文章目录
前言
论文标题:Two-Stream Convolutional Networks for Action Recognition in Videos
论文网址:https://arxiv.org/abs/1406.2199
备注:本文内容顺序与原论文并不完全一致,是对于该论文的精读与总结,如需更多细节请参考原论文。
视频是一个很好的数据来源,比 2D 这种单一的图像能包含更多的信息,比如有物体移动的信息,还有长期的时序信息,也有音频信号等等,人眼看到的信号也都是连续的,即以视频形式展现的,所以做视频领域的学习非常符合当今多模态的趋势。
本文收录于 2014 年的 NIPS (NeurIPS),是在视频领域中应用深度学习的开山之作,但早在 2014 年 CVPR中的一篇论文 Large-scale Video Classification with Convolutional Neural Networks (发表在本文之前) 已经把深度学习用到视频分类任务中了,其中也提出了一个非常大的数据集 Sports-1M,有 100 万个视频,但最后训练出的模型效果差强人意,在当时常见的数据集上做测试,它的效果甚至不如之前手工设计的特征。双流卷积网络第一个让卷积神经网络的效果和之前基于最好的手工提取特征的方法打成平手的模型,从而使视频理解领域在今后也基本都是使用深度学习的方法。
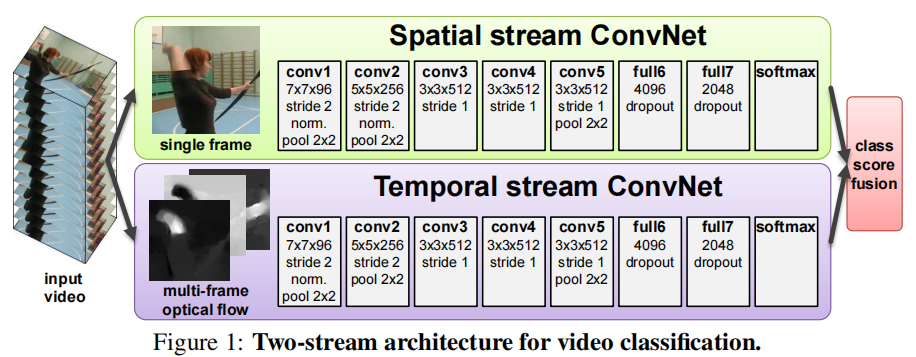
对于一个 2D 图像分类的任务来说,当有一个单张图片时,只要把它扔给一个卷积神经网络就可以了,然后过几层 Conv 和 FC,最后就可以得到分类的结果,也就是 Figure 1 中上半部分(黄绿色部分)的流程。但如果现在的输入是视频,而不是单一的图片,那又应该怎么利用卷积神经网络呢?
在早期的一些工作中,要么就是在视频中抽取一些关键帧出来,然后把这些帧一个一个通过卷积神经网络,最后再把结果合并;要么就是把这些帧叠起来,当做整体的一个输入扔给卷积神经网络,然后在网络中做一些 early fusion 或 later fusion (相关讲解:early fusion VS later fusion),达到一种时空学习的效果,但这些工作的效果都差强人意,甚至比不上之前手工设计的特征。
- early fusion:先将不同的特征融合在一起,再使用分类器对其进行分类,这个融合过程发生在特征之间,一般称之为特征融合或 “early fusion” 。
- later fusion:不同的特征使用不同的分类器,得到基于每个特征的分类结果,再对所有结果进行融合(可能是投票、加权平均等),这个融合发生在不同特征分类结果之间的融合,称为 “later fusion” 或 “decision fusion”。
作者认为,之所以用一个神经网络无法处理好这种视频问题,是因为卷积神经网络比较擅长学习局部的特征,而不擅长去学习视频中这种物体的移动规律。于是作者想要 “教” 卷积神经网络学,既然无法处理这种 运动信息 (Motion Information),那么就先帮网络把这个运动信息提取出来,即 Figure 1 中的光流法 (多帧光流,multi-frame optical flow) ,那么就只需要神经网络学习从最开始的输入光流到最后的动作分类之间的映射。学习这种映射正是深度卷积神经网络最擅长的,它通过一系列的矩阵乘法去学习输入到输出之间的映射关系。
光流法:
- 一个非常有效的用来描述物体运动的特征表示,通过提取光流可以把背景等这种不必要的噪声全都忽略,而只提取到动作运动的状态,能很好的描述运动信息。
- 相关资料:计算机视觉–光流法(optical flow)简介,计算机视觉项目实战-背景建模与光流估计(目标识别与追踪)
