申请评分卡中的数据预处理和特征衍生
本章文章主要讲解以下内容
- 构建信用风险类型的特征
- 特征分箱
- WOE编码
构建信用风险类型的特征
在我们运用模型之前,我们首先要进行特征工程,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。(下图引用了一幅图片http://www.cnblogs.com/jasonfreak/p/5448385.html)
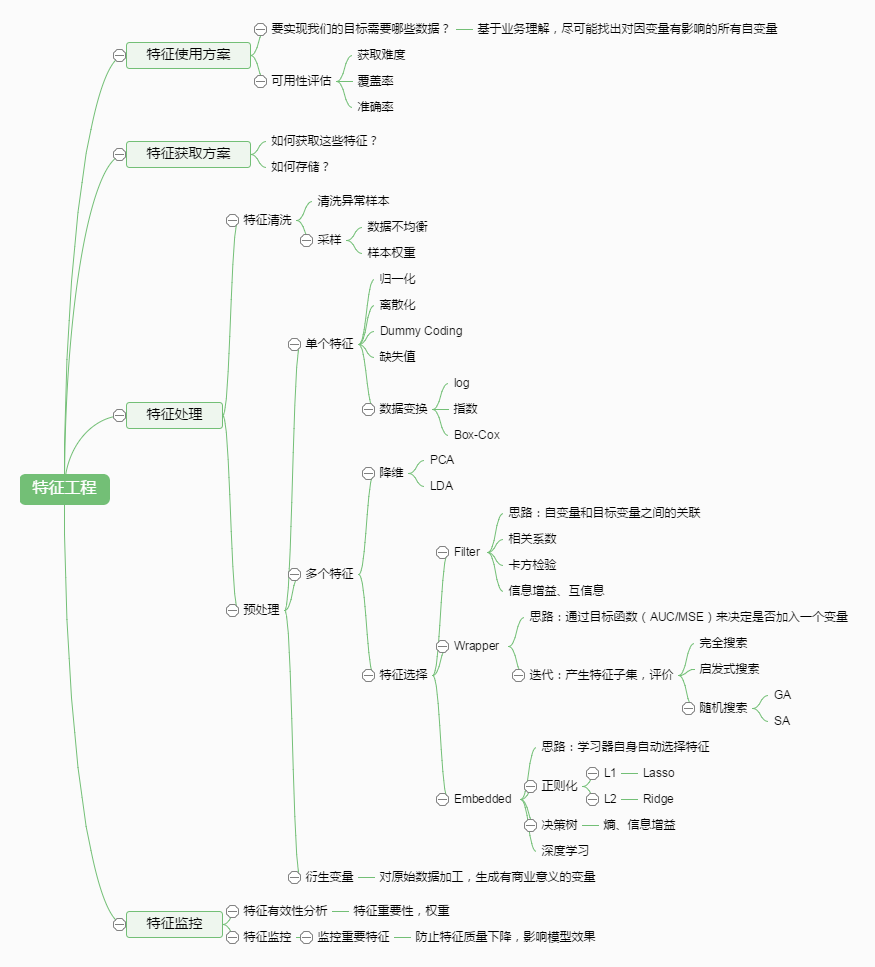

- 数据预处理
1.原数据带有一定格式,需要转换成正确格式

2.文本类的数据处理方式
主题提取(NLP自然语言处理)

编码(打个比方说就是有数据为1,没有数据为0,可以用0和1区分他们的状态)

3.缺失值
在我们分析问题中,往往会存在一些缺失值
缺失数据的分类:
完全随机缺失:若某变量的缺失数据与其他任何观测或未观测变量都不相关,则数据为完全随机缺失(MCAR)。
随机缺失:若某变量上的缺失数据与其他观测变量相关,与它自己的未观测值不相关,则数据为随机缺失(MAR)。
非随机缺失:若缺失数据不属于MCAR或MAR,则数据为非随机缺失(NMAR) 。
处理缺失值的方法(这里不细讲啦):补缺、作为一种状态
- 特征构造
到这一步,我们还需要根据专家经验或则一些算法衍生出一些新的特征

特征的分箱
分箱简单的解释是:分箱就是为了做到同组之间的差异尽可能的小,不同组之间的差异尽可能的大。
分箱的定义:
- 将连续变量离散化
- 将多状态的离散变量
分箱的重要性:
稳定性:避免特征中无意义的波动
健壮性:避免了极端值的影响
分箱的优势
可以将缺失作为独立的一个箱带入模型中
将所有变量变换到相似的尺度上
- 分箱的限制
计算量大
分享后需要编码
- 常用的分箱方法
如何区分有无监督?目标变量对分箱是否有影响,例如等频、等距分箱就没有受到目标变量的影响,就按照自己的原则分,所以在评分卡模型一般不使用无监督的分箱方式,没有考虑目标变量的影响,分箱效果自然不佳
- 有监督分箱(样本目标变量参与)
Best-ks分箱(只能针对二分类情况)最大ks值分

ks求解方法:
ks需要TPR和FPR两个值:真正类率(true positive rate ,TPR), 计算公式为TPR=TP/ (TP+ FN),刻画的是分类器所识别出的 正实例占所有正实例的比例。另外一个是假正类率(false positive rate, FPR),计算公式为FPR= FP / (FP + TN),计算的是分类器错认为正类的负实例占所有负实例的比例。KS=max(TPR-FPR)。其中:
- TP:真实为1且预测为1的数目
- FN:真实为1且预测为0的数目
- FP:真实为0的且预测为1的数目
- TN:真实为0的且预测为0的数目
对于离散很高的分类变量
- 编码(类别变量个数很多,先编码,再分箱。)
- 依据连续变量的方式进行分箱
ChiMerge卡方分箱(可以多分类情况)最小卡方值分
由于Best-ks分箱只能针对二分类情况,卡方分箱能进行多分类情况
自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。通俗的讲,即让组内成员相似性强,让组间的差异大。
基本思想:对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
想了解卡方分箱以及卡方分布,首先要知道卡方原理及应用,大家可以去该链接学习
https://segmentfault.com/a/1190000003719712
卡方分箱的步骤

卡方分箱的终止条件基本就是2条:
- 默认分到多少箱,如果已经分到了这个数值了,那就第2步
- 检查一下单调性,满足就完成分箱了,如果不满足,相邻的箱就合并,直到单调了为止,因为最后合并到2个箱的时候,是一定单调的。





- 无监督分箱(样本目标变量不参与)
等频分箱

等距分箱

为什么不推荐使用?

WOE编码
为什么要进行编码?我们分箱之后划分的区间模型不认识,我们要把他们编码,比如18岁在【10,20】内,【18,20】放进模型明显不合适。 WOE编码官方解释:一种有监督的编码方式,将预测类别的集中度的属性作为编码的数值;优势是:将特征的值规范到相近的尺度上。缺点是:需要分箱后每箱都同时有好坏样本(预测违约和不违约可是使用WOE编码,如果多分类情况WOE编码不适用),通常意义上,WOE的绝对值在0.1-3之间。
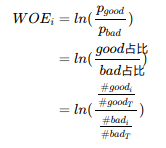
举例说明

编码的意义在于符号与好样本的比例有关;当好样本为分子,坏样本为分母的时候,可以要求回归模型的系数为负。