申请评分卡中的数据预处理和特征衍生(下)
在上一遍申请评分卡中的数据预处理和特征衍生(上),我们主要讲解了
- 构建信用风险类型的特征
- 特征分箱
- WOE编码
也就是对应图中(数据预处理、特征构造)

这篇文章我们主要讲解特征选择,要学习特征选择,就要学习以下的知识点
- 特征信息度的计算和意义
- 信用风险中的单变量分析和多变量分析


特征信息度的计算和意义
在申请评分卡这一块,主要以应用特征信息度为主
IV(information value)衡量的是某一个变量的信息量,公式如下:
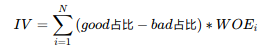
N为分组的组数;
IV可用来表示一个变量的预测能力。

根据IV值来调整分箱结构并重新计算WOE和IV,直到IV达到最大值,此时的分箱效果最好。
分组一般原则:组间差异大、组内差异小、每组占比不低于5%、必须有好、坏两种分类

特征信息度的作用:

举个例子,如何计算IV
例如按年龄分组,一般进行分箱,我们都喜欢按照少年、青年、中年、老年几大类进行分组,但效果真的不一定好:

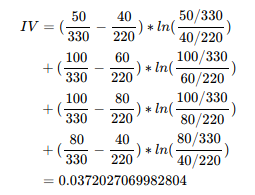
根据IV值可以看出,预测能力低。
信用风险中的单变量分析和多变量分析
- 单变量分析


分箱后的IV分布,可以定一个阈值,当IV小于0.01(自己根据业务定义)舍弃该变量

- 多变量分析:变量的两两相关性

如何计算相关性(皮尔逊相关系数),之前单变量分析已经排除IV<=0.01的变量了,剩下的变量计算WOE相关矩阵,自己定一个系系数,当相关性大于0.7则可以按照上面的步骤来解决,要不就选两者IV值较高的,要不就选变量分箱比较均衡的,分享比较均衡最后算出来的分数分布比较广,进行多级分类(好、坏、中、达标)建议选择分箱比较均衡的

之后我们还要考虑变量的多重共线性(用VIF来衡量),一般VIF的最大值小于10则不需要剔除变量
比如x7与xi单个变量之间皮尔逊相关系数都是很小的,但是这一些变量组合到一块,X7可以同xi线性表达出来,此时VIF很大概率就大于10,大于10的时候,我们可以按照下面的步骤来解决
