文章目录
引言
以Kaggle房价回归预测为例,来叙述回归问题中数据预处理与特征工程的一般流程,这是参考公开notebook的,觉得人家写的很条理,不像自己的都拼西凑。刚买了《python数据分析与挖掘实战》,希望系统的学习一下!
一、数据预处理
1.数据集的基本信息
加载数据集
# 加载数据集
train = pd.read_csv('../input/house-prices-advanced-regression-techniques/train.csv',header=0,index_col=0)
test = pd.read_csv('../input/house-prices-advanced-regression-techniques/test.csv',header=0,index_col=0)
# 以 f开头表示在字符串内支持大括号内的python 表达式,与常见的以r开头是同一类用法,只不过以r开头是去掉反斜杠机制
print (f"Train has {train.shape[0]} rows and {train.shape[1]} columns")
print (f"Test has {test.shape[0]} rows and {test.shape[1]} columns")
关于数值变量的统计信息
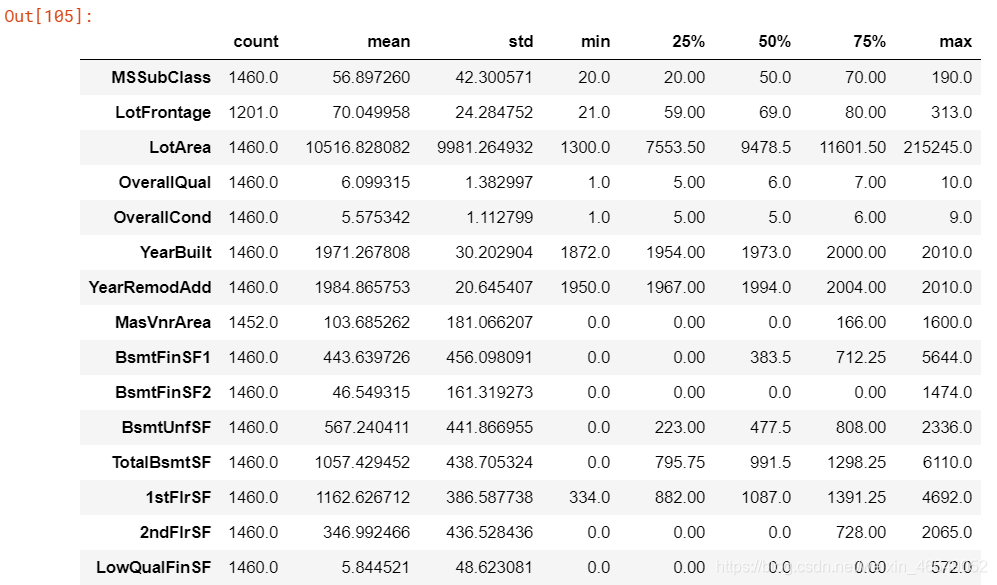
# 这里的转置是因为变量比较多,转置后方便观察
train.describe().T
对所有特征变量的属性,内存等信息的统计
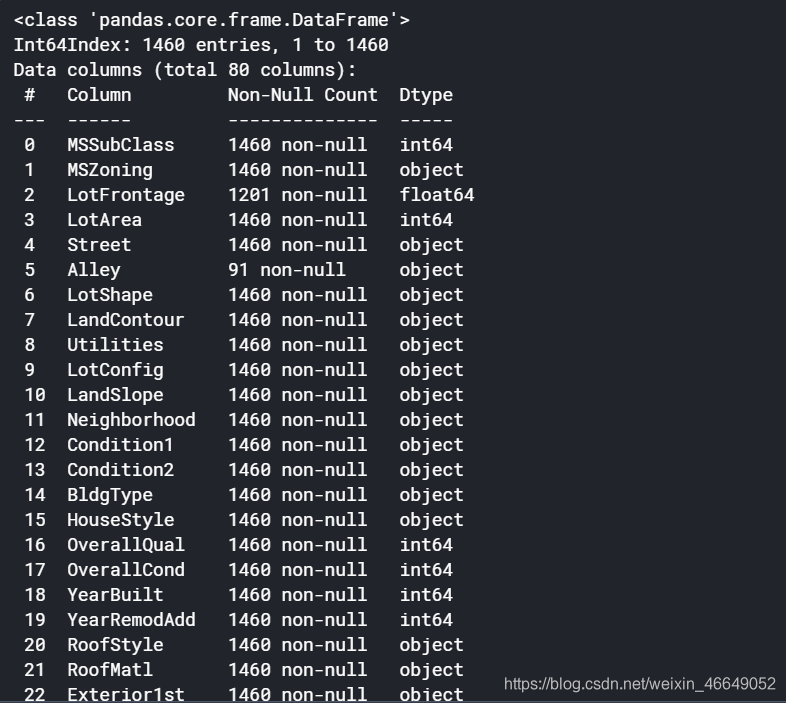
train.info()
统计不同类型对象的个数
train.dtypes.value_counts()

