双流网络的开篇之作,使用图像和光流两个分支训练,最终综合两个分支得到最终结果。
被NIPS 2014接收
论文地址:https://arxiv.org/abs/1406.2199
1. 摘要
本文研究了用于训练视频中行为识别的深度卷积网络架构。主要的挑战在于捕捉静态帧中的外观和连续帧间的运动的互补信息。本文基于两个分开的识别流(时间和空间),最后通过融合将它们结合在一起。空间流从静态的视频帧中执行行为识别,同时时间流从密集光流形式的运动中训练以识别行为。本文提出的架构与two-streams假设有关,根据该假设,人类视觉皮质包含两条路径:腹侧流(识别目标)和背侧流(识别运动)。
本文主要贡献:
- 首先,本文提出了一个two-stream卷积网络架构,这个架构由时间和空间网络构成。
- 然后验证了,尽管是有限的训练数据集,在多帧密集光流上训练的卷积网络仍然能够表现出很好的性能。
- 最后展示出,应用于两个不同的动作分类数据集的多任务学习,可以同时用来增加训练数据集的数量和提高性能。
2.本文方法
2.1 网络结构
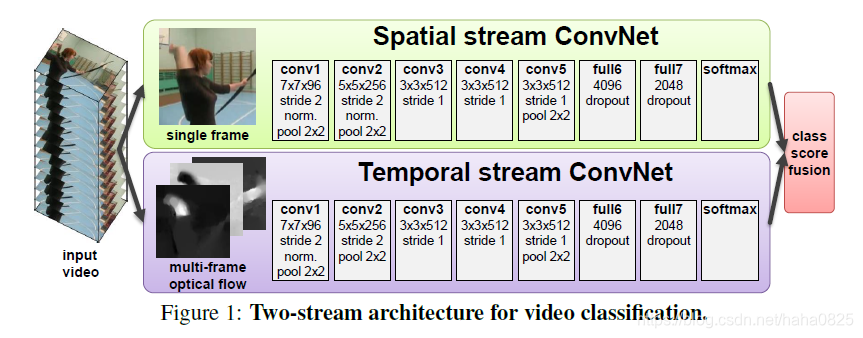
视频很自然的被拆解为空间和时间部分。在空间部分,以单个帧的外观形式,传递了视频描绘的场景和目标信息。在时间部分,以多帧的运动形式,传递了观察者(摄像机)和目标者的运动。因此设计的网络架构如图所示:
网络分为两个流。每一个流都由一个深度卷积网络来实现,最后它们通过softmax进行融合。这里考虑了两种融合方法:一个是求平均; 另一个则是在多分类线性SVM上训练,使用L2正则化的softmax计算得分。
2.2 空间流卷积网络
空间流卷积网络在单个视频帧上执行,能有效地在静止图像中进行动作识别。其自身静态外表是一个很有用的线索,因为一些动作很明显地与特定的目标有联系。
另外,由于空间流卷积网络本质上是一个图像分类架构,所以可以依赖于一些大型图像识别方法,在大型图像分类数据集上预训练网络。
2.3 光流卷积网络
模型的输入是几个相邻帧之间叠加的光流位移场。这样的输入准确地描述了视频帧之间的运动信息,这使得识别更加容易,并且网络不需要估计隐式的运动。
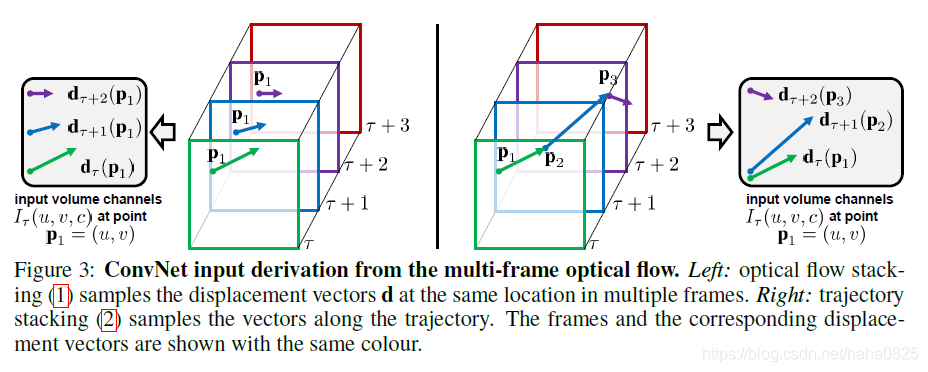
本文考虑了几个基于光流输入的变体,如下图所示:

optical flow可以看作是在连续的帧t和帧t+1之间的一组displacement vector fields(每个vector用dt表示)组成的,其中dt是一个向量,表示第t帧的displacement vector,是通过第t和第t+1帧图像得到的。dt(u,v)表示在帧t的位置(u,v)的位移矢量,它表示移动到下一个帧t+1相对应的点。dt包含水平部分dtx和竖直部分dty,可以看图中的(d)和(e)。因此如果一个video有L帧,那么一共可以得到2L个channel的optical flow,然后才能作为temporal stream convnet网络的输入。
