前言
本文主要记录了一些经典的卷积网络架构,以及相应的pytorch代码。提示:以下是本篇文章正文内容,下面案例可供参考
一、DenseNet
1.1 网络结构
网络的总体结构:

DenseBlock:

1.1.1 论文思路
概要:
由近期的研究出发,作者发现如果在卷积网络的输入与输出之间添加跳跃链接,那么就可以增加网络的深度,以提高网络的准确率。
作者沿着这个思路,将short path细化为一个更简单的连接模式:
保证层间信息流动的最大化,我们将所有的层与其它层连接。
即每一层将前面的层作为输入,并将其自己的特征图传递到后面的层。
与ResNet不同的是,它并不是求和,而是进行concat操作。
传统的前向结构可以看作一个状态(state),它们在层之间传递。每一层都会读取前面网络层的状态,并传递给下一层。状态改变的同时,也会保存传递的信息。
ResNet的变体表明:很多层对于网络的贡献很少,并且可以被随机的丢弃。
DenseNet网络使得要加到网络的信息和要保存的信息是有差别的。DenseNet的网络结构是很窄的(例如每一层有12个卷积核),仅仅将少部分的特征图添加到信息收集器(collective knowledge),保持其它的信息不变,最终分类器根据所有的网络特征图进行分类预测。
同时DenseBlock 的密集连接有正则化的作用,在小的数据集上具有缓解过拟合的作用。
DenseBlock还改善了网络之间信息和梯度的流动,使得每一层都可以直接与损失函数传回的梯度有联系以及原始的输入信息,形成了隐含的深度监督学习。
详细:
1.Dense Connetivity:
首先ResNet通过相加的方式,可能会阻碍信息在网络中的流通,于是作者将其改为链接方式。
第l层接受前面所有层的特征图,,作为输入
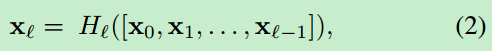
2. Composite Function
这里的H 定义为BN+ReLU+Conv(3x3)
3.Pooling Layers
当特征图大小变化时,无法使用2式,于是将网络分成多个dense block
在相邻层之间添加转换层:
BN+1x1Conv+2x2AveragePooling(通过pooling改变特诊图大小)