2.缺失值统计及可视化
使用missingno进行缺失值可视化,训练集与测试集分别进行
mg.matrix(train)

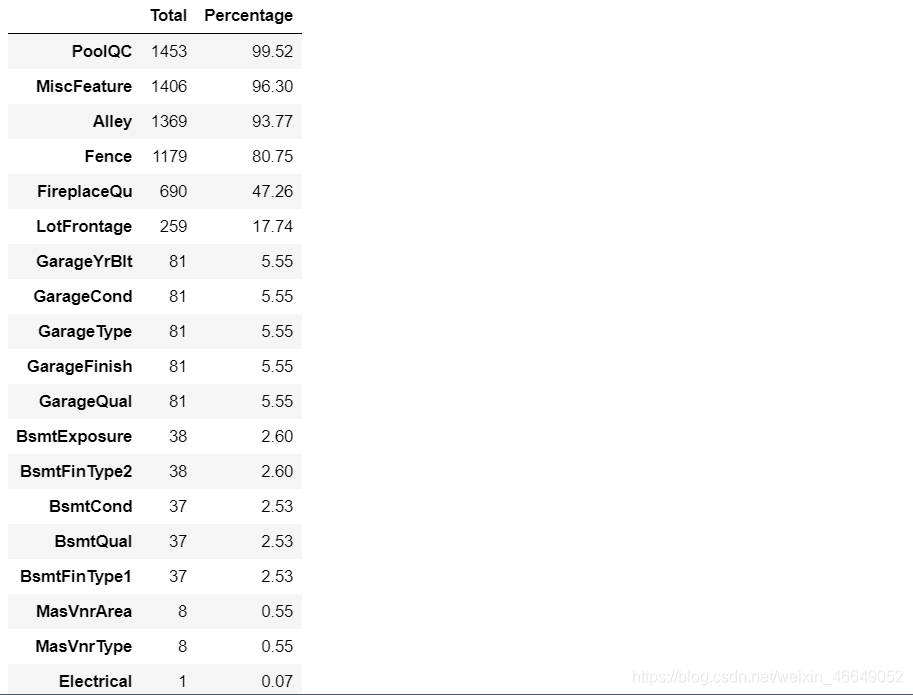
统计每个变量的缺失比例
# 定义一个统计每个变量缺失比例的函数
def missing_percentage(df):
total = df.isnull().sum().sort_values(ascending = False)[df.isnull().sum().sort_values(ascending = False) != 0]
percentage = round(df.isnull().sum().sort_values(ascending=False)*100 / len(df),2)[df.isnull().sum().sort_values(ascending=False)*100 / len(df) != 0]
return pd.concat([total,percentage],axis = 1,keys=['Total','Percentage'])
missing_percentage(train)
3.变量分析
3.1目标变量的分析
分析目标标量,建立直方图与连续概率估计图,数据和正态分布分位数的拟合图,箱型图
def plot_1(df,feature):
# 一种图的格式
style.use('fivethirtyeight')
fig,axes = plt.subplots(3,1,constrained_layout=True,figsize=(10,24))
# 画直方图与连续概率密度估计图
# norm_hist=True:如果为True,则直方图的高度显示密度而不是计数
sns.distplot(df.loc[:,feature],norm_hist=True,ax=axes[0])
