算法介绍
双流网络使用以单帧RGB作为输入的CNN来处理空间维度的信息,使用以多帧密度光流场作为输入的CNN来处理时间维度的信息,并通过多任务训练的方法将两个行为分类的数据集联合起来(UCF101与HMDB),去除过拟合进而获得更好效果。
贡献
- 提出two-stream ConvNet来对时空特征进行建模表示
- 提出了多帧光流作为输入,对性能提升作用很大
源码
未公开源码
光流
- 图像中物体的运动可以用密集光流场来可视化描述,为了是cnn网络对motion建模,堆叠多帧光流作为输入,训练网络是一种可行的方法
- 光流描述了运动的矢量,因此在可视化时,可以分别可视化x和y两个方向
下图为光流的具体表示:

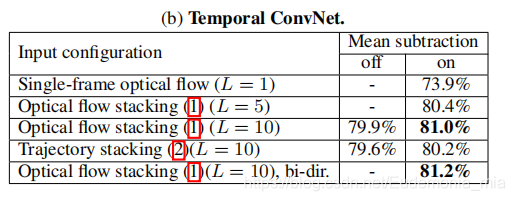
Temporal ConvNet的输入
运动特征作为网络的输入,有以下几种方式:
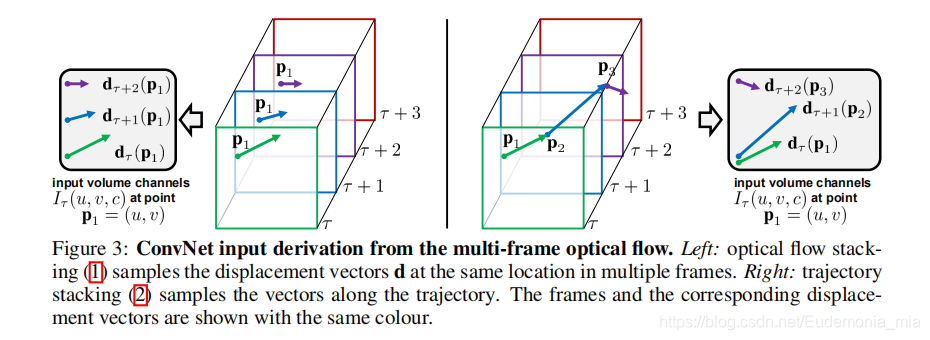
- Optical flow stacking: 输入的大小为w×h×2L,L表示堆叠的帧数。可以描述输入map某个位置的光流变化
- Trajectory stacking: 输入大小为w×h×2L,L表示堆叠的帧数。用来描述一个对应特征点连续的光流变化
下图为Optical flow stacking【直接叠加的光流(左)】与和Trajectory stacking【轨迹叠加的光流(右)】的区别:
- Bi-directional optical flow: 输入大小为w×h×2L,由于是双向的,L/2表示堆叠的帧数
- Mean flow subtracion: 用来去除部分相机运动对光流的影响
下图为以上集中方式的实验结果:
算法架构
- 双流是由两个独立的网络构成:
Spatial stream ConvNet的输入是单张图像,用来对目标和场景的appearance提取特征(有些action的识别依赖单张图像就够,有些则必须依赖运动和时间特征)。
Temporal stream ConvNet的输入是多张相邻帧的光流,对motion特征进行表示。 - 通过两个网络的softmax输出向量进行融合,来最终确定分类
下图为双流网络结构图:

- 由于当时的video数据集较少,数据集间有存在不小的差异,以此为了利用多个数据集,论文提出Multi-task learning的方法,通过在对应数据集上设置最后分类层,其他层保持不变,进行fine-tuning模型
- 通过对光流输入的可视化可以看出,Temporal stream ConvNet能够学到部分运动变化,和部分外观变化
下图为可视化图像:

参数配置
- CNN使用了AlexNet
- 激活函数使用了ReLU
- 时域卷积与空域卷积不同在于第二个卷积层没有正则化层,减少内存的消耗
- 每层CNN都有softmax,全过程的loss是每个任务的loss之和;最后两个softmax的fusion有两种方法,分别是平均法与SVM训练+L2正则方法
训练集预训练
- 空域卷积有三种方法:UCF101从0开始训练、ILSVRC-2012 pre-trained+UCF101 finetuning与ILSVRC-2012 pre-trained+UCF101只训练最后一层
- 时域卷积没有可供预处理的模型,故仅通过改变输入的层数来观察结果
- 多任务学习中对比了HMDB从0开始训练、HMDB+UCF101(部分)从0开始训练、UCF101 pre-trained+HMDB finetuning三种方式来对比结果
算法优势及原因
- 用两个CNN网络一个来处理空域信息一个来处理时域信息
- 稠密光流的确可以表征出动作的特征从而更易分类
传统非DeepLearning的视频识别算法中获取最高成绩就是iDT算法,也是使用了光流法。
本论文对光流法输入进行了4种尝试,分别是光流直接叠加的光流栈、轨迹叠加的轨迹栈、双向光流的双向栈以及去除平均光流,(stacking在这里即是堆叠累加的意思,轨迹叠加类似于视频编码中P帧的MV、MVD,双向叠加类似于B帧中的MV、MVD)
运行结果
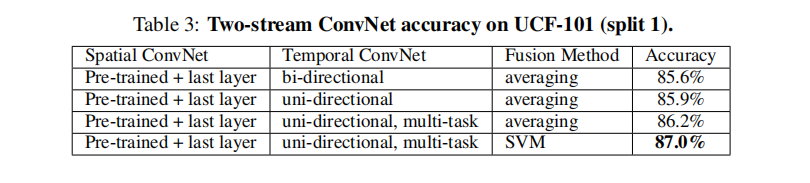
- 空域上Pre-trained效果更优,时域上L=10且双向光流,水平和垂直光流场的简单叠加效果最好。
下图为不同策略空域与时域的运行结果:

- 多任务学习的算法在小规模数据集上有明显优势
下图为非多任务学习与多任务学习对比的运行结果:

- SVM的融合方式比计算平均有更高增益
下图为不同Fusion策略对比的运行结果:
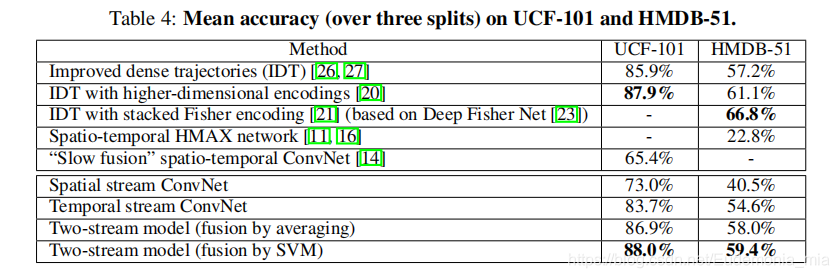
- 当时很少人研究或是没找准方向关于DeepLearning的视频识别,故对比主要是与非DeepLearning的传统手动提取特征的方法以及单空域卷积和单时域卷积进行了对比
下图为与主流算法的准确率对比: