深度传感器通过提供三维人体骨骼数据和场景的深度图像,为处理人体动作识别问题提供了可能性。基于三维骨架数据的人体动作分析由于其鲁棒性和视图不变性的表现形式而成为近年来研究的热点。然而,仅凭骨架不足以区分涉及人与物交互的行为。在本文中,我们提出了一个深度模型,有效地模拟了视点变化下的人-对象交互和类内变化,首先,引入人体部位模型,将人体部位的深度表象转换为一个视图不变的共享空间。其次,提出了一种能有效结合骨骼图像和深度图像中视不变的身体部位表示,学习人体部位与环境对象之间的关系、人体不同部位之间的相互作用以及人体动作的时间结构的端到端学习框架,我们在NTU RGB+DUWA3DII两大基准人类动作识别数据集上对15种现有技术进行了评估。的实验结果表明,我们的技术提供了一个显着改进的最新方法。
视频中人类动作的自动识别是一个重要的研究课题,在智能监控、健康医药、体育娱乐等领域有着广泛的应用。深度相机,比如微软Kinect已经成为这项任务的热门,因为深度图像对光照、衣服颜色和纹理的变化具有鲁棒性,而且由于实时人体骨骼跟踪框架的发展,可以从单一深度图像中提取出三维人体关节位置。
基于深度传感器的人体动作识别研究大致可以分为三类:骨架数据[6,12,25,33,34,38,40],深度图像和基于深度骨骼的方法。虽然基于深度的方法在大多数RGB-Depth动作识别数据集上取得了令人印象深刻的结果,但在人类显著改变其空间位置和活动的时间范围时,它们的表现急剧下降。另一方面,在动作识别中局限于基于骨架特征的学习并不能提供较高的识别精度,因为会出现深度视觉人体部件的外观提供了有区别的信息,并且大多数通常的人类行为都是基于身体与其他物体的相互作用来定义的。例如,喝酒和吃零食的动作有一个非常相似的骨骼运动。因此,需要额外的信息,比如深度图像,来区分这些动作。结合深度和骨架数据(特征融合)的直接方法是将这些不同类型的特征连接起来[19,35,36]。通过这种方式,实现特征的最优组合,这样就不能保证实现特征的最优组合来进行准确的分类。
此外,一个实用的系统应该能够从新颖的和看不见的观点识别人类的行为(概括)。然而,与3D骨骼数据不同,深度图像的viewinvariant表示是一项具有挑战性的任务[20 - 22,24]。这是因为,当从不同的视角观察时,一个人执行一个动作的深度图像看起来是完全不同的。因此,如何将这些深度图像有效地表示在视不变空间中,并与估计的三维骨架数据相结合,是一个有待探索的重要研究问题。
此外,在人类的动作中,身体的关节会成群地一起移动。每一组可以看作是一组身体部位,动作可以解释为不同身体部位的相互作用。因此,需要利用与不同行动相对应的最具区别性的互动,以便更好地识别。此外,人类行为可能具有特定的时间结构。动作视频的时间结构建模也是动作识别问题的关键。目前大多数基于深度传感器的方法[23,33 - 36]对视频的时间变化进行建模。傅里叶时间金字塔(FTP)和/或动态时间扭曲(DTW),导致两步系统的性能通常比端到端系统[9]差。其他一些方法[6,12,25]使用递归神经网络(RNNs)或扩展,如长短期记忆(LSTM)网络,用于建模动作视频的时间变化。但是,CNN+RNN/LSTM模型引入了大量的附加参数,因此需要更多的训练视频,而这些视频的标签成本很高。本文提出了一种基于深度和骨架数据的人类动作深度识别模型,以应对端到端学习框架中的上述挑战。首先,我们提出了一个深度CNN模型,它将人体部位的深度外观转移到一个共享的视不变空间。学习这个深度CNN需要一个大的数据集,包含从多个角度观察不同动作的各种人体部位。Rahmani等人[23]表明,在合成深度人体图像上学习的模型可以推广到真实深度图像,而不需要进行微调。因此,我们从不同的角度合成人体的各个部位,从而生成一个大型的训练数据集。更重要的是,我们提出一个框架,它能够有效地将信息从深度和骨骼数据,2)捕捉人类的身体部位和环境之间的关系对象,3)模型之间的交互不同人类的身体部位,和4)在一个端到端的学习人类行为的时间结构。我们的主要贡献包括以下三个方面。首先,本文提出了一个视图不变的人体部位外观表示模型。其次,我们提出了一种端到端学习的人类动作识别模型,通过实验表明,该模型很好地适用于基于深度传感器的人类动作识别任务。第三,该方法同时学会了将不同模式的特征结合起来。深度和骨架,捕捉人体不同部位对不同动作的交互作用,并对不同动作的时间结构进行建模。
该方法在NTU RGB+D[25]和UWA3D两个大型基准数据集上进行了评价多视图活动II[20]数据集。第一个数据集包含了由三个Kinect摄像头从三个不同视角同时捕获的56K多个序列,第二个数据集包含了从四个不同视角捕获的30个人类动作。这个数据集具有挑战性,因为视频是由Kinect摄像头从四个不同的视角在四个不同的时间捕捉到的。我们大量的实验结果表明,该方法能够取得一个明显更好的识别精度与目前的先进方法。
近年来,人类行为识别从不同的方面进行了探索。在本节中,我们限制我们的回顾到最近的相关方法,这可以分为三个不同的类别,即深度,骨架和骨架深度视频的方法。
深度视频:现有的基于深度视频的动作识别方法大多使用全局特征,如轮廓和时空体积信息。例如,Oreifej和Liu[15]提出了一种扩展定向三维法线直方图的时空深度视频表示方法[30]到4D,加上时间导数。Yang和Tian[39]对HON4D进行了扩展,他们将每个像素的局部邻域的4D法线连接起来作为描述符。但是,这些方法不是视图不变的。最近,Rahmani等人[23]提出了一种合成人体姿态深度训练数据的方法,用于训练一个能将从不同视角获得的人体姿态转换到视图不变空间的CNN深度模型。他们使用群稀疏傅里叶时间金字塔编码人类行为的时间变化。当人的空间位置发生显著变化,或活动的时间范围[15]发生显著变化时,这种整体方法可能会失败。还有一些方法[20,21,37]使用检测到一组兴趣点的局部特征,然后从每个兴趣点的局部邻域提取深度特征。例如,DSTIP[37]通过抑制翻转噪声来定位深度视频中与活动相关的兴趣点。当动作执行速度大于传感器噪声引起的信号翻转时,这种方法可能会失败。最近,Rahmani等人[20,21]提出了直接处理动作视频对应的点云序列的方法。根据计算原理,提出了一种视图不变兴趣点检测器和描述符每一点的成分分析(PCA)是一个计算昂贵的过程[23]。然而,这些方法使用手工制作的特性,并隐式地假定视点不会发生显著的改变。
骨骼视频:基于单一深度图像[28]的实时人体骨骼跟踪技术的发展,可以利用关节[38]或身体部位[33]的位置动力学对运动模式进行有效的编码。例如,Yang和Tian[38]使用每一帧的两两3D关节位置差和每一帧之间的时间差来表示一个动作。Zanfir等人提出了一个用于捕捉姿态和骨骼关节的运动姿态描述符。Vemulapalli等人[33,34]利用旋转和平动来表示李群中身体部位的三维几何关系,然后采用动态时间翘曲(DTW)和傅里叶时间金字塔(FTP)模型的时间动力学。为了避免使用手工设计的特征,基于深度学习的方法也被提出。例如,HBRNN[6]分割了整个骨骼。通过层次网络神经网络对五组节点进行分析。最终的隐藏表现
将RNN馈入softmax分类器层进行动作分类。差动式LSTM[32]在LSTM内部引入了一个新的门控来发现显著运动模式中的模式。Shahroudy等人[25]提出了对LSTM的部分感知扩展,将LSTM的内存单元拆分为基于部分的子单元,推动网络学习每个部分的长期上下文表示。网络的输出通过连接的基于部件的存储单元学习,然后是公共输出门。最近,Liu等[12]引入了时空LSTM来联合学习关节之间的时空关系。
骨骼深度视频:虽然基于骨骼的方法在人类动作数据集上取得了令人印象深刻的动作识别精度,但仅仅使用骨骼数据来建模动作是不够的,特别是当动作有非常相似的骨骼运动和包括主体和其他物体之间的交互[36]。因此,基于骨架深度的方法正成为描述交互活动的一种有效方法。Rahmani等人[19]提出了一组随机森林来融合时空深度和关节特征。Wang等人[36]提出计算动作视频每帧中每个关节周围固定区域的占用模式直方图。在时间维度上,采用低频傅里叶分量作为分类特征。最近,Shahroudy等人[27]提出了分层混合规范来融合不同特征,选择信息最丰富的体关节。我们提出的方法也属于这一类。然而,与上述工作不同的是,我们提出的方法也属于这一类。然而,与上述工作不同的是,本文中提出的框架对于视点中的重大变化是健壮的。此外,该模型在端到端学习框架中学习人体部位与环境对象之间的关系以及动作的时间结构。
本节介绍了一个使用深度摄像机的视不变人动作识别模型。所提议的架构如图1所示。基于深度图像和估计的3 d联合的立场,我们提出一个新的模型,可以1)人类的身体部位转移到一个共享view-invariant空间,2))捕捉人体部位与环境对象之间的关系,进行人机交互;3)在端到端学习框架中学习动作的时间结构。文中给出了该体系结构的详细信息。
人类的身体部分的表示
在本节中,我们将介绍两种表示身体部件骨架信息的方法(第3.1小节)。以及人体各部位的深度外观的转移(第3.1.2小节)到共享视图不变。身体部分骨骼表示给定一个执行动作的人体姿态的骨骼数据,通过将髋关节中心放置在原点,所有的三维关节坐标将从现实坐标系转换为以人为中心的坐标系。这个操作使得骨骼不变性到场景中人的绝对位置。给定一个骨架作为参考,所有其他的骨架在不改变关节角的情况下进行归一化,使其身体部分的长度与参考骨架的长度相等。这种规范化使得骨架的规模不变性。骨架也被旋转,这样向量的地面投影,从左髋关节到右髋关节,是平行于全局x轴的。这种旋转使骨架视图不变性。
如图2所示,让年代-V, Eqq人体骨架,在V-tv1, v2,, vN✉代表的身体关节,和E-te1, e2,, eM✉表示身体部位的集合。Vemulapalli等人[33]证明,一对人体部件en和em的相对几何可以用附加于oth的局部坐标系表示,采用最小旋转法计算身体局部坐标系,使其陈述关节成为原点,与x轴重合。然后,我们可以计算翻译向量,~ dm, n-tq,旋转矩阵,Rm, n,从新兴市场到局部坐标系(en)。因此,em和en在时间实例t上的相对几何关系可以用usi来描述