以上两个卷积神经网络的共同作用下,使得动作识别的精度大大提升。如 Figure 1 所示,作者把关注空间信息的神经网络称为 空间流卷积神经网络 (Spatial stream ConvNet),把关注运动信息的卷积神经网络称为 时间流卷积神经网络 (Temporal stream ConvNet)。空间流的输入是单帧的图片,最后输出一个分类的概率;时间流的输入是一系列的光流图片,最后也输出一个分类的概率,然后把这两个分类概率取加权平均,就能得到最终的预测概率。
0 摘要
作者研究了如何使用深度卷积神经网络来做视频中的动作识别,这个问题的难点就在于如何能够同时获取两种信息,一种是从静止的图像上获得外观的信息(如形状,大小,颜色,整个的场景信息等等),另一种就是物体的运动信息(视频中的时序信息),这两种信息对于视频理解都至关重要。作者希望把之前最好的手工特征中蕴含的思想带入到深度学习这种数据驱动的框架中,从而既能学到外观信息,也能学到运动信息。
本文中作者的贡献有三点:
- 提出了一个双流卷积神经网络 (two-stream ConvNet),由一个空间流卷积神经网络和一个时间流卷积神经组成。
- 证实了即使只有少量训练数据的情况下,一个直接在光流数据上训练的神经网络也能取得很好的效果。
- 为了弥补训练数据的不足,使用多任务学习 (multi-task learning) 的方法,在两个不同的动作分类数据集上同时训练一个 backbone,这样不仅 backbone 训练得很好,而且在这两个数据集上都能有效地提高性能。
本文的模型是在 UCF-101 和 HMDB-51上进行训练和测试的,模型性能和 SOTA (state of the art) 打成平手,而且其效果远远超过之前尝试用深度学习去做视频分类的方法。
1 Introduction
视频中的动作识别是一项具有挑战性的任务,在研究界得到了广泛的关注。 与静止图像的分类相比,视频的时序信息可以为识别工作提供了额外的重要线索,很多动作都可以单独靠运动信息来可靠地识别出来。 另外,视频能为单个图像(视频帧)提供一个很好的自然的数据增强,因为在一个视频中,同一个物体会经历各种各样的形变、遮挡、光照的改变,总之这些改变是非常多样且自然的,远比我们以往去做生硬的数据增强(如 cutout等等)要好得多。
在本工作中,作者将深度卷积神经网络扩展到视频动作识别,这是一种最新的静态图像表示方法。这项任务最近在 Large-scale Video Classification with Convolutional Neural Networks 中通过使用堆叠的视频帧作为网络的输入来解决,但结果比最好的手工设计的特征要差得多。作者发现,之前手工设计的特征基本都是在光流上去提取特征的,它能非常好地获取运动信息。于是作者提出了两个独立的卷积神经网络,即空间识别流和时间识别流,然后通过 late fusion 的方式结合得到最终的结果。这样做有两个好处:① 对于空间流来说,现在的输入就是单张图片,所以可以用 ImageNet 上预训练好的模型来做初始化,接下来的优化也就更容易做;② 对于时间流来说,因为是直接用光流来做输入,从而去识别动作,所以卷积网络本身已经不用去学运动信息了。作者是从人脑视觉系统中受到启发,人类的视觉皮层包含两个通路:ventral stream (处理物体识别) 和 dorsal stream (识别运动)。
1.1 相关工作
