1、概述
\quad \quad Spark最重要的一个功能是它可以通过各种操作(operations)持久化(或者缓存)一个集合到内存中。当你持久化一个RDD的时候,每一个节点都将参与计算的所有分区数据存储到内存中,并且这些数据可以被这个集合(以及这个集合衍生的其他集合)的动作(action)重复利用。这个能力使后续的动作速度更快(通常快10倍以上)。对应迭代算法和快速的交互使用来说,缓存是一个关键的工具。
2、 API
\quad \quad RDD可以通过persist()或者cache()方法持久化一个rdd。首先,在action中计算得到rdd;然后,将其保存在每个节点的内存中。Spark的缓存是一个容错的技术-如果RDD的任何一个分区丢失,它可以通过原有的转换(transformations)操作自动的重复计算并且创建出这个分区。
2.1 cache()
源代码:
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def cache(): this.type = persist()
- cache 方法调用了 persist 方法,本质也是persist
- cache()是rdd.persist(StorageLevel.MEMORY_ONLY)的简写,效果和他一模一样的。
- 默认的存储级别都是仅在内存存储一份,不使用磁盘,不使用堆外,支持反序列化,1副本
- Spark的存储级别还有好多种,存储级别在object StorageLevel中定义的。
小小案例:
1)创建一个RDD
scala> val rdd=sc.makeRDD(Array("hello,spark"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[204] at makeRDD at <console>:26
2)将RDD转换为携带当前时间戳不做缓存
scala> val nocache=rdd.map(_.toString+System.currentTimeMillis)
nocache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[205] at map at <console>:28
3)多次打印结果
scala> nocache.collect
res36: Array[String] = Array(hello,spark1610781859495)
scala> nocache.collect
res37: Array[String] = Array(hello,spark1610781890107)
scala> nocache.collect
res38: Array[String] = Array(hello,spark1610781949022)
4)将RDD转换为携带当前时间戳并做缓存
scala> val nocache_cache=rdd.map(_.toString+System.currentTimeMillis).cache
nocache_cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[206] at map at <console>:28
5)多次打印做了缓存的结果
scala> nocache_cache.collect
res39: Array[String] = Array(hello,spark1610782077927)
scala> nocache_cache.collect
res40: Array[String] = Array(hello,spark1610782077927)
scala> nocache_cache.collect
res41: Array[String] = Array(hello,spark1610782077927)
- 通过3、5结果对比,是不是缓存以后的,再次使用时不会再消耗实践,直接从内存中提取出来。
2.2 persist()
源代码:

/** Persist this RDD with the default storage level (`MEMORY_ONLY`). */
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
- 使用方法和cache方法一样,只不过可以改变存储级别属性StorageLevel._
3、存储级别
\quad \quad 此外,我们可以利用不同的存储级别存储每一个被持久化的RDD。例如,它允许我们持久化集合到磁盘上、将集合作为序列化的Java对象持久化到内存中、在节点间复制集合或者存储集合到Tachyon(分布式内存文件系统)中。我们可以通过传递一StorageLevel对象给persist()方法设置这些存储级别。cache()方法使用了默认的存储级别StorageLevel.MEMORY_ONLY。
\quad \quad Spark的存储级别在object StorageLevel中定义的。源码如下:
object StorageLevel {
val NONE = new StorageLevel(false, false, false, false)
val DISK_ONLY = new StorageLevel(true, false, false, false)
val DISK_ONLY_2 = new StorageLevel(true, false, false, false, 2)
val MEMORY_ONLY = new StorageLevel(false, true, false, true)
val MEMORY_ONLY_2 = new StorageLevel(false, true, false, true, 2)
val MEMORY_ONLY_SER = new StorageLevel(false, true, false, false)