4.Growth Rate:
如果每一个产生k个特征图,那么下一层的输入具有k0+k*(l-1)个特征图,k0是输入层特征图数量。我们将k称为增长率。(一个小的k值就能获得较好的网络性能)
(DenseNet的一种解释:dense block每一层都可以获取前面所有特征图,并放入网络的"collective knowledge"。我们可以将特征图视为网络的全局状态。每一层添加k个特征图到这个状态。增长率k决定了每一层有多少新信息贡献到这种全局状态。)(特征重用)
5.Bottleneck Layers:添加11的卷积层来降低输入特征图的数量(在33卷积层之前)
BN-ReLU-1x1Conv-BN-ReLU-3x3Conv(DenseNet-B)
6.Compression:
压缩特征图数量:让转换层(transtiate layer)产生θ*m向下取整个特征图,θ(0,1)。(DenseNet-C)
具体细节:
除了ImageNet数据集,其它所有数据集上,使用三个dense block,每一个具有相同的层。在流入第一个dense block的时候,添加一层卷积,输出通道为16(或者DenseNet-BC模块,大小为2k)。卷积核的大小为3x3,每一边进行零填充一个像素。两个dense block之间使用1x1conv+2x2average pooling。在最后的dense block后,添加全局平均池化和softmax 分类器。三个dense block特征图大小分别为32x32,16x16,8x8。我们使用基本的DenseNet结构,配置如下:{L=40,k=12},{L=100,k=12}以及{L=100,k=24}。对于DenseNet-BC,配置如下:{L=100, k=12},{L=250,k=24}以及{L=190,k=40}。
1.1.2 论文总结和亮点
总结:
1.DenseBlock 结构(特征重用,密集连接,窄的网络结构(较少的特征图))
DenseNet的优点:
1.缓解了梯度消失问题
2.加强了特征传播问题
3.特征重利用
4.极大地减少了参数量
DenseNet的不足:
1.占用显存
1.2 代码
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch import Tensor
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms,datasets
from collections import OrderedDict
from typing import List,Callable,Optional,Tuple,Any
import torch.utils.checkpoint as cp
import torch.nn.functional as F
class _DenseLayer(nn.Module):
def __init__(self,
input_c:int,
growth_rate:int,
bn_size:int,
drop_rate:float,
memory_efficient:bool=False):
super(_DenseLayer,self).__init__()
## bottleneck layer
self.add_module("norm1",nn.BatchNorm2d(input_c))
self.add_module("relu1",nn.ReLU(inplace=True))
self.add_module("conv1",nn.Conv2d(in_channels=input_c,
out_channels=bn_size*growth_rate,
kernel_size=1,
stride=1,
bias=False))
self.add_module("norm2",nn.BatchNorm2d(bn_size*growth_rate))
self.add_module("relu2",nn.ReLU(inplace=True))
self.add_module("conv2",nn.Conv2d(in_channels=bn_size*growth_rate,
out_channels=growth_rate,
kernel_size=3,
stride=1,
padding=1,
bias=False))
self.drop_rate=drop_rate
## 是否使用显存解决的方式,增加训练时间
self.memory_efficient=memory_efficient
## bottleneck layer
def bn_function(self,inputs:List[Tensor])->Tensor:
## 多个特征图
concat_features=torch.cat(inputs,1)
bottlenck_output=self.conv1(self.relu1(self.norm1(concat_features)))
return bottlenck_output
@staticmethod
def any_requires_grad(inputs:List[Tensor])->bool:
for tensor in inputs:
if tensor.requires_grad:
return True
return False
## 使得方法不被编译 部署时
@torch.jit.unused
def call_checkpoint_bottleneck(self,inputs:List[Tensor])->Tensor:
def closure(*inp):
return self.bn_function(inp)
## pytorch 的 checkpoint 是一种用时间换显存的技术,
# 一般训练模式下,pytorch 每次运算后会保留一些中间变量用于求导,
# 而使用 checkpoint 的函数,则不会保留中间变量,
# 中间变量会在求导时再计算一次,因此减少了显存占用,
# 跟 tensorflow 的 checkpoint 是完全不同的东西。
return cp.checkpoint(closure,*inputs)
def forward(self,inputs:Tensor)->Tensor:
if isinstance(inputs, Tensor):
prev_features = [inputs]
else:
prev_features = inputs
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("memory efficient not supported in JIT")
bottleneck_output=self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output=self.bn_function(prev_features)
new_features=self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate>0:
new_features=F.dropout(new_features,p=self.drop_rate,training=self.training)
return new_features
class _DenseBlock(nn.ModuleDict):
def __init__(self,
num_layers:int,
input_c:int,
bn_size:int,
growth_rate:int,
drop_rate:float,
memory_efficient:bool=False):
"""
:param num_layers: DenseBlock 的层数
:param input_c: 输入channel
:param bn_size: 瓶颈层的乘法因子,论文中为生成4*k个所以默认为4
:param growth_rate: 每个layer输出的channel数
:param drop_rate:
:param memory_efficient: 是否是显存节省模式
"""
super(_DenseBlock,self).__init__()
## 每一层都是输入都有前面所有的特征图
for i in range(num_layers):
layer = _DenseLayer(input_c + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self,init_features:Tensor)->Tensor:
features=[init_features]
for name,layer in self.items():
new_features=layer(features)
features.append(new_features)
return torch.cat(features,1)
## 转换层
class _Transition(nn.Sequential):
def __init__(self,input_c:int,output_c:int):
super(_Transition,self).__init__()
self.add_module("norm",nn.BatchNorm2d(input_c))
self.add_module("relu",nn.ReLU(inplace=True)) ## 论文中没有
self.add_module("conv", nn.Conv2d(input_c,
output_c,
kernel_size=1,
stride=1,
bias=False))
self.add_module("pool", nn.AvgPool2d(kernel_size=2, stride=2))
class DenseNet(nn.Module):
def __init__(self,
growth_rate:int=32,
block_config:Tuple[int,int,int,int]=(6,12,24,16),
num_init_features:int=64,
bn_size:int=4,
drop_rate:float=0,
num_classes:int=1000,
memory_efficient:bool=False
):
super(DenseNet,self).__init__()
## 第一层的卷积层
self.features=nn.Sequential(OrderedDict([
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]))
## each denseBlock:
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(num_layers=num_layers,
input_c=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
##//2 实验中取θ为0.5
trans = _Transition(input_c=num_features,
output_c=num_features // 2)
self.features.add_module("transition%d" % (i + 1), trans)
num_features = num_features // 2
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
self.classifier = nn.Linear(num_features, num_classes)
## 初始化权重
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self,x:Tensor)->Tensor:
features = self.features(x)
out = F.relu(features, inplace=True)
## global 全局池化层
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out
def densenet121(**kwargs: Any) -> DenseNet:
# Top-1 error: 25.35%
# 'densenet121': 'https://download.pytorch.org/models/densenet121-a639ec97.pth'
return DenseNet(growth_rate=32,
block_config=(6, 12, 24, 16),
num_init_features=64,
**kwargs)
def densenet169(**kwargs: Any) -> DenseNet:
# Top-1 error: 24.00%
# 'densenet169': 'https://download.pytorch.org/models/densenet169-b2777c0a.pth'
return DenseNet(growth_rate=32,
block_config=(6, 12, 32, 32),
num_init_features=64,
**kwargs)
def densenet201(**kwargs: Any) -> DenseNet:
# Top-1 error: 22.80%
# 'densenet201': 'https://download.pytorch.org/models/densenet201-c1103571.pth'
return DenseNet(growth_rate=32,
block_config=(6, 12, 48, 32),
num_init_features=64,
**kwargs)
def densenet161(**kwargs: Any) -> DenseNet:
# Top-1 error: 22.35%
# 'densenet161': 'https://download.pytorch.org/models/densenet161-8d451a50.pth'
return DenseNet(growth_rate=48,
block_config=(6, 12, 36, 24),
num_init_features=96,
**kwargs)
二、RegNet
2.1 论文思路
传统NAS方法这种基于个体估计(individual network instance)的方式(每次评估的时候采样一个网络)存在以下缺陷:
1). 非常不灵活。(各种调参大法)
2).泛化能力差。
3).可解释性差。(搜出来的效果虽好,但是很多都是大力出奇迹,运气成分+1)。
由此作者提出了要对网络设计空间进行整体估计。
非常直观的,如果我们能够得到深度(depth),宽度(width)等等一系列网络设计要素关于网络设计目标的函数关系,那么我们就能很轻松的知道大概多深的网络,多宽的网络是最佳选择。
具体的估计方法如下:
1.从任意的搜索空间采样一堆模型。为了方便快捷,这些模型都是小模型并且只训了10个epoch
对于评价标准,作者采用了EDF