视频识别的研究在很大程度上是由图像识别方法的进步推动的,一般都是先有图像上的方法,再把这些方移植或扩展到视频中来处理视频数据。大量的视频动作识别方法都是基于局部时空特征的浅层高维编码。例如,Learning Realistic Human Actions from Movies 的算法包括检测稀疏的时空兴趣点 (spatio-temporal interest points),然后使用局部的时空特征 (spatio-temporal features)来描述这些兴趣点:定向梯度直方图 (Histogram of Oriented Gradients,HOG) 和光流直方图 (Histogram of Optical Flow,HOF)。 然后,这些特征被编码到 Bag Of Features (BOF) 表示中,该表示在几个时空网格上集合(类似于空间金字塔集合),并与 SVM 分类器结合。 在后来的工作中,表明局部特征的密集抽样优于稀疏兴趣点。
最先进的浅层视频表征利用了密集点轨迹 (dense point trajectories),也就是利用了视频前后帧点和点之间的联系,而不是在时空立方体上计算局部视频特征。 在 Action Recognition by Dense Trajectories 中就是先算出光流,然后利用光流找到对应的轨迹,再在轨迹周围去提取特征,且效果非常好。然后还有很多的改进工作,如 Action Recognition with Improved Trajectories 提出了 IDT 特征,IDT 当时能和很多深度神经网络相竞争。
也有许多尝试开发视频识别的深度学习网络。在大多数这些工作中,网络的输入是连续的视频帧,想让模型能够自己去学习这种与运动相关的时空特征,但一系列工作证明这是一个非常难的任务。Large-scale Video Classification with Convolutional Neural Networks 比较了几种用于动作识别的卷积神经网络结构,而且还收集了一个大型数据集 Sports-1M,该数据集包括 110 万个体育活动的 YouTube 视频,有趣的是,该作者发现如果把这些视频帧一张一张的输给 2D 的网络,就和把一系列的视频帧输给 3D 的网络时,它们的效果是差不多的,说明这种形式的时空学习并没有获取到物体的运动信息。把这个模型在 Sports-1M 预训练好的模型拿来在 UCF-101 上进行 fine-tune,模型性能比 SOTA 的手工特征的结果低了 20% 的精确度。
2 用于视频识别的双流结构
视频可以自然地分解成空间部分和时间部分。空间部分主要是外观信息,用来描绘场景及物体的信息。时间部分就是运动信息,描述物体是如何运动的。基于此作者设计了双流结构,空间流学习空间特征,时间流学习运动特征,最后的结果通过 late fusion 合并就得到了最终的预测。作者提供了两种 late fusion 方法:① 加权平均;② 在得到的堆叠的L2归一化的 softmax 分数上,把它当成特征,再去训练一个 SVM 去做分类。
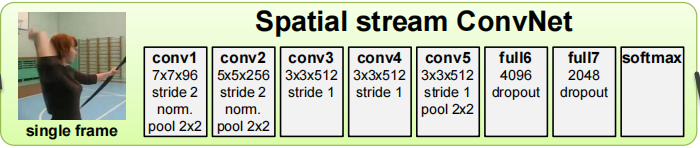
空间流卷积神经网络: 拿视频帧一帧一帧的作为输入,也就是从静止的图像中去做动作识别,其实就是一个图像分类任务。静止的外观信息本身就是一个非常有用的信息,因为很多动作与特定的物体相绑定(比如打球,弹琴等等),只要模型识别到了这些物体基本就能判别出动作。作者在后续的实验中,证明了基于静止图像的视频分类本身就具有相当的竞争力。而且用这种单帧的图像作输入,就可以用 ImageNet 做预训练,一般如果能够在足够大的数据集上预训练,然后在小的数据集(如 UCF-101)上做 fine-tune 的话,效果就会好很多。
3 光流卷积神经网络(时间流)