# 通过比较数据和正态分布的分位数是否相等来判断数据是不是符合正态分布
stats.probplot(df.loc[:,feature],plot=axes[1])
# 箱型图
sns.boxplot(df.loc[:,feature],orient='h',ax=axes[2])
plot_1(train,'SalePrice')
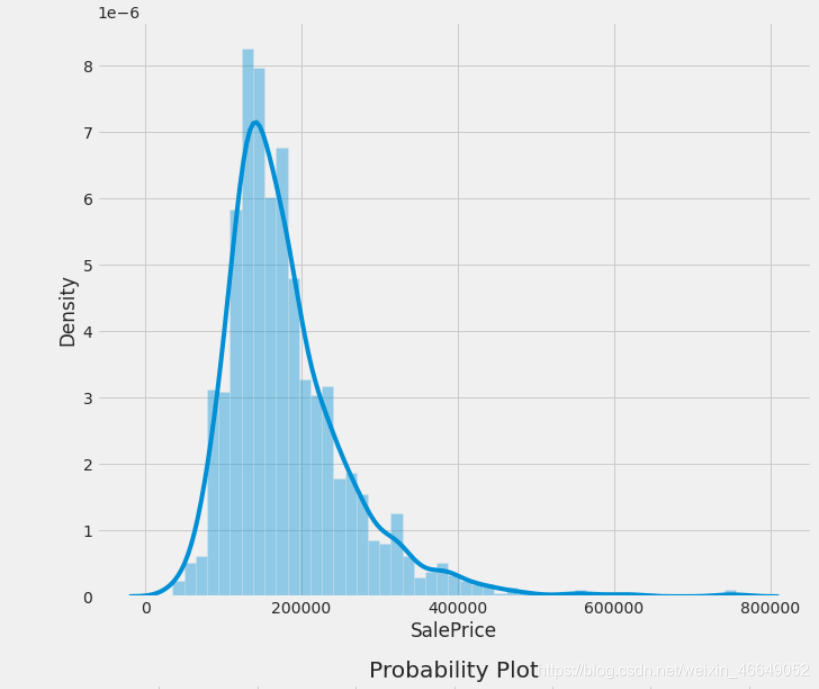

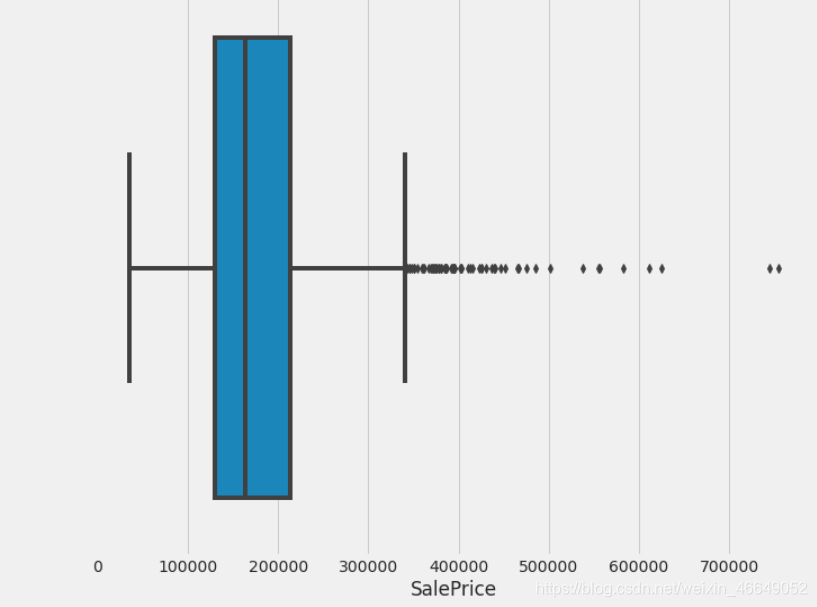
我们从上图可知,目标变量的分布不是正态分布;右偏(这里的左右指拖尾方向);有异常值
用偏态与峰度定量描述
train.SalePrice.skew(),train.SalePrice.kurtosis()

3.2分析目标变量与类别型变量的关系
箱型图适合类别变量,以下面这个变量为例:
# 箱型图适合类别变量,这是为类别变量定制的
def customized_cat_boxplot(y, x):
style.use('fivethirtyeight')
plt.subplots(figsize=(12,8))
sns.boxplot(y=y,x=x)
customized_cat_boxplot(train.SalePrice, train.OverallQual)
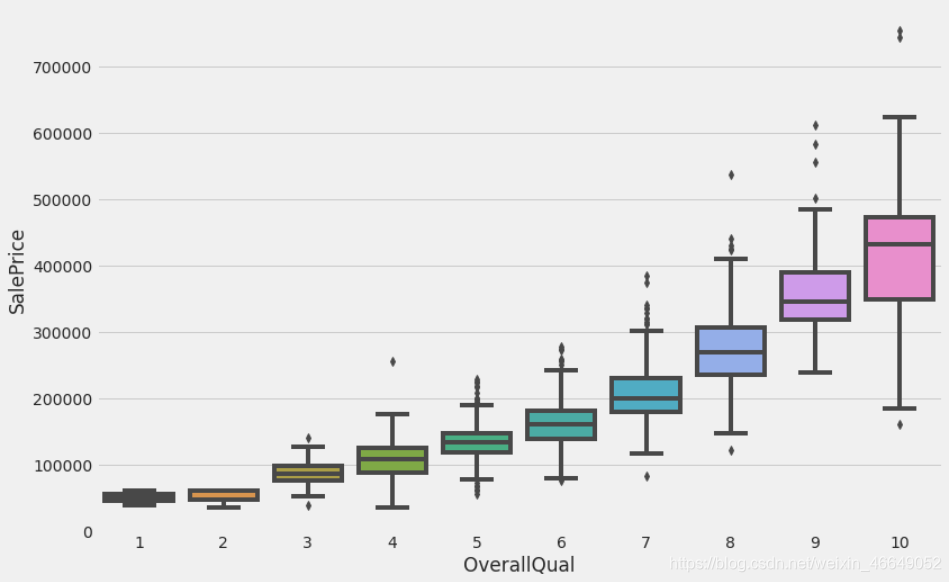
通过上述箱型图,我们可以很轻松的发现:房屋的价格随着整体质量的提高而上涨。
3.3 分析目标变量与连续型变量的关系
散点图适合连续变量,以下面的变量为例