val MEMORY_ONLY_SER_2 = new StorageLevel(false, true, false, false, 2)
val MEMORY_AND_DISK = new StorageLevel(true, true, false, true)
val MEMORY_AND_DISK_2 = new StorageLevel(true, true, false, true, 2)
val MEMORY_AND_DISK_SER = new StorageLevel(true, true, false, false)
val MEMORY_AND_DISK_SER_2 = new StorageLevel(true, true, false, false, 2)
val OFF_HEAP = new StorageLevel(true, true, true, false, 1)
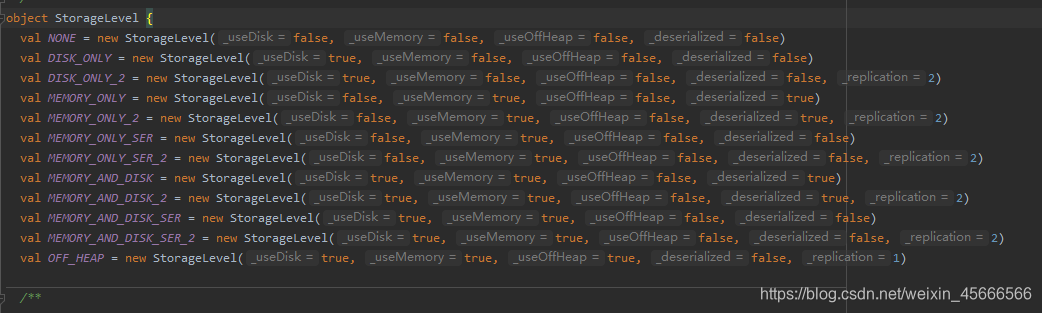
StorageLevel有五个属性分别是
private var _useDisk: Boolean, //useDisk_是否使用磁盘
private var _useMemory: Boolean, //useMemory_是否使用内存
private var _useOffHeap: Boolean, //useOffHeap_是否使用堆外内存如:Tachyon,
private var _deserialized: Boolean,//deserialized_是否进行反序列化
private var _replication: Int = 1) //replication_备份数目。
完整的存储级别介绍如下所示:
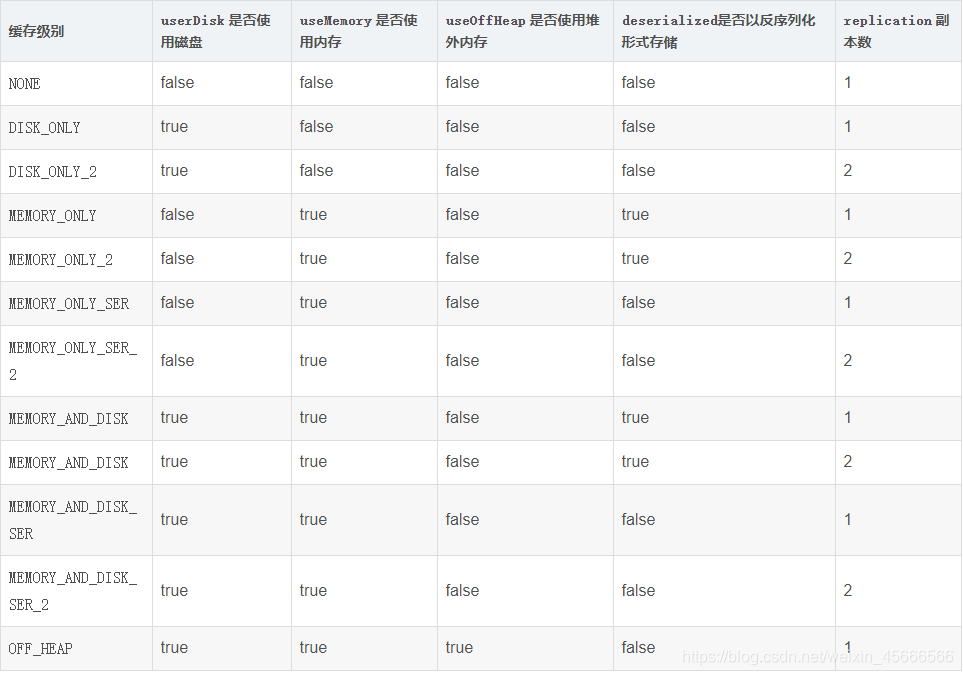
4、如何选择存储级别
\quad \quad Spark的多个存储级别意味着在内存利用率和cpu利用效率间的不同权衡。其实如何存储是一个技术活, 有很多细节需要思考, 如下
-
是否使用磁盘缓存? (保险)
-
是否使用内存缓存? (追求效率)
-
是否使用堆外内存? (java管辖范围之外的堆内存,不受GC控制,相对不太安全,由spark来管理,一般不用)
-
缓存前是否先序列化? (取决于数据的大小,数据大的话适合)
-
是否需要有副本? (高可用,数据昂贵的时候)
我们推荐通过下面的过程选择一个合适的存储级别:
-
如果你的RDD适合默认的存储级别(MEMORY_ONLY),就选择默认的存储级别。因为这是cpu利用率最高的选项,会使RDD上的操作尽可能的快。
-
如果不适合用默认的级别,选择MEMORY_ONLY_SER。选择一个更快的序列化库提高对象的空间使用率,但是仍能够相当快的访问。
-
除非函数计算RDD的花费较大或者它们需要过滤大量的数据,不要将RDD存储到磁盘上,否则,重复计算一个分区就会和重复从磁盘上读取数据一样慢。
-
如果你希望更快的错误恢复,可以利用重复(replicated)存储级别。所有的存储级别都可以通过血统机制重新计算丢失的数据来支持完整的容错,但是重复的数据能够使你在RDD上继续运行任务,而不需要重新计算丢失的数据。
在拥有大量内存的环境中或者多应用程序的环境中,OFF_HEAP具有如下优势:
-
它运行多个执行者共享Tachyon中相同的内存池。
-
它显著地减少垃圾回收的花费。
-
如果单个的执行者崩溃,缓存的数据不会丢失。
其中,
- MEMORY_ONLY:效率最高,没有序列化和反序列化的过程
- MEMORY_ONLY_SER: 需要进行序列化和反序列化,更节省空间
5、清理缓存
- 缓存其实是一种空间换时间的做法, 会占用额外的存储资源, 如何清理?
- 调用rdd.unpersist()清除缓存
- 根据缓存级别的不同, 缓存存储的位置也不同, 但是使用 unpersist 可以指定删除 RDD 对应的缓存信息, 并指定缓存级别为 NONE
源码如下:
/**
* Mark the RDD as non-persistent, and remove all blocks for it from memory and disk.
*
* @param blocking Whether to block until all blocks are deleted.
* @return This RDD.
*/
def unpersist(blocking: Boolean = true): this.type = {
logInfo("Removing RDD " + id + " from persistence list")
sc.unpersistRDD(id, blocking)
storageLevel = StorageLevel.NONE
this
}
接着上面的案例:清除其缓存
scala> nocache_cache.unpersist()
res43: nocache_cache.type = MapPartitionsRDD[206] at map at <console>:28
- 那么再次打印时,就会消耗时间
scala> nocache_cache.collect
res44: Array[String] = Array(hello,spark1610783760985)
6、应用场景
-
要求的计算速度快,对效率要求高的时候
-
集群的资源要足够大,能容得下要被缓存的数据(缓存需要占用内存)
-
被缓存的数据会多次的触发Action(多次调用Action类的算子)
-
先进行过滤,然后将缩小范围后的数据缓存到内存中
-
如果在应用程序中多次使用同一个 RDD,可以将该 RDD 缓存在计算节点的内存中,该 RDD 只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该 RDD 的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。在使用完数据之后,要释放缓存,否则会一直在内存中占用资源。