Figure 2: 光流。(a)(b):一对连续的视频帧,其中移动的手周围的区域用青色矩形勾勒。 ( c ) (c) (c):勾勒区域密集光流的特写 (光流可视化);(d):光流在位移向量场的水平分量 d x d^x dx (高强度对应正值,低强度对应负值)。 (e):竖直分量 d y d^y dy。 注意 (d) 和 (e) 如何突出移动的手和弓。ConvNet 的输入包含多个流。
假设 (a)(b) 图像的大小为 240×320,那么这两个图像输入的维度就是 240×320×3,这两帧的图会得到一张光流的图,即 ( c ) (c) (c),这个光流图的维度就是 240×320×2 (这个 2 表示水平上和竖直上两个维度),(d)(e) 分别是 ( c ) (c) (c) 的水平分量和竖直分量,它们都是 240×320×1 的张量。
其中,原始帧与得到的光流图的 size 是一样的,每个像素点都会计算出一个光流值。每两个连续帧都会得到一个光流图,若视频有 L L L 帧,则会得到 L − 1 L - 1 L−1 个光流图。
3.1 ConvNet 输入配置
如何利用光流?一个简单的方式就是通过视频的前后帧算出一个光流,把这个光流通过一个 2D 的网络,也就是做一个图像分类任务,只不过是把一个 RGB 帧换成了 一个光流。但作者认为这样做的意义不大,因为他希望模型能够学习物体的运动信息(视频中的时序信息),之前的手工特征往往都需要 10 帧或者 16 帧来算运动信息,那么转移到深度学习也是如此,不能只用一张光流图,而要把多张光流图叠在一起,也就是说时间流神经网络的输入是多个光流图叠加在一起的。作者在这里讨论了两种叠加的方法:
- 简单直白地直接把光流图叠加在一起(Figure 3 左图)
- 根据光流的轨迹,在轨迹上进行光流数值的叠加(Figure 3 右图)
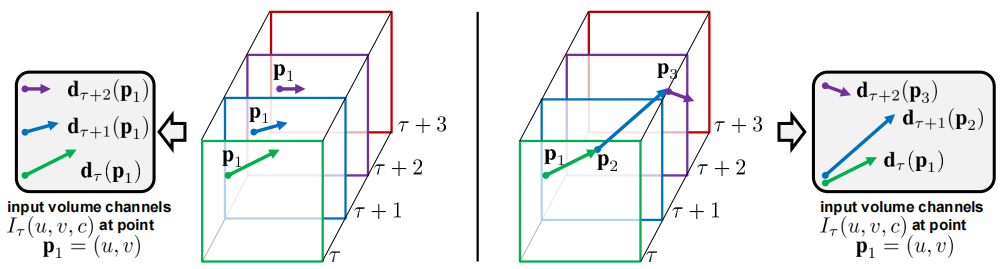
Figure 3: 从多帧光流导出的ConvNet输入。左边:光流叠加 (下文公式 ( 1 ) (1) (1)) 在多个帧中对同一位置的位移矢量 d d d 进行采样。右边:轨迹叠加 (下文公式 ( 2 ) (2) (2)) 沿着轨迹采样向量。帧和相应的位移矢量以相同的颜色显示。
如 Figure 3 左图所示,是光流图叠加的方法。因为这些光流图已经是要进入网络的输入了,所以他们都已经经过 resize,因此图中都是正方形,也就是 224 × 224 224×224 224×224,然后将这些光流图 stack,也就是说这个网络的输入实际上都是在对应的同样的点的位置上去取光流,对于每一张光流图来说,每次都是询问同一个点下一帧往哪走,如图中即是每次都寻找 P 1 P_1 P1 位置在下一帧中的位置来取光流值。这种方法的好处就是简单,不需要做任何的预处理和后处理,直接把光流图叠在一起,但这样很可能没有充分利用光流的信息。
如 Figure 3 右图所示,是轨迹叠加的方法。当我们知道上一张图的某个点 P 1 P_1 P1 在下一帧已经移到 P 2 P_2 P2 时,在下一张光流图里就找 P 2 P_2 P2 在下一帧里所对应的位置,而不像左图的方法每次都在 P 1 P_1 P1 的位置取光流的值。这种方法听起来很合理,很好地利用了光流的信息,可惜的是通过本文的实验发现左图的方法是要比右图的方法好一些,这是令人费解的。
以上两种叠加方法的详细解释:
光流叠加(Optical flow stacking): 稠密光流可以看作是连续帧 t t t 和 t + 1 t+1 t+1之间的一组位移向量场 d t d_t dt。我们用 d t ( u , v ) d_t(u,v) dt(u,v) 表示在 t t t 帧中的点 ( u , v ) (u,v) (u,v) 处的位移向量,它从该点移动到下一帧 t + 1 t+1 t+1 中的对应点。向量场的水平分量和垂直分量 d x t d_x^t dxt 和 d y t d_y^t dyt 可以看作图像通道(如图2 (d) (e) 所示),非常适合使用卷积网络进行识别。 为了表示一序列帧的运动,我们将 L L L 个连续帧的流道 d t x , y d_t^{x,y} dtx,y 叠加,形成总共 2 L 2L 2L 个输入通道。 更准确地说,令 w w w 和 h h h 是一个视频的宽度和高度,对于任意帧 τ τ τ,构造了一个 ConvNet 的输入 I τ ∈ R W × H × 2 L I_τ∈ℝ^{W×H×2L} Iτ∈RW×H×2L,如下所示:
I τ ( u , v , 2 k − 1 ) = d τ + k − 1 x ( u , v ) , I τ ( u , v , 2 k ) = d τ + k − 1 y ( u , v ) , u = [ 1 ; w ] , v = [ 1 ; h ] , k = [ 1 ; L ] . (1) \tag{1} I_τ(u, v, 2k − 1) = d^x_{τ+k−1}(u, v),\\ I_τ(u, v, 2k) = d^y_{τ+k−1}(u, v),\ u = [1; w],\ v = [1; h],\ k = [1; L]. Iτ(u,v,2k−1)=dτ+k−1x(u,v),Iτ(u,v,2k)=dτ+k−1y(u,v), u=[1;w], v=[1;h], k=[1;L].(1)
对于任意点 ( u , v ) (u,v) (u,v),通道 I τ ( u , v , c ) , c = [ 1 ; 2 L ] I_τ(u,v,c),\ c=[1;2L] Iτ(u,v,c), c=[1;2L] 编码在 L L L 个帧的序列上该点的运动(如 Figure 3 左侧所示)。
轨迹叠加(Trajectory stacking): 受基于轨迹的描述符 (Action recognition by dense trajectories) 的启发,另一种运动表示——取样于运动轨迹,代替了在几个帧的相同位置采样的光流。在这种情况下,输入 I τ I_τ Iτ,对应于帧 τ τ τ,采用以下形式:
I τ ( u , v , 2 k − 1 ) = d τ + k − 1 x ( p k ) , I τ ( u , v , 2 k ) = d τ + k − 1 y ( p k ) , u = [ 1 ; w ] , v = [ 1 ; h ] , k = [ 1 ; L ] . (2) \tag{2} I_τ(u, v, 2k − 1) = d^x_{τ+k−1}(p_k),\\ I_τ(u, v, 2k) = d^y_{τ+k−1}(p_k), u = [1; w], v = [1; h], k = [1; L]. Iτ(u,v,2k−1)=dτ+k−1x(pk),Iτ(u,v,2k)=dτ+k−1y(pk),u=[1;w],v=[1;h],k=[1;L].(2)
其中 p k p_k pk 是沿轨迹的第 k k k 个点,从帧 τ τ τ中的位置 ( u , v ) (u,v) (u,v) 开始,由以下递推关系定义:
p 1 = ( u , v ) ; p k = p k − 1 + d τ + k − 2 ( p k − 1 ) , k > 1. p_1 = (u, v);\ p_k = p_{k−1} +d_{τ+k−2}(p_{k−1}), k > 1. p1=(u,v); pk=pk−1+dτ+k−2(pk−1),k>1.
