

文章目录
1. 四个问题
- 解决什么问题
- 将深度学习拓展到视频理解领域中来
- 深度学习迁移到任何一个新的任务上都能工作得很好,但为什么到视频分类这块卷积神经网络就碰壁了
-
用什么方法解决
双流网络:空间流 + 时间流 -
效果如何
它呢是第一个能让卷积神经网络的效果,跟这之前基于最好的手工特征的方法呢打成平手 -
还存在什么问题
?
2. 论文介绍
更详细地参考视频:https://www.bilibili.com/video/BV1mq4y1x7RU
双流网络介绍

作者这里呢把关注空间信息的上面这只神经网络呢叫做空间流卷积神经网络,把下面这一支关注motion Information的卷积神经网络呢叫做时间流神经网络,空间流的输入呢就是一张单帧的图片,最后会给你一个分类的概率,时间流的输入呢是一系列的光流图片,最后呢也会给你一个分类的概率,最后呢作者把这两个分类概率呢取加全,平均就能得到最终的预测,这呢就是所谓的双流网络了。
双流模型

那接下来呢我们就讲一下文章的主体部分,也就是双流网络的结构以及如何使用光流。那在第二个章节呢作者上来就说视频啊可以很自然的被拆分为这个空间部分和时间部分,这个空间部分呢其实也就是我们说的这个 appearance信息,它主要就是用来描述这个视频中的这个场景以及物体的,那至于这个时间部分,也就我们之前说过的这个 motion信息,它主要描述的呢就是视频中的这些物体啊是如何运动的。所以呢根据这种现象,作者说我们提出了我们的这个视频理解的框架,也就是图一里展示的这个双流网络,空间流呢去学空间特征、时间流呢去学运动特征,这样呢两个神经网络各司其职互不打扰,最后的结果呢通过late fusion去合并一下,就能得到最终的预测了。
那至于怎么合并呢作者这里说,要么就是简单的做一下加权平均,要么呢就是在已经得到的这个 soft max分数上呢把它当成特征,然后再去训练一个svm去来做分类。
空间流

那接下来呢作者就先讲了一下这个空间流的这个神经网络,大概意思就是说呢这个空间上的神经网络是拿这个视频帧一帧一帧来做输入的,而其实在做的呢就是从这个静止的图像里去做这种动作识别,说白了呢就是个图像分类的任务,跟视频呢没有什么关系。那作者这里也说了这种静止的这种 appearance信息呢,其实本身就是一个非常有用的信息,因为很多动作啊都是和这个对应的物体啊牢牢的连接在一起的。
比如说这些数据集里经常会出现啊弹钢琴啊拉小提琴啊或者他打篮球踢足球这些类,那其实这些物体呢就是非常强的线索,只要模型识别到了这些物体,那其实最后的判别呢就八九不离十了。所以呢在作者后面的实验中,他们也证实了这种基于静止图像的这种视频分类,它最后的结果呢就已经非常有竞争力了,效果呢一点都不差,而且呢把这个空间网络单独抽出来,拿这种单帧的图像做输入,还有另外一个好处,那就是说你这个空间流的这个网络就可以用image net去预训练,那一般呢如果你能在这么大的数据集上去做预训练,然后在小的这种UC f101的数据集上去做微调的话,效果就会好很多。
那我们现在具体来看一下这个空间流的网络,其实呢它基本上就是Alex net,我们可以看到啊这里有5层conv,有2层FC,最后soft max,所以说呢这个空间卷积神经网络啊确实没有什么好讲的,作者接下来呢就把大量的空间都留给了如何去构造这个时间流,以及如何去有效的利用光流。
时间流
那接下来呢我们就来看看第三章节里作者是怎么介绍它的这个时间流的,因为这个时间流的输入是光流,那么就先来看一下光流到底长什么样,作者是怎么抽取光流,又是怎么预处理光流,以及最后光流这个输入的维度到底是多少?