图中的(a)和(b)表示连续的两帧图像,(c)表示一个optical flow,(d)和(e)分别表示一个displacement vector field的水平和竖直两部分。
2.3.1 光流卷积网络的输入
假设一个video的宽和高分别是w和h,那么Figure1中temporal stream convnet的输入维度是这样的: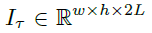 。其中τ表示任意的一帧。
。其中τ表示任意的一帧。
对于怎么得到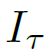 ,文章主要介绍了两种计算方式,分别命名为optical flow stacking和trajectory stacking,这二者都可以作为前面temporal stream convnet网络的输入。
,文章主要介绍了两种计算方式,分别命名为optical flow stacking和trajectory stacking,这二者都可以作为前面temporal stream convnet网络的输入。
(1)optical flow stacking
计算公式:
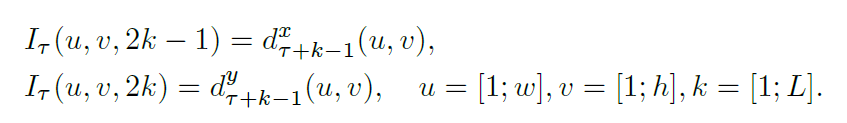
分别是水平和竖直方向的的计算公式,其中(u,v)表示任意一个点的坐标。因此 Iτ(u,v,c) 存的就是(u,v)这个位置的displacement vector。如图3左图所示。
(2)trajectory stacking
计算公式:
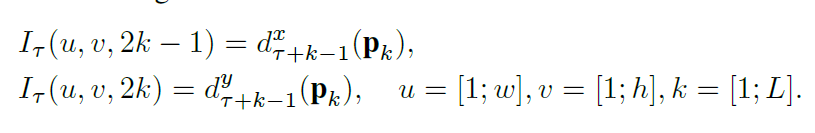
其中Pk表示沿着这条轨迹的第k个点。因此 Iτ(u,v,c) 存的就是着轨迹(如图3右图所示)在位置pk抽样的vectors。
2.4 多任务学习
spatial stream convnet因为输入是静态的图像,因此其预训练模型容易得到(一般采用在ImageNet数据集上的预训练模型),但是temporal stream convnet的预训练模型就需要在视频数据集上训练得到,但是目前能用的视频数据集规模还比较小(主要指的是UCF-101和HMDB-51这两个数据集,训练集数量分别是9.5K和3.7K个video)。因此作者采用multi-task的方式来解决。
首先原来的网络(temporal stream convnet)在全连接层后只有一个softmax层,现在要变成两个softmax层,一个用来计算HDMB-51数据集的分类输出,另一个用来计算UCF-101数据集的分类输出,这就是两个task。这两条支路有各自的loss,最后回传loss的时候采用的是两条支路loss的和。
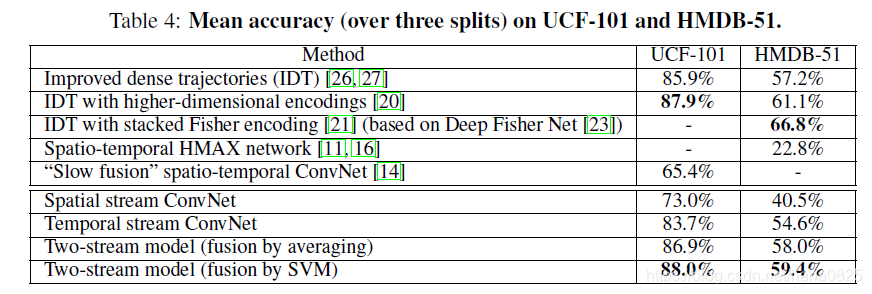
3. 实验
- optical flow stacking的效果要优于trajectory stacking
- temporal stream convnet的效果要优于spatial stream convnet,这说明对于action recognition而言,motion information更为重要。

- 和其他的方法对比