使用对身体部位之间的相对几何,我们代表着身体在时间t实例使用Ci-ei tq✏-P1,我-tq, P2,我-tq,...,π✁1,我-tq,₁,我-tq,...,下午,我.tqq PSE-3 q✂...✂SE-3 q,在SE-3 q表示特别的欧氏集团和M是身体部位的数量。然后,ei身体部分的表示在时间t实例,Ci♣tq,特殊欧几里得的映射组李代数的向量表示
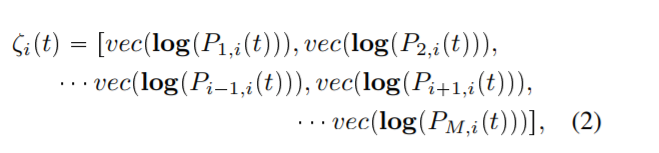
其中log为常用的矩阵对数。身体部分的我一次实例t,tq是一个向量的维度6-M-1 q。因此,我们表示每个身体部分在时间t 6-M-1问维向量(如所示:
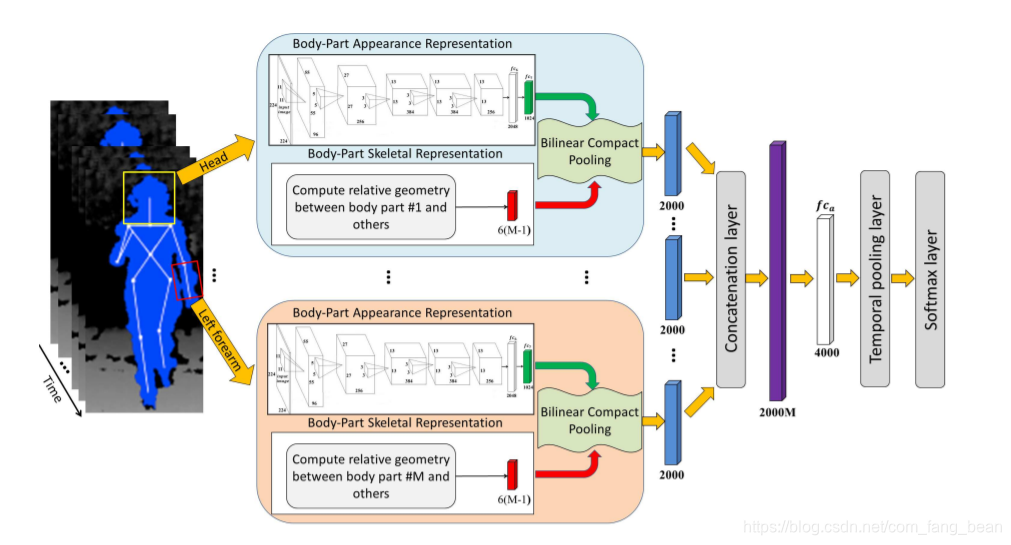
图1:提议的模型的架构。给定一组深度图像及其对应的骨架数据,计算出身体各部分与其他部分之间的相对几何关系(见3.1.1节)。将包含人体部位的边界盒通过同一个人体部位外观表示模型(见3.1.2节)提取视不变深度信息(fc7层的输出)。然后,双线性紧凑池应用于每个身体部分的骨骼和外观表示(参见第3.2.1节),从而产生了一个紧凑的2000维特征,:紧凑的特征向量的身体部分是连接到从2000✂M维向量,然后通过一个全层,葬礼,编码不同的人类身体部位之间的相互作用(参见3.2.2节)。最后,将与深度帧序列相对应的4000维特征向量序列通过时间池化层(见3.2.3节)提取固定长度的特征向量进行分类。
不同于3D骨骼,视图不变深度外观表示人体部分是具有挑战性的。这是因为从不同的角度观察人体各部位的深度图像会有很大的不同。为了克服这个问题,我们学习了一个单一的深度CNN模型,为所有人体部位转移到一个共享的视不变空间。但是学习这样一个深度的CNN需要一个包含大量人体部位的大型训练数据集,从多个角度观察各种动作。我们的解决方案是生成合成训练数据,因为Rahmani和Mian[23]表明,在合成深度图像上训练的模型能够泛化真实深度图像,而不需要再训练或对模型进行微调。所有可能的人类行为的集合,因此,身体部分的外观是非常大的。因此,我们提出了一种选择最具代表性人体部位的方法。我们使用的CMU动作捕捉数据库[2]包含,超过200K的姿势的主题表演各种各样的动作。然而,许多身体部位即使对于不同的动作也是非常相似的。为了找到最具代表性的身体部位,我们首先使用上一节给出的方法对mocap骨架数据进行归一化。我们以连接髋中心和脊柱的三维矢量为参考。以身体部件为参考所需的旋转被用作身体部件的特征,利用欧氏在欧拉角[10]之间的距离上,采用k-means聚类方法独立地对身体各部分特征进行聚类。鉴于人体各部位的运动程度不同,我们对不同部位提取了不同数量的簇。该算法得到了480个具有代表性的人体部件。
为了生成所选身体部位的深度图像,我们首先使用开源的MakeHuman软件[3]来合成不同的真实感3D人体形状,并使用开源的Blender软件包[1]来将3D人体形状匹配到动作捕捉数据中。然后,整个人体相应480个有代表性的身体部件由108个不同呈现。

图2:由20个关节和19个身体部位组成的示例骨架。边界框显示感兴趣的区域,对应于不同的身体部位。