光流是什么

那如果我们先来看这个图二,图二里的a和b其实就是视频的前后两帧就是一个人呢在射箭,我们可以看到基本这个人就是在从后背上开始拔剑,所以这个动作啊基本就是从后背伸到前方,那如果我们把这个光流啊可视化出来,其实就长这个样子,也就是说啊人的这个动作呢是朝着这个方向走的,那一般呢用数学上去表示这个光流的时候,大家一般把这个光流啊拆分成了两个方向,一个呢就是水平方向上的位移,一个呢就是竖直方向上的位移。

作者这里分别呢都把它们可视化出来了,这个图d呢就是指的水平方向上的位移,图e呢就是竖直方向上的位移。我们也可以明显的看出这个前后帧之间移动的呢其实就是这个手和这个弓箭,那如果我们再具体一点,用这个维度来表示这个输入。假如说原始输入这个图像呢这个高度呢是240,这个宽度呢是320,因为UCF101这数据集里的视频帧啊就是这个大小,那这个视频的前后两帧的这个输入维度呢就是240×320×3,然后呢不论你用什么光流预测的算法啊,你这两张图像啊最后呢就会得到一张光流的图,那这个光流图的维度呢就是240×320×2,最后这个2的这个维度呢其实就代表水平上和数值上这两个维度,也就意味着这两张图呢其实就是240×320×1的两个张量,那这里呢有两个事情值得提一下,第一个呢其实就是这个图像的输入和最后预测出来这个光流的大小呢是一样的,因为每个像素点其实都有可能运动,如果不运动呢那它这个运动幅度呢就是0,总之呢是每个像素点都会有对应的光流值的,这也就是为什么这篇论文里经常说的是dense optical flow啊密集的光流,因为每个点都有值。
网络的输入:光流的叠加方式(直接叠 和 基于轨迹的叠加方式)
第二个要提的呢就是说每两张图啊会得到一个光流,那如果是3张视频连续帧,你就是得到2个光流,4张连续帧呢就是3个光流。总之呢如果你的这个视频的长度呢是L帧,那你最后算得的这个光流呢就是 L减一帧,那在解释完光流是什么,以及如何去表示这个光流之后,接下来就该考虑如何使用光流了。那当然了一种最简单的方式就是你把视频的前后帧呢算出一个光流来,然后你把这一个光流呢通过一个2d的网络,那这样呢其实你还是在做一个图像分类的任务,只不过你把输入呢从一个单张的RGB针换成了一个单张的一个光流,但作者觉得呢这样做意义就不大了,因为我现在主要想学的呢就是这个物体的运动信息,或者说这个视频里的这个时序信息,那之前的那些手工特征呢往往都需要利用10帧或者16帧这么长的这个距离来算这个运动信息的。

那我现在深度学习这边呢最好也多用一些帧,所以作者这里就想啊我不能只用一张光流图,我要把很多张光流图啊叠在一起,也就是说啊这个通向时间流神经网络的这个输入啊是多个光流图叠加在一起的,那怎么叠加更好呢?作者其实在这个3.1里呢就讨论了一下,主要呢就讨论了两种方式,一种呢就是简单直白的直接把这些光流图呢就这么叠在一起,另外一种呢就是根据这个光流的轨迹,在轨迹上去进行这种光流数值的叠加,我们现在直接来看图三,就能更清楚的明白这两种叠加方式的区别了。
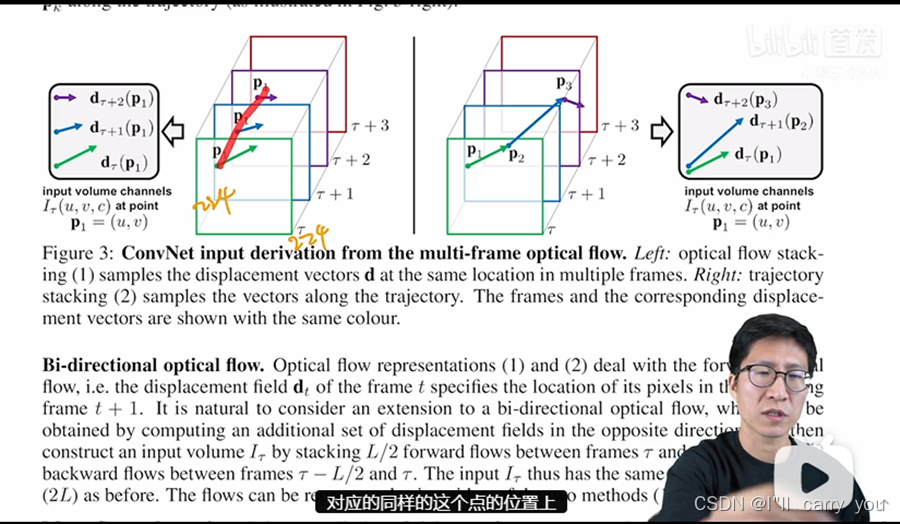