与输入表征 ( 1 ) (1) (1) 相比,其中通道 I τ ( u , v , c ) I_τ(u,v,c) Iτ(u,v,c) 存储位置 ( u , v ) (u,v) (u,v) 处的位移向量,输入表征 ( 2 ) (2) (2) 存储沿轨迹(如 Figure 3 右侧所示)在位置 p k p_k pk 处采样的向量。
双向光流(Bi-directional optical flow): ( 1 ) (1) (1) 和 ( 2 ) (2) (2) 都只处理了前向光流,即帧 t t t 的位移场 d t d_t dt 指定其像素在下一帧 t + 1 t+1 t+1 中的位置。既然连续帧可以从 a 到 b,那么也可以反过来从 b 到 a。作者既计算了前向光流也计算了后向光流,为了能和前两种方法做对比,选取了 L L L 帧长的视频,用前半段计算前向光流,后半段计算后向光流,这样得到的就也是 2L 个 channel。
总之,大体的流程就是,给定 L + 1 L+1 L+1 帧的视频,就会得到 L L L 个光流图,这 L L L 个光流图就是一个张量 I τ ∈ R W × H × 2 L I_τ∈ℝ^{W×H×2L} Iτ∈RW×H×2L,然后把这个张量作为时间流卷积神经网络的输入。
如 Figure 1 所示,时间流网络的结构和空间流网络基本是一样的,都是 5 层 conv 再接 2 层 FC,最后 softmax 出结果,只不过是第一个卷积层的输入维度与空间流不一样。空间流的输入维度是 3 channel (RGB 3 个 channel),时间流的输入维度为 2L channel (本文中一般使用 11 帧作为输入,也就是说会得到 10 个光流图,那么这个输入 channel 就是 2 × 10 = 20 2\times 10=20 2×10=20,其中这些光流图叠加的顺序是:先叠加水平部分的光流位移,再叠加竖直方向的光流位移,即 x 1 , x 2 , . . . , x L , y 1 , y 2 , . . . , y L x_1,x_2,...,x_L,y_1,y_2,...,y_L x1,x2,...,xL,y1,y2,...,yL,叠加后的维度即是 224 × 224 × 2 L 224×224×2L 224×224×2L)。得到空间流和时间流两个 softmax 分数后做个 late fusion (对其求加权平均),再做 argmax 就能得到分类结果。
该模型最关键的就是引入了时间流,巧妙地利用光流信息来提供视频中的运动信息,而不需要神经网络自己学习这种运动信息。
4 实现细节
4.1 测试
在测试时,无论视频有多长,都从视频中 等间距地采样 25 帧(在 UCF-101 和 HMDB-51 数据集中,它们的视频长度基本都是在 5-7 秒,因此取出的这 25 帧之间的时间间隔还是比较短的,图像变化也不是很大)。然后,对于每一帧中,通过裁剪获得四个角和中心,这样一张图就变成了 5 张图,然后对原始帧翻转,再在翻转后的图像上裁剪获得四个角和中心,这样也得到了 5 张图,所以最后是由 1 张图变成了 10 张图,那么对于一个视频 (25 帧) 来说,最终也就是得到了 250 张图。然后每张图都会通过一个 2D 的空间流神经网络得到结果,那这 250 张图得到的结果直接取平均就得到了最终的预测。
对于时间流神经网络,也是先取得 25 帧,然后分别从这 25 帧的位置开始,往后连续地取 11 帧,通过这 11 帧会得到 10 张光流图,再把这些光流图传给时间流神经网络,最后再把所有的结果去平均