使用ent视点和包含有代表性身体部位的边界框作为训练数据。总的来说,480年✂108年深度图像对应于480年代表身体部位生成从108种不同的看法。请注意,适当选择了包含身体部分的边界框的长度和宽度,以覆盖整个身体部分。例如,我们将左手周围的边框的长度和宽度设置为身体部分长度的两倍,这是因为人类通常通过手和脚与环境进行互动,比如物体和其他人。因此,更大的边框能够覆盖手和对象。例如,图1所示为执行动作的人的头部和左前臂对应的两个边界框,图2所示为示例骨架的19个身体部位对应的边界框。我们提出了一个视图不变的人体部位表示模型,该模型学习将人体部位从任何视图转移到共享的视图不变空间。模型为deep convolutional neural network (CNN),其架构如下:

代表一个卷积层与内核大小k✂k, n过滤器和一个跨步的年代,P-k,平方是最大池大小的内核层k✂k和跨年代,n是一个归一化层,RL修正线性单元,F C-nq与n过滤器和完全连接层D♣rq辍学层辍学比r。我们将全层称为f c6, f c7和f c8,分别。在学习过程中,在网络的末端添加一个softmax损失层。生成的合成深度图像对应。:每个代表我身体,我-1,,480年,108年从所有观点被分配相同的类标签我。因此,我们的训练数据集由480个人类bodypart类。我们使用从[23]得到的全人体深度图像训练的模型初始化所提出的CNN的卷积层。我们通过反向传播对所提出的CNN模型进行微调,卷积层的初始学习率为0.001,全连接层的初始学习率为0.01。我们使用了0。9的动量和0。0005的重量衰减。我们训练网络进行30K次迭代。训练完成后,将最后的全连接层(fc8)和softmax层移除,剩下的层如图1,作为视图不变的body-part外观表示模型。
学习端到端人类动作识别模型:
到目前为止,我们已经分别将人体部位对应的骨骼数据和深度图像表示为两种不同的视不变空间,即Lie代数和fc7。
然而,一个人的动作是通过移动身体的各个部分和它们之间的相互作用来完成的。为了考虑到这些信息,我们提出了一个端到端的学习模型,如图1所示。每个步骤的细节如下:
双线性紧凑池层:
双线性分类器取两个向量x1 prn1和x2 prn2的外积,学习模型W,即z-Wrx1❜x2,❜x1x2表示外部产品T和r。s表示用向量将矩阵线性化。因此,两个向量x1和x2的所有元素以乘法的方式相互作用。然而,向量的外积x1和x2, n1和n2很大时,结果在一个不可行的参数学习w .为了克服这个问题,高et al。Gao等人[8]提出了一种单模态的双线性紧凑池,该池将外积投影到较低维空间,同时避免了直接计算外积。这个想法是基于的张量素描算法。
让x属于 R6^(M-1)和x属于 R1024表示特征向量从身体获得骨架(3.1.1节)和外观(3.1.2节)表示模型的第i个身体部分在时间t,分别。我们在x上应用双线性紧凑池-智商年代-tq和x-智商d-tq结合高效和意味深长地。我们设置投影维数d为2000。这个过程的结果是一个2000维的特征向量为每个身体的部分。
全连接层
为了编码人体不同部位之间的相互作用,我们建议首先将将所有M个身体部件的特征向量组成一个2000维的特征向量,然后通过4000个单元组成的全连通层。因此,该模型为动作视频中的每幅深度图像提取一个4000维的特征向量。