那这张图的左边呢就是简单直白的光流图的叠加,因为这些光流图已经是要进入网络的输入了,所以他们都已经过resize,所以这里呢就画的都是正方形,就是我们熟知的这个224×224的这个维度,然后呢这些光流图直接就stack起来了,也就是说我们现在这个网络每次去取输入,实际上都是在对应的同样的这个点的位置上去取得这个光流。
对于每一个光流图来说,我每次都去问这个点,它到底下一帧往哪走了,然后还是这个点下一帧它又往哪走了。这种方式的好处呢就是简单,因为我不用再做任何的预处理后处理,直接把这些光流图叠在一起就完事了,但是这样呢可能就没有充分利用这个光流的信息,所以作者呢又提出来了右边的这种叠加的方式,也就是说当你知道上一张图里这个点在下一帧的时候已经移到p2的时候,我们在下一张光流图里,就从p2这个点开始去找它,在它的下一帧里所对应的位置,而不是说每次我们都在p1的这个位置上去取光流的值,这种方式呢明显听起来合理很多,他很好的利用了光流这个信息,但可惜的是呢在这篇论文里最后通过实验发现左边的这种方式呢其实是要比右边这种方式要好一些的,这个结果啊比较让人费解,所以其实作者呢还不甘心,最后甚至在结论里呢还把这个当成了一个未来工作想,去看看到底为什么这种基于轨迹的更加合理的方式,反而效果还差了。
小技巧:双向,双向光流

呢那在讲完如何把光流图连接在一起的两种方法之后,作者又觉得呢还得尝试一下啊大家经常使用的一个小技巧,也就是这个bi directional的方式,就是双向光流。
那这个bi-directional其实也是一个非常常见的技巧了,那这个不光是在光流里,其实在视觉的其他领域或者甚至在NLP领域都有。用啊比如说我们常见的,bert其实就是bi directional。这个操作呢其实就跟pyramid啊就是金字塔,或者跟cascade的啊级连这种操作一样,都是一种非常保险的,一般都会涨点,或者说最差情况也不会掉点的技巧。那具体来说呢就是前面讲的这两种方式,1和2啊,1对应的就是这种简单粗暴的直接连接,2对应的呢就是利用轨迹信息去更精确的连接,但这两种方式呢都是只做了这个前项的光流计算,那你这个光流呢反过来算也是合理的。
比如说你一个篮球啊可以从上一帧的位置a到位置b啊当然它也可以从下一帧的位置b回到位置a所以作者这里呢也尝试了一下,他既计算了前向光流,又计算了后向光流,那为了能和之前的两种方式做公平对比,他也是选了L帧这么长度的一个视频,但是呢它把前半段用来去算前向光流,后半段呢用来去算后向光流,这样最后得到的光流输入呢还是2L个channel,那读到这儿呢其实也就把光流怎么叠加作为网络输入讲完了。

具体来说呢就是给定L+1帧,我们呢就会得到L个光流图,那这 L个光流图的大小呢其实就是w乘h×2L的张量大小,然后我们就把这个张量呢送给一个时间流的网络。

