RDD中不同的操作会使得不同RDD中的分区会产生不同的依赖。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency),图9-10展示了两种依赖之间的区别。
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;比如图9-10(a)中,RDD1是RDD2的父RDD,RDD2是子RDD,RDD1的分区1,对应于RDD2的一个分区(即分区4);再比如,RDD6和RDD7都是RDD8的父RDD,RDD6中的分区(分区15)和RDD7中的分区(分区18),两者都对应于RDD8中的一个分区(分区21)。
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。比如图9-10(b)中,RDD9是RDD12的父RDD,RDD9中的分区24对应了RDD12中的两个分区(即分区27和分区28)。
总体而言,如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。窄依赖典型的操作包括map、filter、union等,宽依赖典型的操作包括groupByKey、sortByKey等。对于连接(join)操作,可以分为两种情况。
(1)对输入进行协同划分,属于窄依赖(如图9-10(a)所示)。所谓协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖,如图9-10(b)所示。
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;比如图9-10(a)中,RDD1是RDD2的父RDD,RDD2是子RDD,RDD1的分区1,对应于RDD2的一个分区(即分区4);再比如,RDD6和RDD7都是RDD8的父RDD,RDD6中的分区(分区15)和RDD7中的分区(分区18),两者都对应于RDD8中的一个分区(分区21)。
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。比如图9-10(b)中,RDD9是RDD12的父RDD,RDD9中的分区24对应了RDD12中的两个分区(即分区27和分区28)。
总体而言,如果父RDD的一个分区只被一个子RDD的一个分区所使用就是窄依赖,否则就是宽依赖。窄依赖典型的操作包括map、filter、union等,宽依赖典型的操作包括groupByKey、sortByKey等。对于连接(join)操作,可以分为两种情况。
(1)对输入进行协同划分,属于窄依赖(如图9-10(a)所示)。所谓协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖,如图9-10(b)所示。
对于窄依赖的RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的RDD,则通常伴随着Shuffle操作,即首先需要计算好所有父分区数据,然后在节点之间进行Shuffle。
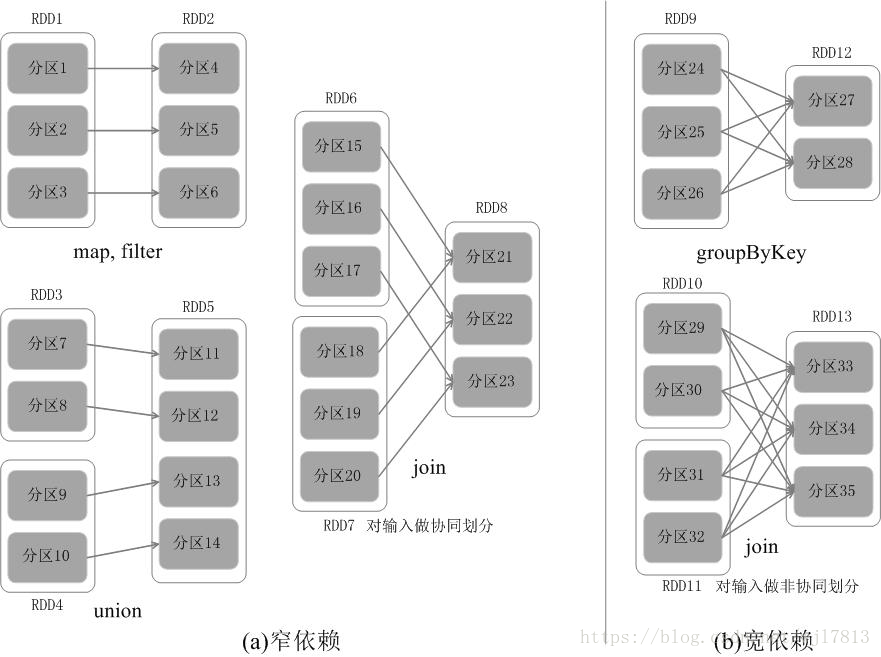
图9-10 窄依赖与宽依赖的区别
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其它RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点和记录日志,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。