颞池层
直接的基于cnn的视频编码方法是在帧上应用时间最大池或时间平均池。然而,这种时间池方法不能捕捉视频的时变信息。为了克服这个问题,我们使用最近提出的秩池操作符
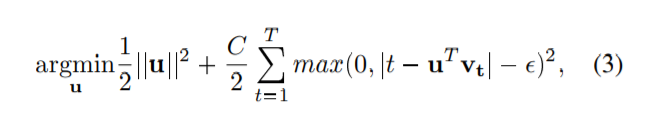
在vt P R4000表示f ca层对应的输出帧在时间t, ~ v-v1,, vTq表示序列的特征向量和u的固定长度表示视频用于分类。
这个时间等级池化层试图通过找到一个向量u来捕获序列中元素的顺序,这样uT vi➔u我➔j T vj,可以解决使用正规化的支持向量回归(SVR)在E。
分类层的目的是给序列描述符u分配一个动作类标签。在这个工作中,我们使用软最大分类器。给定一个数据集video-label对t♣~ x♣智商y♣智商q✉n i✏1,我们联合估计时间池化层Eq.(3)和软最大分类函数的参数如下:
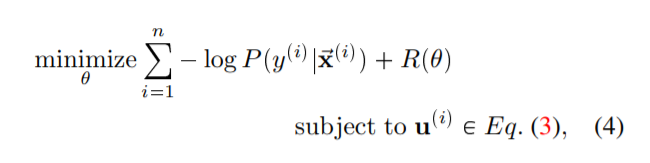
soft-max叉损失分类器和R♣θq是ℓ2-norm正则化模型的参数。式(4)是一个二层优化问题,通过链式法则[7]计算其对模型中任意参数的导数。我们使用随机梯度下降(SGD)来联合学习所有的参数。
我们在NTU RGB+D[25]和UWA3D两个大型基准数据集上评估了我们提出的模型多视图活动II[20]。我们比较我们的实验,到最先进的动作识别方法,包括比较编码描述符(CCD)[5],定向梯度的直方图(HOG2))[14],区别的虚拟连续虚拟路径(CVP)方向4D法线(HON4D)[15]的直方图,Actionlet集合(AE)[36],李代数相对对(LARP)[33, 34],超法向向量(SNV)[39],定向三维点云直方图(HOPC)[20],层次递归神经网络、STALSTM[29]、具有信任门的时空LSTM(ST-LSTM+TG)[12]、人体位姿模型加时态建模(HPM+TM)[23]、长期运动动力学(LTMD)[13]、Lie组深度学习(LieNet) [9]。基线结果来自于他们的原始论文或[12,23]。
除了其他比较方法,我们报告了我们定义的基线方法的准确性,包括:
基线1(仅限外观):在我们提出的架构中,大小为2000的向量被它们对应的身体部分外观表示所取代,
•基线2(仅骨骼):在我们提出的架构中,大小为2000的向量被它们对应的身体部分骨骼表示所取代,
•基线3(用于编码时间变化的最大池化):级别池化层被最大pooli取代
•基线4(用连接代替双线性池):提出的视图不变的身体部件外观表示通过连接层与相应的骨架表示结合,然后是完全连接的和级别池化层
我们使用MatConvNet工具箱[31]作为深度学习平台。我们使用随机梯度下降训练网络,并设置学习速率、动量和体重衰变10✁3
、0.9和5✂10✁4,分别。对于完全连接的层,我们也使用0.5的dropout率。值得注意的是,我们将提出的视不变视觉身体部件表示模型的学习率设置为零。这是因为我们已经学习了使用合成训练深度图像来将人体部分图像转换为视图不变spac的模型。
NTU RGB+D动作识别数据集