那如果我们再返回来看图一下面的这个时间流网络我们就会发现呢它其实具体的网络结构呢跟空间流是一样的,那都是5层conv,后面接了2层FC,最后出这个结果,只不过呢就是第一个卷积层的那个输入维度跟上面不一样了,这里这张图呢并没有展示出来,但具体来说呢上面这张图的输入维度是三,就是r GB三个channel,而下面这个多帧光流的输入维度呢就是2L,在这篇文章里呢作者一般是使用11帧作为这个输入,那11帧呢就会得到10个光流图,那这里头这个 channel数呢就是10×2就是20,至于这些光流图是按什么顺序叠加的,其实它先叠加的是水平部分的光流位移,然后再叠加的是竖直方向的光流位移。那具体写一下呢就是先是水平的x1,x2一直的xl,然后再是竖直的y1y2再到yl,那这个叠加起来,其实最后的维度就是224×224×2L。那至于最后的输出,那这里呢我们就拿最简单的这个 Soft max分数做个平均来做例子。

那如果我们现在在做UC f101这个数据集,也就是说它有101个类的话,那最后这个 soft max分数呢其实就是一个1×101的一个向量,那底下这个时间流的输出呢也是1×101的一个向量,那取平均呢其实就是把这两个向量加起来除以2,最后呢再做个argmax操作,哪个分数最高那它就是哪个类了。
所以读到这儿呢整个双流网络就已经介绍完了,我们可以看到啊从网络结构来说,其实并没有什么太大的改动,它就是沿用了Alex net,并做了一些稍微的小的改动。最后输入上的这个操作呢其实也是非常简单,常规的一个late fusion的操作,但最关键的就是它引入了一个额外的这个时间流,而且巧妙的利用了光流信息啊去提供这个视频中的运动信息,而不用这个神经网络自己去学了,我们在后面的实验中也可以看到,通过多加这么一个时间流网络,最后的结果呢是大大的提高,而且它对整个领域带来的影响力呢也是非常巨大的,我们会在文章最后的点评里呢好好的说一下。
实现细节
 接下来呢我们简单看一下这个实现细节,其实实现细节呢跟现在也差不多,尤其是这个训练部分,一直到18 19年的时候也还都是这个套路,无非呢就是把之前的这个网络换掉,之前这个网络呢就像我刚才说的一样,它其实就是一个Alexnet的变体,当时这个网络里呢还有这个 local response normalization这个层,那现在呢早都已经不用这个操作了,但除此之外呢都是比较标准的网络和标准的操作,
接下来呢我们简单看一下这个实现细节,其实实现细节呢跟现在也差不多,尤其是这个训练部分,一直到18 19年的时候也还都是这个套路,无非呢就是把之前的这个网络换掉,之前这个网络呢就像我刚才说的一样,它其实就是一个Alexnet的变体,当时这个网络里呢还有这个 local response normalization这个层,那现在呢早都已经不用这个操作了,但除此之外呢都是比较标准的网络和标准的操作,