2.采样空间:
作者将采样空间称为AnyNet,其包含了几乎所有的网络设计要素,比如depth,width,group之类的。一般来说,正常的神经网络都只包含4个stage,对于anynet中的4个stage的网络设计要素的选择几乎是任意的,因此叫AnyNet。并且由于network stem和head在网络设计中不太重要,AnyNet主要面向network body的设计。
但即使如此,搜索空间依旧很大(高达10的18次)。
为了减少搜索空间,作者加了一些控制变量,比如说每个stage共享某个参数之类的。
于是提出了A,B,C,D,E五种不同的设计空间。这五个设计空间充满了控制变量法的statistics,A:就是任意的空间,B:在A的观察基础上固定每个stage的bottleneck ratio,C:在B的观察基础上固定每个stage的group数量,D:在C的观察基础上逐stage增宽网络(width),E:在D的观察基础上逐stage加深网络(depth)。
由上述方式通过实验可以进一步建模最佳搜索空间(RegNet Design Space)
通过获得的几个变量和每个block的index之间,可以拟合出函数关系,就此建模好了大概每层的block多宽多深之类的关系,建模方法叫做quantized linear parameterization。
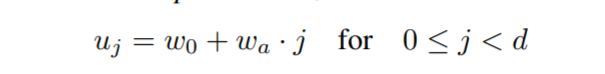
w0 表示初始化的宽度, wa 是斜率,d表示深度,
为了量化uj(简单地说就是算出来的宽度可能是126.123之类的奇葩数字,得给它四舍五入到128这种科学的数字,同时每个stage i有很多层,得把宽度统一到某个数字),这里再引入了两组公式和新的超参 wm 用于计算量化因子 sj :

相关的一些结论:
1.无论模型多大,20个block的深度是最合适的。大网络越深越好是不对的。
2.bottleneck ratio设置成1是最好的。
3.width multiplier设置成2.5是最优质的。
4.剩下的初始网络宽度,group数量,宽度的增长斜率,这些随着模型增大而增加会是最佳选择。
关于复杂度的结论:
首先这里定义了一个所有卷积层输出tensor的大小叫做activations(这玩意你不管用啥卷积,出来tensor一样大这个值就不变):

再是几个关于非常常见的一些设计比如inverted bottleneck以及depthwise conv的结论。首先前者稍微降低了点EDF(评价指标),后者就还不如group conv。但是scaling the input image resolution是依然有用的。再说SE module,这玩意也有用。
WM((两个阶段之间的宽度)