当空间流和时间流都得到最终的预测结果后,再把两个流的结果做 late fusion,即加权平均,就得到了最终整个网络的预测结果。
4.2 光流
预测光流的算法参考于 High accuracy optical flow estimation based on a theory for warping,使用 GPU 实现,计算的还是比较快的,如果计算前后帧这一对儿帧的光流的话只需要 0.06s,但由于数据集中帧数比较大,所以提取光流是一件非常耗时的事。比如 UCF-101 有 1万多个视频,假设是 1万个视频,每个视频 10秒,每秒 30 fps,那么需要 10000 × 10 × 30 × 0.06 s = 50 h 10000×10×30×0.06s=50h 10000×10×30×0.06s=50h,这就已经很耗时了,如果是 Sports-1M 这种有 一百多万个视频,且视频时间更长,这样的话就更费时了。
图像中每一个像素点都有光流位移的值,所以它是一个密集 (dense) 的表示,如果把它都存起来的话也是非常占空间的,对于 UCF-101 这种不大的数据集来说都需要 1.5T 的硬盘空间。这里作者提出了一个改进,既然占用空间多是由于 dense 的特征,于是作者希望把它变成 sparse (稀疏的):像 RGB 图像做压缩,把这些光流的值都 rescale 到 [ 0 , 255 ] [0,255] [0,255] 的区间,并也变成整数,直接把光流图存成 JPEG 形式的图片,这样直接从原来的 1.5T降到了 27GB。
光流计算速度慢,且占用空间大,一直都是被人诟病的,所以后续也有很多工作尝试改进光流的计算,或者直接舍弃了光流。
5 实验
5.1 在 UCF-101 上单流 ConvNet 的对比和消融实验
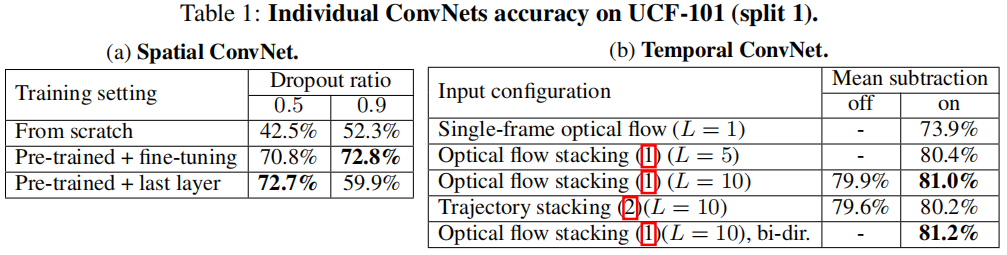
如 Tabel 1 所示,分别做了 空间流 ConvNet 和 时间流 ConvNet 的消融实验。
(a) Spatial ConvNet
空间流网络如果是随机初始化从头开始训练的话,即不使用预训练 (表中 From scratch),无论 dropout 是 0.5 还是 0.9,效果都只有 50% 左右,如果用了预训练,那么效果就提升到了 70% 多,其中 Pre-trained + fine-tuning 指整个网络做微调,Pre-trained + last layer 指只在最后一层做微调 (骨干网络的参数都冻结)。因为当时的数据集都比较小,考虑到会不会过拟合,所以这里尝试了不同的 dropout ratio。当整个网络做微调时,数据集太小就容易过拟合,这时就需要设置一个比较大的 dropout ratio。当只有最后一层做微调时,就不太需要担心过拟合,这里 dropout ratio 设为 0.5 时就比较好,而 dropout ratio 设为 0.9 时,就有太多的信息丢失了。当后来有个大型数据集之后,研究者们基本就是用 Pre-trained + fine-tuning 的方式了。
(b) Temporal ConvNet
时间流网络这里主要对比了是光流堆叠 (Optical flow stacking) 好,还是轨迹堆叠 (Trajectory stacking) 好,以及双向光流 (Bi-directional optical flow) 的效果。baseline 是只使用一张光流图,也就相当于再做图像分类任务,这个效果只有 73.9%。随后作者逐渐增加光流图的数量 L L L,这里增加到了 5 和 10,性能都逐渐提高了,估计作者这里没有在表中继续增加光流图的数量可能是因为继续增加后模型性能没有提高或硬件配置不够了。然后当 L = 10 L=10 L=10 时,比较了 光流堆叠 和 轨迹堆叠,这两种方法都差不多,光流堆叠的效果相对更好一点。在第五行中,证明了双向光流是有效果的。