这里呢其实我主要想讲另外两个方面,一个呢就是如何做这个测试,另外一个呢就是如何使用这个光流,测试它这里说啊不论你这个视频有多长,我呢就从这个视频里等间距的去抽取25帧,比如说你这个视频有100帧,那我就每隔4帧取一针啊取够这个25针,那如果你这个视频有1万帧,那我还是把它等间距的分成25帧,那这个时候呢就是每400帧取一针。总之呢取的这个帧数是固定的,就是25。那其实在当时呢像UCF101和h MD b51这两个数据集,它的这个视频长度啊都是在5秒到7秒之间的,那按一秒30帧算的话,其实也就是150帧到200帧左右,那从这里面呢取25帧,大概呢就是每隔七八针取一下,相当于就是每隔1/3秒就取一下,那这个时间间隔还是比较短的,所以取出来的这些帧呢变化也不是特别大。

然后对取出来的这些针呢每一帧都去做这个10 cross。具体来说呢就是如果这是你取的那个针,那我们呢就先取4个边角,那其实就是说取这个边角,然后取这个边角这个和这个取4个边角。当然因为这个 crop比较大,所以这4个边角呢有很大部分也都是重叠的,然后呢再取1个中间啊也就是中间,所以先是1张图啊变成了5个图,然后呢我再把这个图像呢翻转一下,然后再在这个翻转的图像上呢去取这个4个边角和1个中心,所以最后呢就是一张图变成了10张图,那对于整个视频25帧来说,其实最后就变成了250个crop,那每张图呢都会通过2d的这个空间流的神经网络得到一个结果,那最后这250个帧得到的结果呢直接就取平均得到最终的这个预测。
那对于光流来说呢也一样,它同样也是先取得这25帧,然后从这25个帧的位置开始呢往后连续的取11帧,然后这11帧呢抽得光流,然后把这些光流图呢送给这个时间流神经网络,最后把所有的这个结果呢取平均。
然后当空间流和时间流都取完平均都得到最终的这个预测结果之后呢然后,再把这两个流的结果作为一个late fusion,把它俩加到一起除以2,得到最终的双流网络的预测结果。
实验
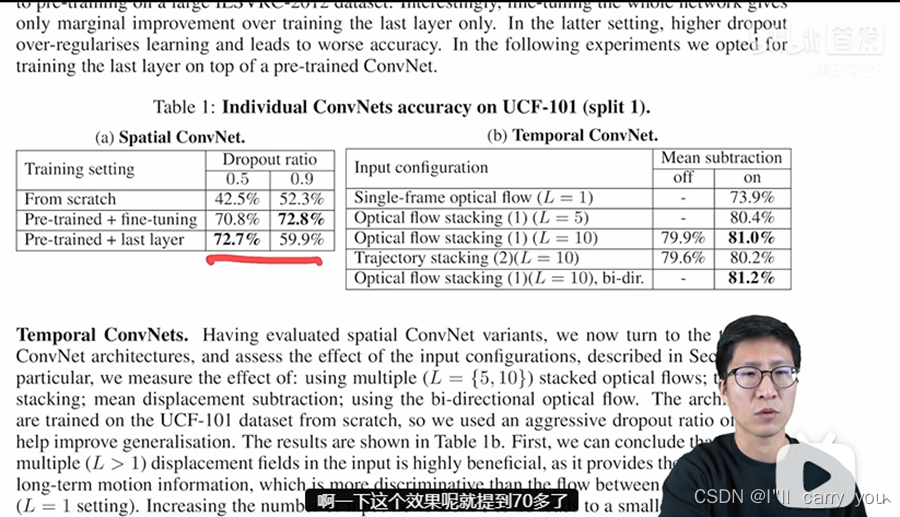
那接下来呢我们看一下实验部分,看看双流网络到底有多强。那首先我们来看表一,表一这里呢作者就拿UCF101这个数据集做了一个实验,它这里呢是分别做了空间流和时间流的这个消融实验。那我们先来看空间流啊空间流的话,其实就是说你有没有用这个预训练网络,因为文章的作者也说,嘛之所以把这个空间和时间分开,就是为了能让空间流享受这个预训练模型带来的好处。那这里我们可以看到,如果你是从随机初始化开始从头训练的话,你这个效果就大概只有50左右,不论你这个dropout用的是0.5还是0.9,但是呢如果你用了这个预训量网络啊一下这个效果呢就提到70多了。
这里作者呢在使用了一系列网络之后,他还做了两个消融实验,就是说你到底是整个网络就都去做微调,还是说只在最后一层上做微调啊之前的这个主干网络都锁住。之所以他会做这样的考虑,是因为当时这些数据集呢都太小了,作者担心呢很容易就会过拟合,其实这也就是为什么它这里就会是不同的这个 Dropout的这个 ratio。因为当你打开整个网络,就是整个网络都是做微调的时候,数据集太小就容易过拟合,那这个时候呢你就要设置一个非常大的这dropout的ratio,作者这里发现呢如果你设置一个非常夸张的值就是是0.9,其实它的效果非常好,就到72,如果你是0.5呢它值就会低,有可能就有点过拟合,那对于这种骨干网络锁住啊只训练最后一层来说,啊就不太用担心过拟合的问题,所以这个时候呢用dropout 0.5反而效果更好,那如果你用0.9,那就有太多信息丢失了,这个网络呢可能不好训练,最后就只有60的效果,但其实后面的很多工作呢当用了一些训练上的trick之后,而且当这个数据集逐渐增大之后,大家往往都会选择这种预训练模型加fine-tune的模式,它的效果呢会更好。