# 散点图适合连续变量,这是为连续变量定制的
def customized_num_scatterplot(y, x):
style.use('fivethirtyeight')
plt.subplots(figsize=(12,8))
sns.scatterplot(y=y,x=x)
customized_num_scatterplot(train.SalePrice, train.GrLivArea)
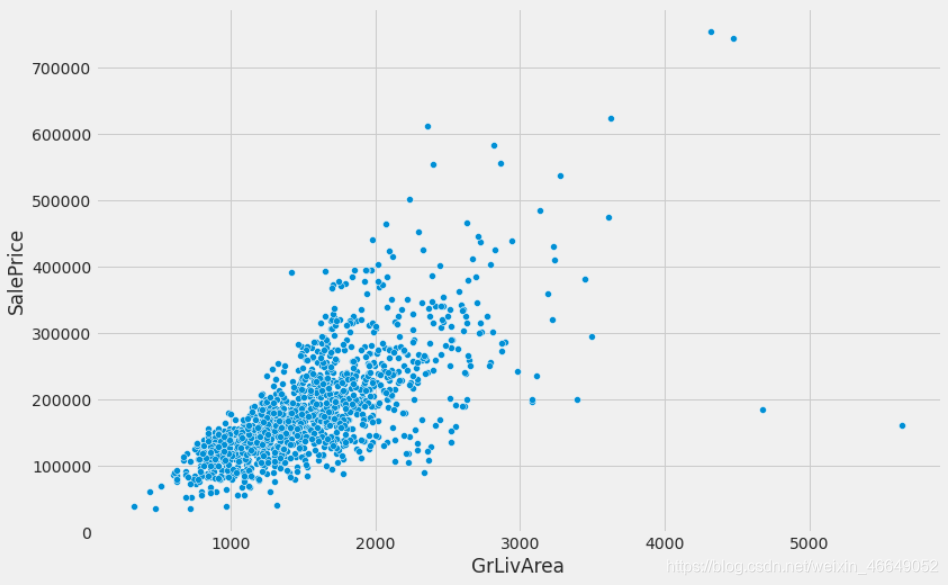
通过散点图,我们不仅可以发现"GrLivArea"变量与"SalePrice"变量有相同的趋势,并且从图中可以看出有两个异常点,这两个点稍后会删除。
customized_num_scatterplot(train.SalePrice, train['1stFlrSF'])
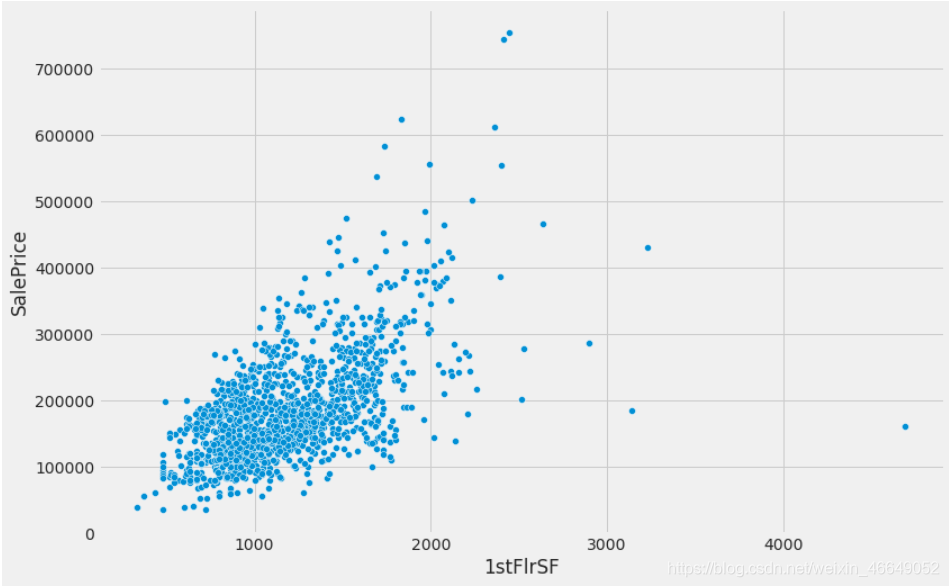
# 删除这两个异常值
train = train[train.GrLivArea < 4500]
# 此时发现:TotalBsmtSF中的异常点也在其中,1stFlrSF中的异常点也在其中。并且最关键的问题是索引不连续了,此时就要重置索引
train.reset_index(drop = True, inplace = True)
残差图可以看出变量是否满足同方差假设
plt.subplots(figsize = (12,8))
sns.residplot(train.GrLivArea, train.SalePrice)
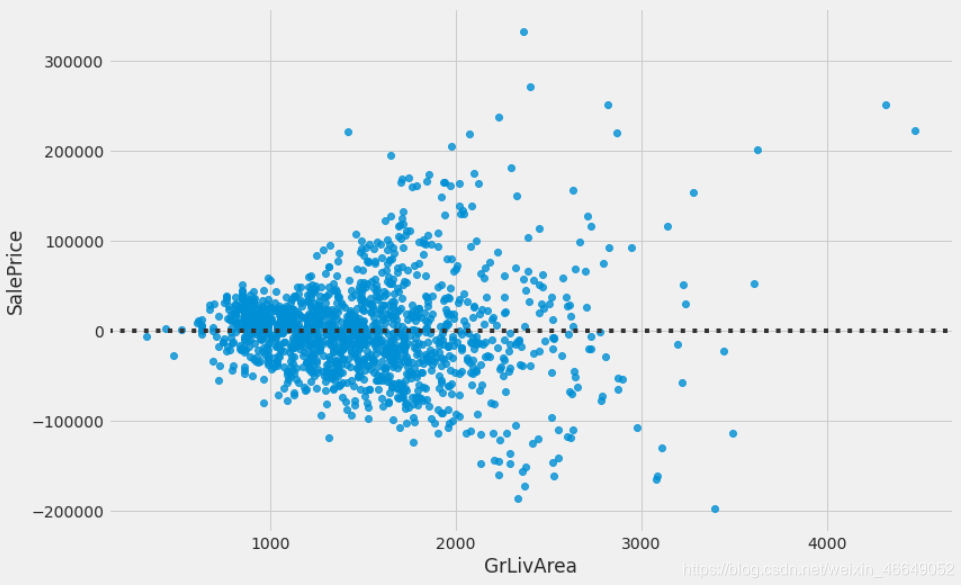
理想情况下,如果假设满足,残差将随机分散在为零的中心线上,没有明显的模式。看起来像一个以0为中心的非结构化的点云。然而,我们的剩余图不是一个非结构化的点云。尽管响应变量和预测变量之间似乎存在线性关系,但残差图看起来更像一个漏斗。残差图显示,随着GrLivArea值的增加,方差也随之增加,这就是所谓的异方差特征。
3.4数据变换
同方差的假设对于线性回归模型至关重要。同方差描述了这样一种情况,其中自变量与因变量之间的关系中的方差在自变量的所有值上均相同。换句话说,随着预测变量的增加,响应变量中存在恒定的方差。解决异方差的一种方法是使用一种变换方法,比如对数变换或者box-cox变换。
建立直方图与连续概率估计图,数据和正态分布分位数的拟合图,来分析目标变量与连续变量的多元正态性(误差正态性)。
3.4.1目标变量
plot_1(train,'SalePrice') # 结果如上图
# 对数变换
train['SalePrice'] = np.log1p(train['SalePrice'])
# 检验其正态性
plot_1(train,'SalePrice')
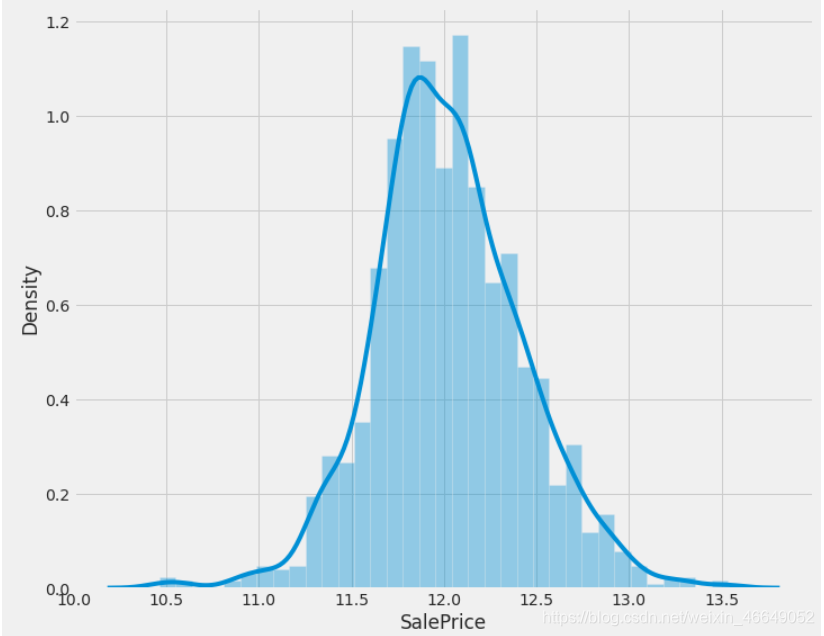
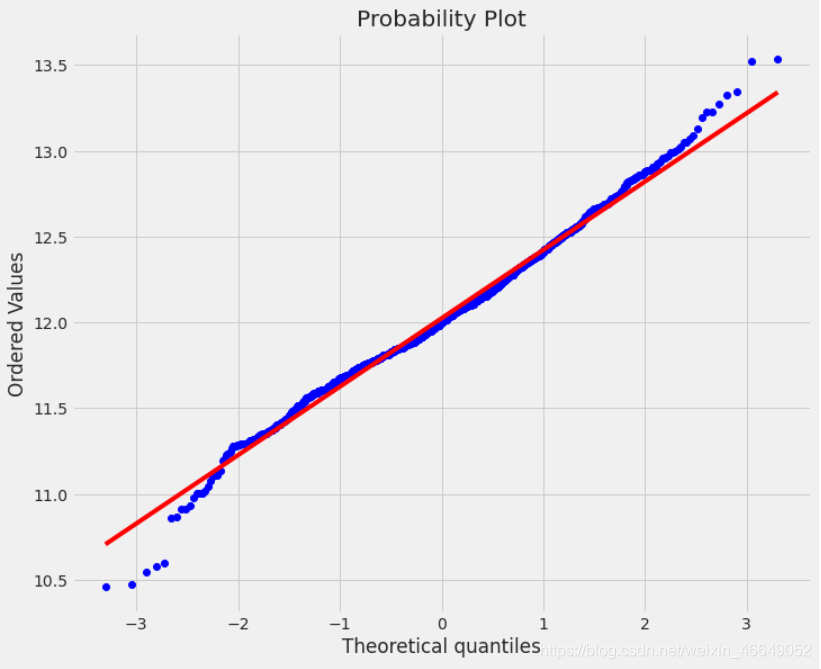

在通过数据变换使分布更接近于正态分布之后,发现同方差性明显改善。
## Customizing grid for two plots.
fig, (ax1, ax2) = plt.subplots(figsize = (15,6),
ncols=2,
sharey = False,
sharex=False
)
## doing the first scatter plot.
sns.residplot(x = previous_train.GrLivArea, y = previous_train.SalePrice, ax = ax1)
