RDD
引言
为什么要有RDD?
\quad \quad 在许多迭代式算法(比如机器学习、图算法等)和交互式数据挖掘中,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,之前的MapReduce框架采用非循环式的数据流模型,把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。且这些框架只能支持一些特定的计算模式(map/reduce),并没有提供一种通用的数据抽象。
\quad \quad RDD提供了一个抽象的数据模型,让我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换操作(函数),不同RDD之间的转换操作之间还可以形成依赖关系,进而实现管道化,从而避免了中间结果的存储,大大降低了数据复制、磁盘IO和序列化开销,并且还提供了更多的API(map/reduec/filter/groupBy…)
\quad \quad Spark 的核心是建立在统一的抽象弹性分布式数据集(Resiliennt Distributed Datasets,RDD)之上的,这使得 Spark 的各个组件可以无缝地进行集成,能够在同一个应用程序中完成大数据处理。
1、概念
\quad \quad RDD称为 弹性分布式数据集( Resilient Distributed Datasets),是Spark中最基本的数据抽象,代表一个只读、可分区、里面的元素可并行计算的集合。其允许在大型集群上执行基于内存的计算( In Memory Computing),为用户屏蔽了底层复杂的计算和映射环境。
弹性(容错): RDD默认存放在内存中,当内存不足,Spark自动将RDD写入磁盘。所以在任何时候都能进行重算,这样当集群中的一台机器挂掉而导致存储在其上的RDD丢失后,Spark还可以重新计算出这部分的分区的数据
分布式: 基于集群,数据计算分布于多节点
数据集: RDD并不存储真正的数据,只是对数据和操作的描述。它是只读的、分区记录的集合,每个分区分布在集群的不同节点上。
\quad \quad 简单来说,RDD本质上是数据集的描述(只读的、可分区的分布式数据集),而不是数据集本身。是将数据项拆分为多个分区的集合,存储在集群的工作节点上的内存和磁盘中,并执行正确的操作 。
更规范的解释是:
- RDD是用于数据转换的接口 ,比如 map、 filter、 groupBy、 join等。
- RDD指向了存储在 HDFS、 Cassandra、 HBase等、或缓存(内存、内存 +磁盘、仅磁盘等),或在故障或缓存收回时重新计算其他 RDD分区中的数据 。从这个意义上讲, RDD不包含任何待处理数据。
2、属性
- 一系列的分区(分片)信息,每个任务处理一个分区
- 每个分区上都有compute函数,计算该分区中的数据
- RDD之间有一系列的依赖
- 分区函数决定数据(key-value)分配至哪个分区
- 最佳位置列表,将计算任务分派到其所在处理数据块的存储位置
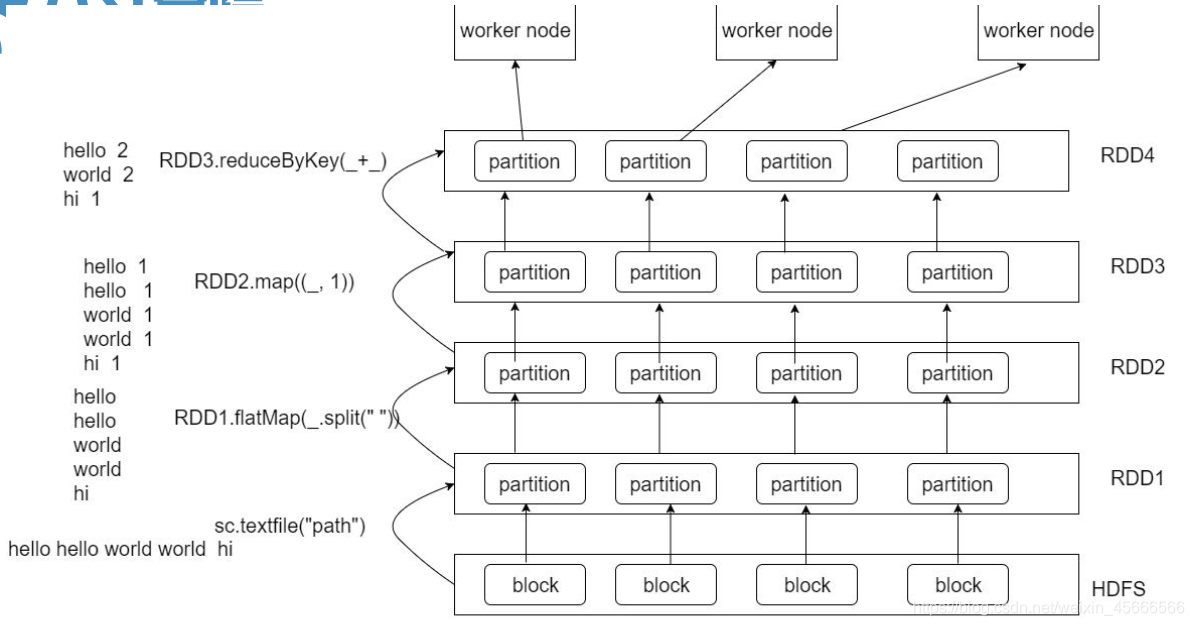
2.1 多分区
- RDD是由多个分区构成的( 使用RDD#partitions返回 RDD的所有分区信息),每个Partition都有一个唯一索引编号 (使用Partition#index访问)
- RDD分区概念与MapReduce的输入切片概念是类似的,对每个分区的运算会被一个当作一个Task执行。举例:如果有100个分区,那么RDD上有 n 个操作将会产生有 n*100 个任务。
- 通俗来讲,可以将RDD理解为一个分布式对象集合,本质上是一个只读的分区记录集合。每个RDD可以分成多个分区,每个分区就是一个数据集片段。一个RDD的不同分区可以保存到集群中的不同结点上,从而可以在集群中的不同节点上进行并行计算。
2.2 compute函数
- 每个分区上都有计算函数,计算该分区中的数据
2.3 依赖关系
- 一个RDD会依赖于其他多个RDD。
- RDD的每次转换都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在部分分区数据丢失时,Spark可以通过这个依赖关系重新计算丢失的分区数据,而不是对RDD的所有分区进行重新计算。(Spark的容错机制)
2.4 分区器(Partitioner)
- Spark中的分区函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。
- 对于KV类型的RDD会有一个Partitioner函数,即RDD的分区函数(可选项)
- 只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数决定了RDD本身的分区数量,也决定了parent RDD Shuffle输出时的分区数量。
2.5 分区优先位置列表
- 该列表存储了存取每个分区的优先位置 。对于一个 HDFS文件来说,这个列表保存了每个分区所在的数据块的位置。按照 “移动数据不如移动计算的” 的理念, Spark在进行任务调度的时候,会尽可能的将计算任务移动到所要处理的数据块的存储位置。
3、RDD弹性(容错)
- 也可以理解为Spark容错

- 自动进行内存和磁盘数据存储的切换
Spark 优先把数据放到内存中,如果内存放不下,就会放到磁盘里面,程序进行自动的存储切换。 - 基于血统的高效容错机制
在 RDD 进行转换和动作的时候,会形成 RDD 的 Lineage 依赖链,当某一个 RDD 失效的时候,可以通过重新计算上游的 RDD 来重新生成丢失的 RDD 数据。 - Task 如果失败会自动进行特定次数的重试
RDD 的计算任务如果运行失败,会自动进行任务的重新计算,默认次数是 4 次。 - Stage 如果失败会自动进行特定次数的重试
如果 Job 的某个 Stage 阶段计算失败,框架也会自动进行任务的重新计算,默认次数也是 4 次。 - Checkpoint 和 Persist 可主动或被动触发
RDD 可以通过 Persist 持久化将 RDD 缓存到内存或者磁盘,当再次用到该 RDD 时直接读取就行。也可以将 RDD 进行检查点,检查点会将数据存储在 HDFS 中,该 RDD 的所有父 RDD 依赖都会被移除。 - 数据调度弹性