5.2 在 UCF-101 和 HMDB-51 上的对比实验
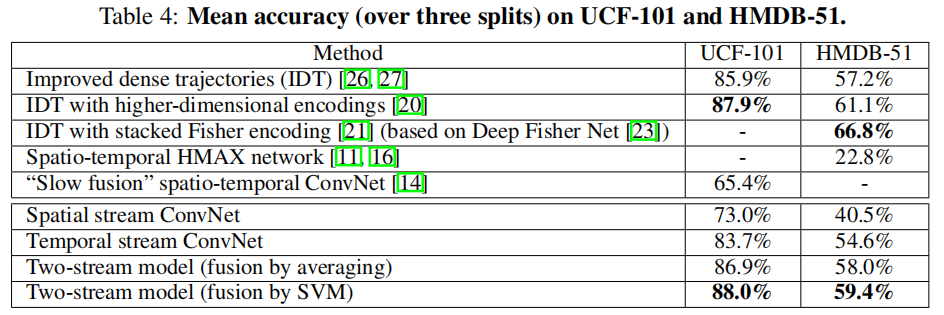
第一行是当时最好的手工特征 Improved dense trajectories (IDT),二三行就是在 IDT 的基础上加了一些全局信息,让特征更适合做视频,所以结果比单纯的 IDT 更高一些。四五行是之前用深度学习的方法去做视频分类的效果,这个效果就很差。
第六行是空间流卷积神经网络,使用了 ImageNet 上的预训练模型,所以它的表现已经比之前的深度学习方法还要好。第七行是时间流卷积神经网络,它的效果就很好了,时间流网络的输入是光流,第一层的维度是 20,因为维度与 ImageNet 预训练模型不匹配,并没有利用预训练模型,只是在小型数据集上从头开始训练这个模型,但意外的是它的效果特别好,可见运动信息对于视频理解非常重要。第八行是将空间流和时间流直接取平均做 late fusion,它的效果就已经超过单纯的 IDT 了。第九行是 late fusion 部分用一个 SVM 来代替,在 UCF-101 上达到了 88%,超过了用全局 encoding 的 IDT 的 87.9%,在 HMDB-51 上虽然不如用全局信息的 IDT,但也证明了卷积神经网络在视频分类任务中的有效性。在随后的几年内,用深度学习方法在 UCF-101 做测试就基本达到了98%左右,所以本文对于视频分类任务的发展是非常重要的。
6 结论及改进方向
本文提出了一个用深度学习做视频分类的方法,能和之前最好的手工特征打成平手,该模型结合了空间流和时间流,且都是用了 ConvNet (卷积神经网络)。时间流的效果非常的好,比在视频帧上训练的网络要好很多,而且是在没有预训练的情况下。本文的方法虽然使用了光流,但实现并不复杂,既不需要 3D 网络,也不需要 LSTM 等,可以直接利用现有的 2D 网络,只需要把第一层的输入维度改变一下就行了,也不需要大量的手工调整。
改进思路:
- 既然空间流网络中使用预训练的效果比不使用预训练的要好很多,那么时间流网络也可以尝试下使用预训练的网络。或者也可以尝试在大型数据集上进行训练,这样训练的网络应该也会好一些,但提取光流的速度和占用空间太大了。
- 基于轨迹的方法 (Trajectory stacking) 在实验中表现的并不好,按理来说应该比 Optical flow stacking 要好一些,所以这也是未来的一个研究方向。
- 很多视频中会带有相机本身的运动 (camera motion),而不是背景不动只有物体动,这样就会影响光流的计算,会导致光流计算不准,网络学习运动信息时也会有偏差。在本文中用了减均值的方法,稍微减弱了相机移动带来的影响。而之前的那些手工特征都考虑了很多如何处理相机移动带来的影响,效果也都不错,因此在深度学习方法中也应该考虑如何处理这些相机移动的影响。
7 总结
本文的贡献不仅仅是额外使用了时间流 ConvNet 的工作,也给提供了一种思路,当发现神经网络不能很好的解决问题时,仅仅魔改模型或改目标函数没办法很好地解决,不如给模型提供一些先验信息 (如本文中的光流),既然模型学不到,就帮它学,往往能大幅简化任务。当一个神经网络解决不了问题时,可以考虑下用多个网络,利用别的数据,用别的模型做这种多流网络,因为这些网络是互补的所以效果一般都会提升。