## doing the scatter plot for GrLivArea and SalePrice.
sns.residplot(x = train.GrLivArea, y = train.SalePrice, ax = ax2)
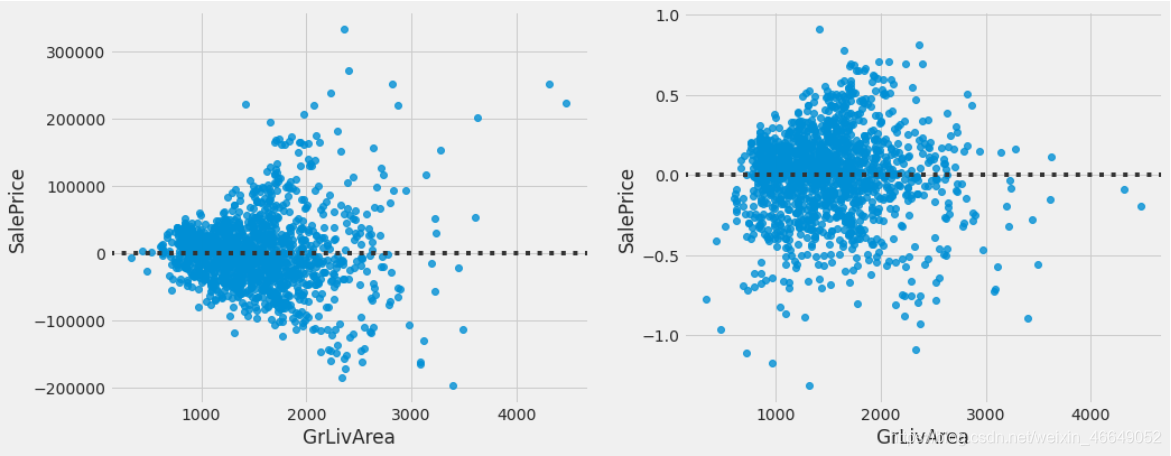
左边的预转换图表具有异方差性,而右边的后转换图表具有同方差性(在零线上的方差几乎相等)。它看起来像一团数据点。
3.4.2 连续变量采用box-cox变换
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
skewed_feats = all_data[numeric_feats].apply(lambda x: x.skew()).sort_values(ascending=False)
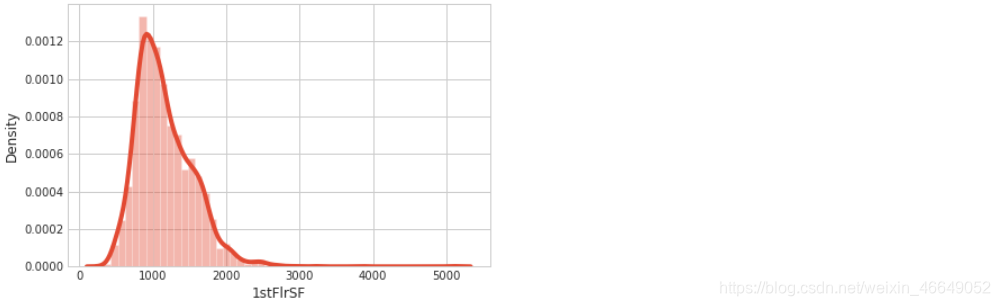
# 展示'1stFlrSF'的直方图与连续概率密度估计
sns.distplot(all_data['1stFlrSF'])
def fixing_skewness(df):
"""
This function takes in a dataframe and return fixed skewed dataframe
"""
## Import necessary modules
from scipy.stats import skew
from scipy.special import boxcox1p
from scipy.stats import boxcox_normmax
## Getting all the data that are not of "object" type.
numeric_feats = df.dtypes[df.dtypes != "object"].index
# Check the skew of all numerical features
skewed_feats = df[numeric_feats].apply(lambda x: x.skew()).sort_values(ascending=False)
high_skew = skewed_feats[abs(skewed_feats) > 0.5]
