.flatten(x,1)
x=self.classifier(x)
return x
def forward(self,x):
return self._forward_impl(x)
def efficientnet_b0(num_classes=1000):
## input_size 224*224
return EfficientNet(width_factor=1,depth_factor=1,dropout_rate=0.2,num_classes=num_classes)
def efficientnet_b1(num_classes=1000):
## input_size 240*240
return EfficientNet(width_factor=1, depth_factor=1.1, dropout_rate=0.2, num_classes=num_classes)
def efficientnet_b2(num_classes=1000):
## input_size 260*260
return EfficientNet(width_factor=1.1,depth_factor=1.2, dropout_rate=0.2, num_classes=num_classes)
def efficientnet_b3(num_classes=1000):
## input_size 300*300
return EfficientNet(width_factor=1.2, depth_factor=1.4, dropout_rate=0.2, num_classes=num_classes)
def efficientnet_b4(num_classes=1000):
## input_size 380*380
return EfficientNet(width_factor=1.4, depth_factor=1.8, dropout_rate=0.2, num_classes=num_classes)
def efficientnet_b5(num_classes=1000):
## input_size 456*456
return EfficientNet(width_factor=1.6, depth_factor=2.2, dropout_rate=0.2, num_classes=num_classes)
def efficientnet_b6(num_classes=1000):
## input_size 528*528
return EfficientNet(width_factor=1.8, depth_factor=2.6, dropout_rate=0.2, num_classes=num_classes)
def efficientnet_b7(num_classes=1000):
## input_size 600*600
return EfficientNet(width_factor=2.0, depth_factor=3.1, dropout_rate=0.2, num_classes=num_classes)
StochasticDepth
随机深度失活
在训练时使用较浅的深度(随机在resnet的基础上pass掉一些层),在测试时使用较深的深度,较少训练时间,提高训练性能。
优点:
1、这种方法成功地解决了深度网络的训练时间难题。’
2、它大大减少了训练时间,并显着改善了几乎所有数据集的测试错误(CIFAR-10,CIFAR-100,SVHN)
3、可以使得网络更深:随着随机深度,我们可以增加剩余网络的深度,甚至超过1200层,仍然可以在CIFAR-10上产生有意义的测试误差改善(4.91%)
上述代码中就是采用类似dropout的方式去随机对残差结构中的main branch 上进行随机失活已达到这一效果。