Spark 把这个 JOB 执行模型抽象为通用的有向无环图 DAG,可以将多 Stage 的任务串联或并行执行,调度引擎自动处理 Stage 的失败以及 Task 的失败。 - 数据分片的高度弹性
可以根据业务的特征,动态调整数据分片的个数,提升整体的应用执行效率。
4、特点
\quad \quad RDD 表示只读的分区的数据集,对 RDD 进行改动,只能通过 RDD 的转换操作,由一个 RDD 得到一个新的 RDD,新的 RDD 包含了从其他 RDD 衍生所必需的信息。RDDs 之间存在依赖,RDD 的执行是按照血缘关系延时计算的。如果血缘关系较长,可以通过持久化 RDD 来切断血缘关系。
4.1 只读
- RDD 是只读的,要想改变 RDD 中的数据,只能在现有的 RDD 基础上创建新的 RDD。
- 可通过算子进行转换
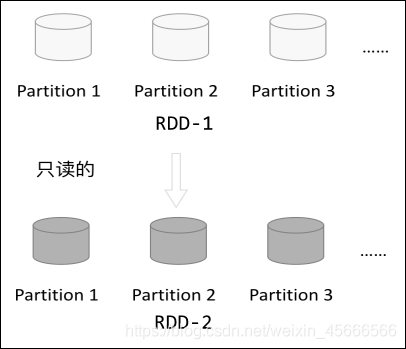
- 常用算子

4.2 分区
\quad \quad RDD 逻辑上是分区的,每个分区的数据是抽象存在的,计算的时候会通过一个 compute 函数得到每个分区的数据。如果 RDD 是通过已有的文件系统构建,则 compute 函数是读取指定文件系统中的数据,如果 RDD 是通过其他 RDD 转换而来,则 compute 函数是执行转换逻辑将其他 RDD 的数据进行转换。
4.3 依赖
- RDDs 通过操作算子进行转换,转换得到的新 RDD 包含了从其他 RDDs 衍生所必需的信息,RDDs 之间维护着这种血缘关系,也称之为依赖。
- 详细信息见博文
4.4 缓存
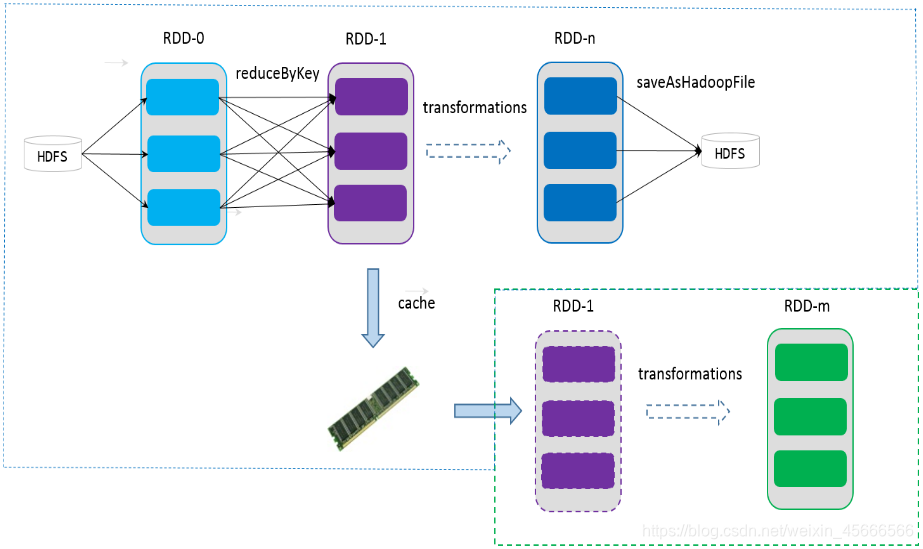
\quad \quad 如果在应用程序中多次使用同一个 RDD,可以将该 RDD 缓存起来,该 RDD 只有在第一次计算的时候会根据血缘关系得到分区的数据,在后续其他地方用到该 RDD 的时候,会直接从缓存处取而不用再根据血缘关系计算,这样就加速后期的重用。如下图所示,RDD-1 经过一系列的转换后得到 RDD-n 并保存到 hdfs,RDD-1 在这一过程中会有个中间结果,如果将其缓存到内存,那么在随后的 RDD-1 转换到 RDD-m 这一过程中,就不会计算其之前的 RDD-0 了。
4.5 CheckPoint
\quad \quad 虽然 RDD 的血缘关系天然地可以实现容错,当 RDD 的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs 之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD 支持 checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为 checkpoint 后的 RDD 不需要知道它的父 RDDs 了,它可以从 checkpoint 处拿到数据。
\quad \quad 给定一个 RDD 我们至少可以知道如下几点信息:
1、分区数以及分区方式;
2、由父 RDDs 衍生而来的相关依赖信息;
3、计算每个分区的数据,计算步骤为:
1)如果被缓存,则从缓存中取的分区的数据;
2)如果被 checkpoint,则从 checkpoint 处恢复数据;
3)根据血缘关系计算分区的数据。