这个数据集[25]是目前最大的基于深度的动作识别数据集。它由Microsoft Kincet v2收集,包含60个动作类,包括日常动作、成对动作和医疗状况,由40个受试者从三种不同的视角执行。图3显示了来自这个数据集的示例框架。数据集包含超过56000个序列。类内部和视点的巨大变化使这个数据集非常具有挑战性。这个数据有两个标准的评估协议[25],包括crosssubject和cross-view。按照跨受试者协议,我们将40名受试者分为训练集和测试集。每个集合包含从不同视图中获取的样本,这些视图由20个受试者执行。按照[25]中的cross-view协议,我们使用相机1和2的所有样本进行训练,其余相机的样本进行测试表1显示了该数据集上各种方法的性能。该方法的识别精度显著优于我们所定义的基线和所有现有方法。我们定义的基线方法在交叉主题和交叉视图设置上的精度都低于我们提出的方法。验证了该方法的特征融合和端到端学习的有效性。
由于该数据集为深度模型的训练提供了丰富的样本,因此基于rnnm的方法如ST-LSTM+TG[12]具有较高的准确率。然而,我们的方法比ST-LSTM+TG[12]在cross-subject和cross-view设置中分别提高了6%和5.4%的准确率。这一结果表明了我们的方法在处理大规模数据中视点变化等问题上的有效性。

需要强调的是,本文提出的人体部件外观表示模型(第3.1.2节)是从少量人体姿态生成的人体部件的合成深度图像中学习而来的。从NTU RGB-D数据集[25]中搜索许多人类动作/姿势,如戴眼镜、自拍、输入关键字、撕纸,在CMU动作捕捉数据集中没有返回任何结果,该数据集用于训练身体部位的出现:状态表示模型。但该方法具有较高的分类精度。例如,佩戴眼镜、自拍、输入关键字和撕纸的准确率分别为90.1%、85.6%、80.0%和85.7%。




相识在行动。此外,在俯视图中,由于遮挡,身体的下部没有被正确地捕获。图4显示了从4的观点。 我们遵循[20]并使用来自两个视图的样本作为训练数据,使用来自其余视图的样本作为测试数据。表2总结了我们的结果。我们提出的模型在所有视图对上的性能都明显优于目前最先进的方法。基于深度的方法,如HOPC[20]、CCD[5],以及基于深度+骨架的方法,如HON4D [15]
SNV[39]和Actionlet[36]是低的,因为许多动作的深度在视图变化时看起来非常不同。然而,我们的方法获得了84.2%的平均识别准确率,比最接近的竞争对手HPM+TM[23]提高了约7.3%。图5比较了我们提出的方法和最近的竞争对手HPM+TM[23]的类特定动作识别精度。该方法在除起立外的所有动作类上都取得了较好的识别精度。例如,在饮酒和接听电话方面,我们的方法比HPM+TM[23]方法分别提高了24%和20%的准确率。这是因为我们提出的模型能够捕捉人体部位和环境物体之间的相互作用。
注意,对于UWA3D多视图中的许多操作例如抱胸,抱头,憋住,打喷嚏和咳嗽,在CMU动作捕捉数据集中没有类似的动作。但是,我们的方法对这些动作仍然有很高的识别精度。这证明了该模型的有效性和泛化能力。结论我们提出了一个从深度和骨架数据识别动作的端到端学习模型。该模型学习了从深度和骨骼数据融合特征,捕捉身体部件之间的交互和/或与环境对象的交互,并在端到端学习框架中建模人类行动的时间结构。为了使我们的方法对视点变化具有鲁棒性,我们引入了一个深度CNN,它将从不同的未知视点获取的人体部位的视觉外观传输到视点不变空间。在两个大型基准测试上进行实验。