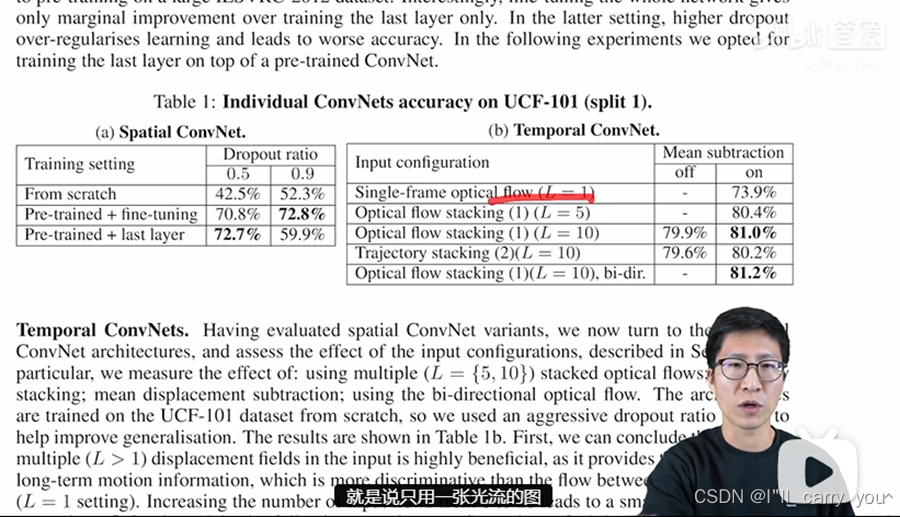
那对于时间流来说,作者主要就对比了一下,到底是这种简单粗暴的堆叠方式好,还是这种依照轨迹堆叠的方式好?而且呢就是这种双向的光流到底有没有用?那首先作者这里的一个基线模型,就是说只用一张光流的图,也就相当于这里是在做图片分类了,只不过输入呢是一张光流图,那这个时候 呢它的效果只有74,那后面的这些80的效果呢差了6个点,还是相差非常多的。然后作者呢逐渐增加这个使用光流图的数量,先是加到5,然后再是加到10,然后最后发现呢用的越多还是越好。那之所以没有再用更多,我估计其实就是效果饱和了,他们可能也试过12啊15啊这些值,但估计没有更多的提高了,当然也有可能是GPU内存不够了,然后当确定了这个长度只有10的时候,他这里就对比一下到底是简单粗暴的stack好,还是根据轨迹去stack好,那这里我们发现呢其实这两个效果差不多,简单粗暴的方式呢更好一点,最后呢就是用这种双向的光流,结果呢会再好一点,这个呢也不出意外,因为就像我刚才说的一样,这种bi directional啊或者pyramid或者cascade的这种方式,一般都会涨点的,有可能涨得很多,但有可能涨的很少,但一般它是不会掉点的,所以可以放心大胆的使用。
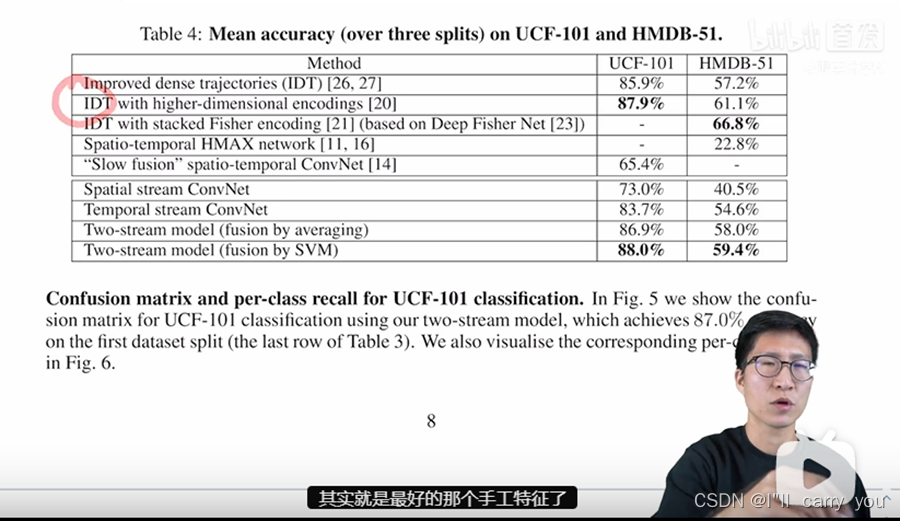 那做完了消融实验,那其实我们就把空间流和时间流的网络结构呢就都定下来了,那定下了整体的结构,最后我们就来看一下那双流网络跟之前最好的那些方法相比如何,那首先呢前三种方法其实就是最好的那个手工特征了,第一种就是最火爆的这个 Idt啊 improve the dense trajectory特征,应用是非常广泛的效果,在这两个数据集上也非常的高。
那做完了消融实验,那其实我们就把空间流和时间流的网络结构呢就都定下来了,那定下了整体的结构,最后我们就来看一下那双流网络跟之前最好的那些方法相比如何,那首先呢前三种方法其实就是最好的那个手工特征了,第一种就是最火爆的这个 Idt啊 improve the dense trajectory特征,应用是非常广泛的效果,在这两个数据集上也非常的高。
接下来这两种方式呢就是说在idt的基础上加了一些全局的信息,就是通过全局的这种encoding,比如说fisher vector encoding或者VLAD encoding,去让这个特征啊更具有全局性,更适合做视频,所以说呢它的这个结果也更高一些,那最后就到88或者67了。那接下来这两篇呢其实之前用深度学习尝试去做视频分类的方法,我们可以看到它这个效果呢就比较拉垮,在hmdb上只有20多的效果。然后这个文献14呢即使是在100万个视频上进行预训练之后,它在UCF上的结果呢也只有65,跟之前的这个86 88相比呢差了20多个点。