skewed_features = high_skew.index
# 修正
for feat in skewed_features:
# 这里的+1只是确保非负,没有其他含义
df[feat] = boxcox1p(df[feat], boxcox_normmax(df[feat] + 1))
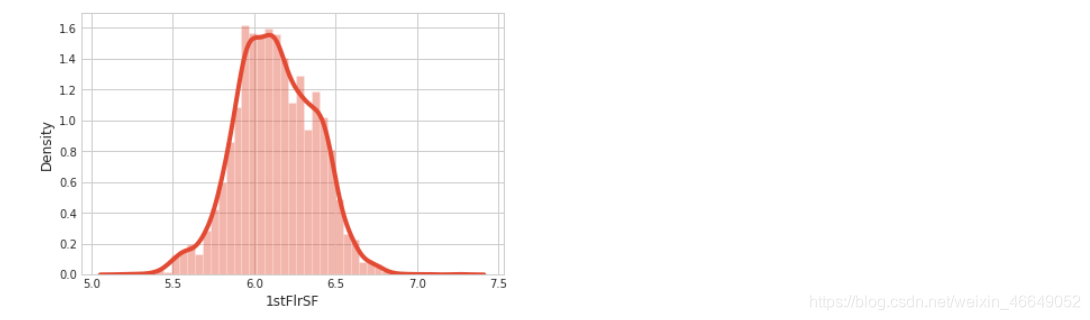
fixing_skewness(all_data)
sns.distplot(all_data['1stFlrSF'])
3.5线性与多重共线性分析
当自变量之间有很强的相关性时会出现多重共线性。线性回归或多线性回归要求自变量很少或没有类似的特征。多重共线性会导致各种问题,包括:
- 回归估计的预测变量的效果将取决于我们的模型中包含的其他变量
- 样本中的微小变化可能会导致估计效果大不相同
- 由于多重共线性度很高,逆矩阵的计算可能不准确
- 我们不能再把变量上的系数解释为保持其他变量不变,变量每增加一个单位对目标的影响。
这背后的原因是,当预测因子紧密相关时,不存在一个变量可以改变而另一个变量不发生条件变化的情况。
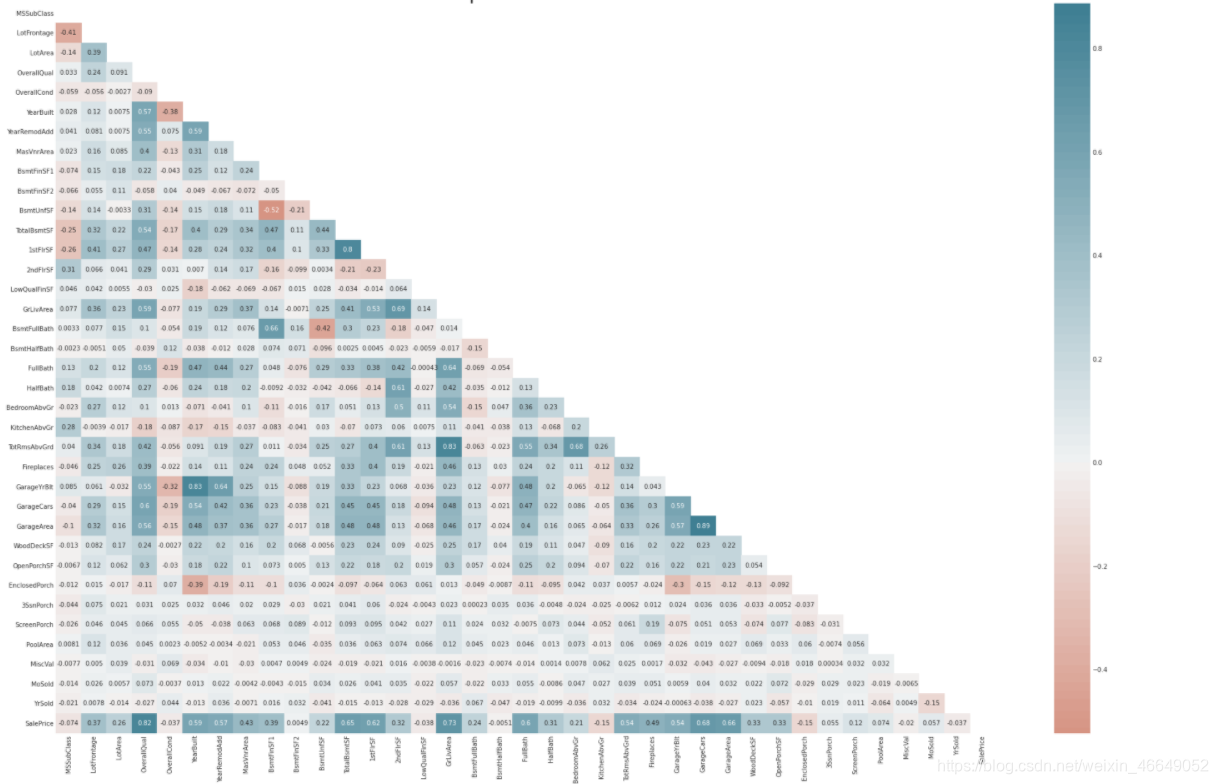
Heatmap是识别是否存在多重共线性的好方法。解决多重共线性的最好方法是使用正则化方法。理论上,L1正则会比L2正则效果好。
# Plot fig sizing.
style.use('ggplot')
sns.set_style('whitegrid')
plt.subplots(figsize = (30,20))
# Plotting heatmap.
# Generate a mask for the upper triangle (taken from seaborn example gallery)
mask = np.zeros_like(train.corr(), dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
sns.heatmap(train.corr(),
cmap=sns.diverging_palette(20, 220, n=200),
mask = mask,
annot=True,
center = 0,
)
