RDD CheckPoint
1、概述
\quad \quad 虽然 RDD 的血缘(依赖)关系天然地可以实现容错,当 RDD 的某个分区数据失败或丢失,可以通过血缘关系重建。但是对于长时间迭代型应用来说,随着迭代的进行,RDDs 之间的血缘关系会越来越长,一旦在后续迭代过程中出错,则需要通过非常长的血缘关系去重建,势必影响性能。为此,RDD 支持 checkpoint 将数据保存到持久化的存储中,这样就可以切断之前的血缘关系,因为 checkpoint 后的 RDD 不需要知道它的父 RDDs 了,它可以从 checkpoint 处拿到数据。
\quad \quad 虽然Spark中对于数据的保存给与cache或者persist放到内存或者磁盘中持久化操作,但是这样也不能保证数据完全不会丢失,存储的这个内存出问题了或者磁盘坏了,也会导致spark从头再根据RDD计算一遍;所以就有了checkpoint(检查点)。
2、作用
\quad \quad checkpoint的作用就是将DAG中比较重要的中间数据做一个检查点将结果存储到一个高可用的地方(通常这个地方是支持分布式存储和副本机制的 HDFS)。
3、特性
-
checkpoint是transformation,当遇到Action时,checkpoint会启动另一个任务,将数据切割拆分,保存到设置的checkpoint目录中。
-
当使用了checkpoint后,数据被保存到HDFS,此RDD的所有依赖关系也会丢掉,因为数据已经持久化到硬盘,不需要重新计算。
-
对RDD进行checkpoint操作并不会马上被执行,必须执行Action操作才能触发。
-
强烈推荐先将数据持久化到内存中(cache操作),否则直接使用checkpoint会开启一个计算,浪费资源。
4、应用
前提:
\quad \quad 在使用 Checkpoint 之前需要先设置 Checkpoint 的存储路径, 而且如果任务在集群中运行的话, 这个路径必须是 HDFS 上的路径。即设置检查点。
如何设置检查点?
\quad \quad 用sparkContext设置hdfs的checkpoint的目录(如果不设置使用checkpoint会抛出异常:throw new SparkException(“Checkpoint directory has not been set in the SparkContext”):
scala> sc.setCheckpointDir("hdfs://master:9000/checkpoint1")
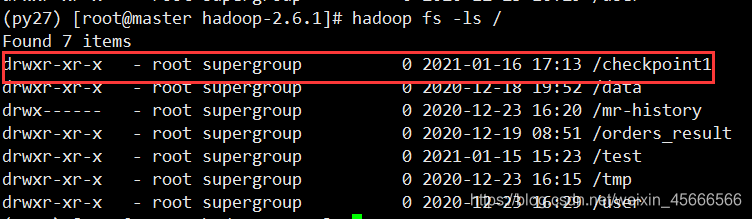
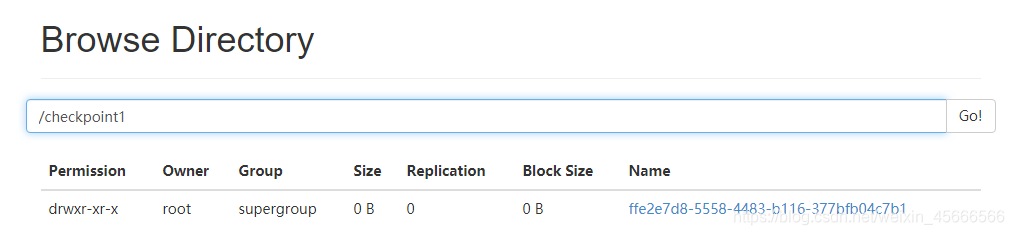
执行了上面的代码,hdfs里面会创建一个目录:
/checkpoint1/ffe2e7d8-5558-4483-b116-377bfb04c7b1
- shell命令查看

- 网页面查看
checkpoint的目录设置好后,如下就可以使用:
rdd.cache()
rdd.checkpoint()
rdd.collect
- 应该在 checkpoint 之前先 cache 一下, 因为 checkpoint 会重新计算整个 RDD 的数据然后再存入 HDFS 等地方。所以如果 checkpoint 之前没有 cache, 则整个任务流程会被多计算一次, 多余的一次是 checkpoint。
小小案例:
1)设置检查点
scala> sc.setCheckpointDir("hdfs://master:9000/checkpoint1")
2)创建一个RDD
scala> val rdd = sc.parallelize(Array("atguigu"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[207] at parallelize at <console>:26
3)将RDD转换为携带当前时间戳并做缓存
scala> val ch = rdd.map(_+System.currentTimeMillis)
ch: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[208] at map at <console>:28
scala> ch.cache
res47: ch.type = MapPartitionsRDD[208] at map at <console>:28
4)做checkpoint
scala> ch.checkpoint
5)多次打印结果
scala> ch.collect
res49: Array[String] = Array(atguigu1610789426206)
scala> ch.collect
res50: Array[String] = Array(atguigu1610789426206)
- 查看hdfs检查目录

5、Checkpoint 和 Cache、Persist 的区别
\quad \quad Cache 可以把 RDD 计算出来然后放在内存中, 但是 RDD 的依赖链(相当于 NameNode 中的 Edits 日志)是不能丢掉的, 因为这种缓存是不可靠的, 如果出现了一些错误(例如 Executor 宕机), 这个 RDD 的容错就只能通过回溯依赖链, 重放计算出来。但是 Checkpoint 把结果保存在 HDFS 这类存储中, 就是可靠的了, 所以可以斩断依赖, 如果出错了, 则通过复制 HDFS 中的文件来实现容错。
区别主要在以下两点
-
Checkpoint 可以保存数据到 HDFS 这类可靠的存储上, Persist 和 Cache 只能保存在本地的磁盘和内存中
-
Checkpoint 可以斩断 RDD 的依赖链, 而 Persist 和 Cache 不行
-
因为 CheckpointRDD 没有向上的依赖链, 所以程序结束后依然存在, 不会被删除. 而 Cache 和 Persist 会在程序结束后立刻被清除.