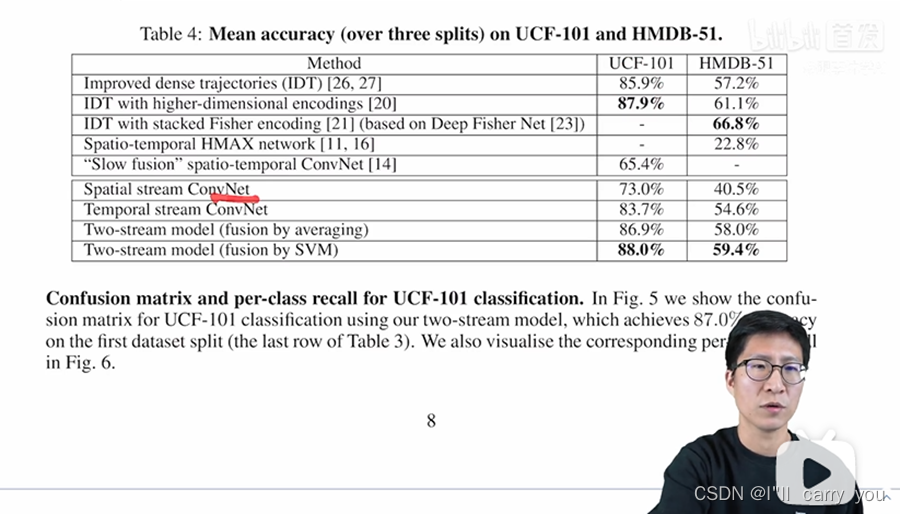
那接下来我们来看双流网络的表现,那首先是来看空间流,那空间流呢因为利用了image net这个预训练模型,所以说它的这个表现呢已经达到了73,所以比之前的这个网络65还要好。更关键的一点呢是它的时间流的效果竟然有83这么高,这个就比较神奇了,因为对于时间网络来说,它的输入呢是光流,而且它的第一层的这个接收维度呢也是20,所以当时作者呢是并没有利用imagenet这个预训练模型的,因为感觉没法用啊没法装载这个预训练模型啊维度不匹配。所以按道理来说,在这种小型数据集上直接从头开始训练一个网络效果不应该这么好。但可惜呢因为这个运动信息对于视频理解可能太重要了,所以说啊单凭一个时间流网络,它最后的结果就已经推到这么高了,然后呢你把两个网络简单的结合起来,用这种取平均的方式去做late fusion,结果就已经能达到87和58了。
意思就是说完全能够超过之前最好的这个手工特征86和57,如果再次用这个 svm去训练一下这个特征的话,甚至在UCF上能够达到88,那就和之前用了这种全局encoding的方式达到87.9呢就打平手。虽然说在hmDB-51这个数据集上呢59的效果呢跟66还是有差距,但是已经让大家完全坚信了啊深度学习或者说深度神经网络在视频分类里的这个有效性。所以说呢在双流网络出现之后,就有一大批研究者跟进,很快在两年多的时间里,UCF101这个数据集就被刷到98的准确率了,直接就被刷爆了。
所以说双流网络在视频理解领域里的地位,其实已经接近于Alex net对于图像分类,或者说现在vision transformer对于图像分类的这个作用,一旦证明了它的有效性,很多后续工作就迅速跟进了,所以说呢绝对称得上是开山之作。
3. 参考资料
视频地址:https://www.bilibili.com/video/BV1mq4y1x7RU
4. 收获
- 性能的提升主要在于时间流,既然原始视频帧丢进去效果不好,那我们不如给这个模型提供一些这种先验信息(本文指光流),他学不到,那我们就帮他学,这样呢往往能大幅度简化这个任务(卷积神经网络最擅长学习这种映射了)。
虽然前两段呢讲的是传统的基于手工特征的学习方式,但他也映射了之后啊用深度学习去做视频的这个两个方向,那这种局部的时空学习,其实最后就演变成了3d网络,那这个基于光流基于轨迹的方法呢就演变成了今天我们要讲的双流法,所以说呢研究也都是一脉相承的,并不是说之前的这种传统手工特征在深度学习面前就一无是处了,反而呢是研究者不停的从传统的方法里呢去寻找灵感,从而让深度学习的方法呢做得更好更强。
- 与空间流结果取平均能够提升2个点,双向光流能够提升0.几个点(trick)
这种bi directional啊或者pyramid或者cascade的这种方式,一般都会涨点的,有可能涨得很多,但有可能涨的很少,但一般它是不会掉点的,所以可以放心大胆的使用。