# Give title.
plt.title("Heatmap of all the Features", fontsize = 30)
4.填充缺失值
这一部分的关键在于要明白变量背后的实际意义,这里要结合工程背景。否则,统一的对数据进行填充操作,会增加大量的“噪声”。
有些类别特征中,缺失值本身就有其含义;比如Alley特征,缺失表明没有巷子,将这一类中的缺失值用’None’来填充。
missing_val_col = ["Alley",
"PoolQC",
"MiscFeature",
"Fence",
"FireplaceQu",
"GarageType",
"GarageFinish",
"GarageQual",
"GarageCond",
'BsmtQual',
'BsmtCond',
'BsmtExposure',
'BsmtFinType1',
'BsmtFinType2',
'MasVnrType']
for i in missing_val_col:
all_data[i] = all_data[i].fillna('None')
有些连续特征中存在缺失值是有意义的,我们将其替换为0
missing_val_col2 = ['BsmtFinSF1',
'BsmtFinSF2',
'BsmtUnfSF',
'TotalBsmtSF',
'BsmtFullBath',
'BsmtHalfBath',
'GarageYrBlt',
'GarageArea',
'GarageCars',
'MasVnrArea']
for i in missing_val_col2:
all_data[i] = all_data[i].fillna(0)
有些特征中的缺失值与其他特征有关系,此时,先分桶在填充
# 将'Neighborhood'分桶,用对应桶内'LotFrontage'的均值来填充缺失值
all_data['LotFrontage'] = all_data.groupby('Neighborhood')['LotFrontage'].transform( lambda x: x.fillna(x.mean()))
还有一些结合变量实际背景做的操作。
# 有些类别特征以数字形式给出,所以要转变成类别变量
all_data['MSSubClass'] = all_data['MSSubClass'].astype(str)
# mode指的是最常出现的值
all_data['MSZoning'] = all_data.groupby('MSSubClass')['MSZoning'].transform(lambda x: x.fillna(x.mode()[0]))
# 重要的年份和月份应当是类别变量而不是连续变量
all_data['YrSold'] = all_data['YrSold'].astype(str)
all_data['MoSold'] = all_data['MoSold'].astype(str)
all_data['Functional'] = all_data['Functional'].fillna('Typ')
all_data['Utilities'] = all_data['Utilities'].fillna('AllPub')
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
all_data['KitchenQual'] = all_data['KitchenQual'].fillna("TA")
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
all_data['Electrical'] = all_data['Electrical'].fillna("SBrkr")
二、特征工程
1.特征组合
特征组合是建立在业务逻辑上的。就比如第一个特征组合的实际含义是:地下室总面积+一楼面积+二楼面积=房子的总面积。第二个特征组合的实际含义是:房子的两次动工日期的和。
# feture engineering a new feature "TotalFS"
all_data['TotalSF'] = (all_data['TotalBsmtSF']
+ all_data['1stFlrSF']
+ all_data['2ndFlrSF'])
all_data['YrBltAndRemod'] = all_data['YearBuilt'] + all_data['YearRemodAdd']
all_data['Total_sqr_footage'] = (all_data['BsmtFinSF1']
+ all_data['BsmtFinSF2']
+ all_data['1stFlrSF']
+ all_data['2ndFlrSF']
)
all_data['Total_Bathrooms'] = (all_data['FullBath']
+ (0.5 * all_data['HalfBath'])
+ all_data['BsmtFullBath']
+ (0.5 * all_data['BsmtHalfBath'])
)
all_data['Total_porch_sf'] = (all_data['OpenPorchSF']
+ all_data['3SsnPorch']
+ all_data['EnclosedPorch']
+ all_data['ScreenPorch']
+ all_data['WoodDeckSF']
)
2.增加特征
下面的面积中,没有面积为0,有面积为1,这个工作效果得尝试,因为逻辑上面积大的就应该比面积小的贵点,而同时转换为1,反而忽略了差异性。这里增加了特征,直接交给正则化模型来判断选取哪一个,不失为好的办法。
all_data['haspool'] = all_data['PoolArea'].apply(lambda x: 1 if x > 0 else 0)
all_data['has2ndfloor'] = all_data['2ndFlrSF'].apply(lambda x: 1 if x > 0 else 0)
all_data['hasgarage'] = all_data['GarageArea'].apply(lambda x: 1 if x > 0 else 0)
all_data['hasbsmt'] = all_data['TotalBsmtSF'].apply(lambda x: 1 if x > 0 else 0)
all_data['hasfireplace'] = all_data['Fireplaces'].apply(lambda x: 1 if x > 0 else 0)
3.特征选择
这一部分放到特征工程里我觉得比较好,因为经过上面两步可能会造出常量型或者类常量型特征,这一类特征在模型中就是噪声。
all_data = all_data.drop(['Utilities', 'Street', 'PoolQC'], axis=1)
all_data.shape
# 删除接近于常量的变量
def overfit_reducer(df):
"""
This function takes in a dataframe and returns a list of features that are overfitted.
"""
overfit = []
for i in df.columns:
counts = df[i].value_counts()
zeros = counts.iloc[0]
# 这里的比例我觉得可以调小一点,不过有可能删除有用特征
if zeros / len(df) * 100 > 99.94:
overfit.append(i)
overfit = list(overfit)
return overfit
overfitted_features = overfit_reducer(X_train)
print(overfitted_features)
X_train = X_train.drop(overfitted_features, axis=1)
X_test = X_test.drop(overfitted_features, axis=1)
4.编码
如果是one-hot编码的话,它应该放在第三步之前,理由:有可能造成常量型特征。同时,由于one-hot进行特征打散的影响,其实是会增加树的深度。针对取值特别多的离散特征,我们可以通过embedding的方式映射成低纬向量。与单热编码相比,实体嵌入不仅减少了内存使用并加速了神经网络,更重要的是通过在嵌入空间中映射彼此接近的相似值,它揭示了分类变量的内在属性。
如果对您有帮助,麻烦点赞关注,这真的对我很重要!!!如果需要互关,请评论留言!
