本篇博客是Spark之【RDD编程】系列第五篇,为大家介绍的是RDD依赖关系。
该系列内容十分丰富,高能预警,先赞后看!

6.RDD依赖关系
6.1 Lineage
RDD只支持粗粒度转换,即在大量记录上执行的单个操作。将创建RDD的一系列Lineage(血统)记录下来,以便恢复丢失的分区。RDD的Lineage会记录RDD的元数据信息和转换行为,当该RDD的部分分区数据丢失时,它可以根据这些信息来重新运算和恢复丢失的数据分区。
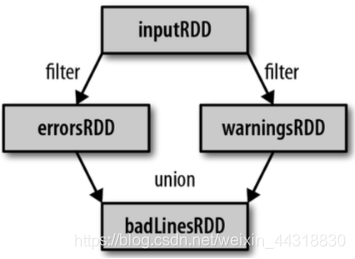
1)读取一个HDFS文件并将其中内容映射成一个个元组
scala> val wordAndOne = sc.textFile("/fruit.tsv").flatMap(_.split("\t")).map((_,1))
wordAndOne: org.apache.spark.rdd.RDD[(String, Int)] = MapPartitionsRDD[22] at map at <console>:24
2)统计每一种key对应的个数
scala> val wordAndCount = wordAndOne.reduceByKey(_+_)
wordAndCount: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[23] at reduceByKey at <console>:26
3)查看“wordAndOne”的Lineage
scala> wordAndOne.toDebugString
res5: String =
(2) MapPartitionsRDD[22] at map at <console>:24 []
| MapPartitionsRDD[21] at flatMap at <console>:24 []
| /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 []
| /fruit.tsv HadoopRDD[19] at textFile at <console>:24 []
4)查看“wordAndCount”的Lineage
scala> wordAndCount.toDebugString
res6: String =
(2) ShuffledRDD[23] at reduceByKey at <console>:26 []
+-(2) MapPartitionsRDD[22] at map at <console>:24 []
| MapPartitionsRDD[21] at flatMap at <console>:24 []
| /fruit.tsv MapPartitionsRDD[20] at textFile at <console>:24 []
| /fruit.tsv HadoopRDD[19] at textFile at <console>:24 []
5)查看“wordAndOne”的依赖类型
scala> wordAndOne.dependencies
res7: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.OneToOneDependency@5d5db92b)
6)查看“wordAndCount”的依赖类型
scala> wordAndCount.dependencies
res8: Seq[org.apache.spark.Dependency[_]] = List(org.apache.spark.ShuffleDependency@63f3e6a8)
注意: RDD和它依赖的父RDD(s)的关系有两种不同的类型,即窄依赖(narrow dependency)和宽依赖(wide dependency)。
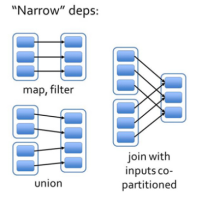
6.2 窄依赖
窄依赖指得是每一个父RDD的Partition最多被子RDD的一个Partition使用,窄依赖我们形象的比喻为独生子女。
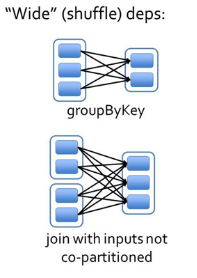
6.3 宽依赖
宽依赖指的是多个子RDD的Partition会依赖同一个父RDD的Partition,会引起shuffle,总结:宽依赖我们形象的比喻为超生。
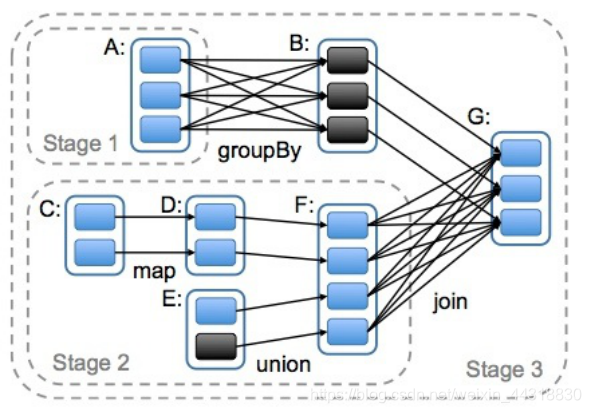
6.4 DAG
DAG(Directed Acyclic Graph)叫做有向无环图,原始的RDD通过一系列的转换就形成了DAG,根据RDD之间的依赖关系的不同将DAG划分成不同的Stage,对于窄依赖,partition的转换处理在Stage中完成计算。对于宽依赖,由于有Shuffle的存在,只能在parent RDD处理完成后,才能开始接下来的计算,因此宽依赖是划分Stage的依据。
6.5任务划分(面试重点)
RDD任务切分中间分为:Application、Job、Stage和Task。
1)Application:初始化一个SparkContext即生成一个Application
2)Job:一个Action算子就会生成一个Job
3)Stage:根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
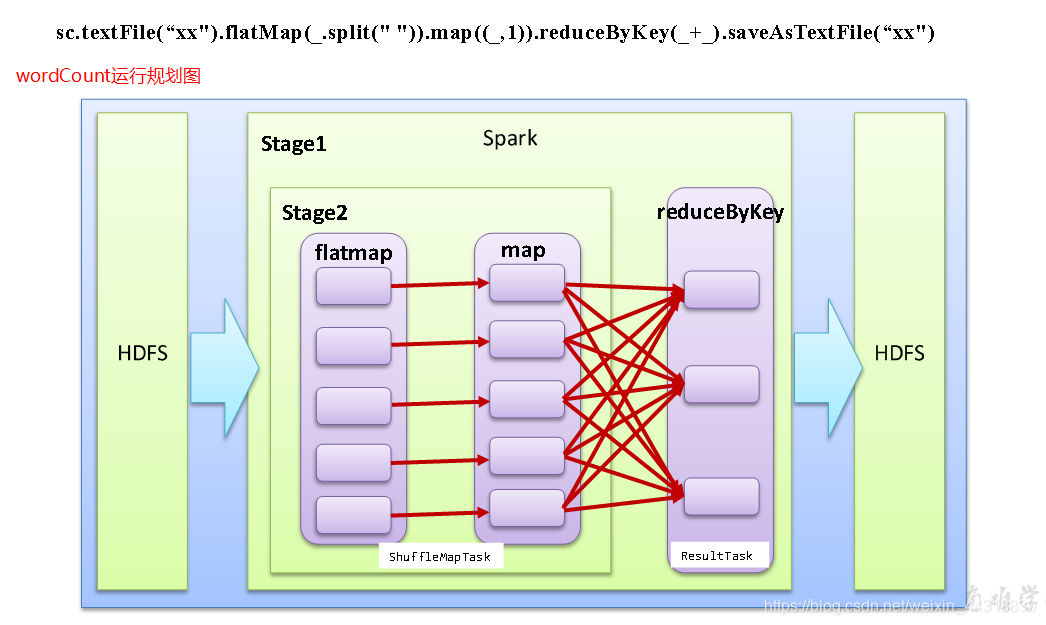
4)Task:Stage是一个TaskSet,将Stage划分的结果发送到不同的Executor执行即为一个Task。
注意: Application -> Job-> Stage-> Task 每一层都是 1对n 的关系。
本次的分享就到这里,受益的小伙伴或对大数据技术感兴趣的朋友记得点赞关注哟。下一篇博客将为大家介绍RDD缓存,敬请期待!