- 学习了光流是什么(光流都是一个非常有效的描述物体之间运动的一个特征),但这里没有讲怎么抽取光流,但已有实现。
总之呢截止到目前为止,光流都是一个非常有效的描述物体之间运动的一个特征。
那另外想说的一个点呢就是这篇文章的作者是如何预处理光流以及如何计算光流的。这个方法呢其实从14年他们提出以后一直沿用至今,可以说啊是影响深远。他们预测光流的算法呢其实是从文献二来的,而且用的是一个GPU的实现,所以还是比较快的。
-
学习了视频如何做测试(等间距抽取帧,再做crop)
-
存在的局限性:1. 光流计算慢且占用内存大。 2. 为什么基于轨迹的光流图效果不如直接堆叠好
那最后呢我们来总结一下这篇论文论文的逻辑呢其实非常清晰,他就讲了一个故事,他的研究动机呢就是说之前的一些方法,因为没有用运动信息,所以导致呢即使用了深度学习,最后的结果还不如手工传统设计的特征好,所以他们就尝试用了一下这个运动信息,那这个运动信息呢其实可以用很多种方式来表示了,光流只是其中一种,但也是最好用的一种,所以作者呢就选择了用光流作为输入,然后又新添加了这么一个时间流的网络,最后发现呢效果确实很好,所以文章整体上来看非常易读,脉络很清晰。那至于双流网络带来的贡献,其实我觉得并不单单是使用了额外的这么一支时间流的贡献,它主要告诉我们了一个另外的道理,就是说当你发现神经网络不能解决什么问题的时候,有可能仅仅靠模改模型啊或者改一下这个目标函数,这没办法很好的解决这个问题的。
那我们不如给这个模型提供一些这种先验信息,他学不到,那我们就帮他学,这样呢往往能大幅度简化这个任务。其实双流网络论文的引用这么高,也不光是说它在视频分类里的应用,主要呢是因为它的这个影响力呢横跨很多领域,当大家发现一个神经网络解决不了问题的时候,大家就会想到双流网络,然后去尝试使用别的数据啊尝试使用别的模型来做这种多流网络啊解决问题往往的效果都非常好,因为这些网络呢是可以互补的,而这个呢也从侧面验证了这个数据的重要性。那吴恩达老师最近也一直在强调,我们要做这种data,centre的ai,就是说要以数据为主,因为在真实的应用场景里呢往往去收集更多或者更好的数据,对这个任务带来的提升呢是更巨大的,而且呢收集更多更大更好的这个数据,还能有效的解决模型的泛化问题,还有模型的公平性啊偏见,这一系列的问题都可以通过去做数据来得到有效的提高,而只改模型呢往往是做不到的。
那另外一个值得思考的点呢其实就是说双流网络其实你也可以把它想象成是一个多模态学习的先例,它这里的这个 RGB、图像呢和这个光流图像其实就属于不同的模态长的也不一样,代表的实际意义也不一样。那这个如果粗略的对比一下,其实跟clip也有点像啊对不对?Clip呢就是说上面呢是图片,下面呢是文本,最后呢算一个相似性,那双流网络呢就是上面是RGB,下面是光流,然后最后把它俩的结果呢加一下。所以说从多模态学习的角度来看,双流网络或者是利用光流有可能会在视频理解,或者说表征学习领域呢再次发光发热。