论文:PIXEL DECONVOLUTIONAL NETWORKS
代码:添加链接描述
总体介绍
一般反卷积产生的问题:checkerboard(棋盘格)
原因:由于中间特征图都是同时生成的,他们独立的,输出特征图上的相邻像素间不存在之间联系
该论文的方法:
中间特征图数顺序生成,有依赖关系,而不再仅仅依靠于输入特征图
该论文的结果:
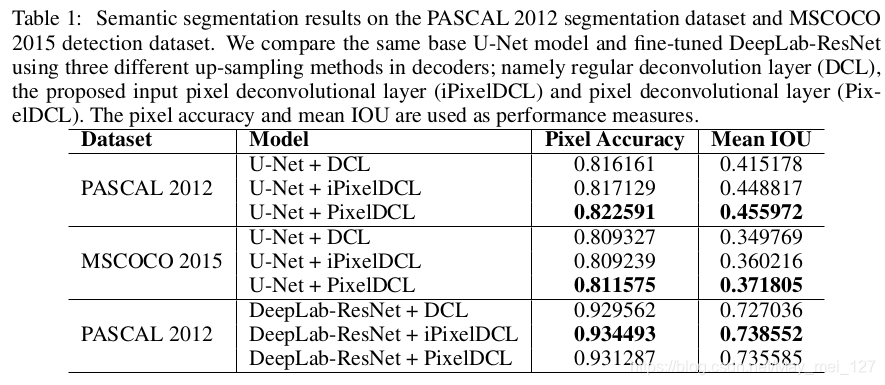
1、语义分割的实验结果表明,PixelDCL可以考虑诸如边缘和形状之类的空间特征,并且比反卷积层产生更准确与平滑的分割输出。
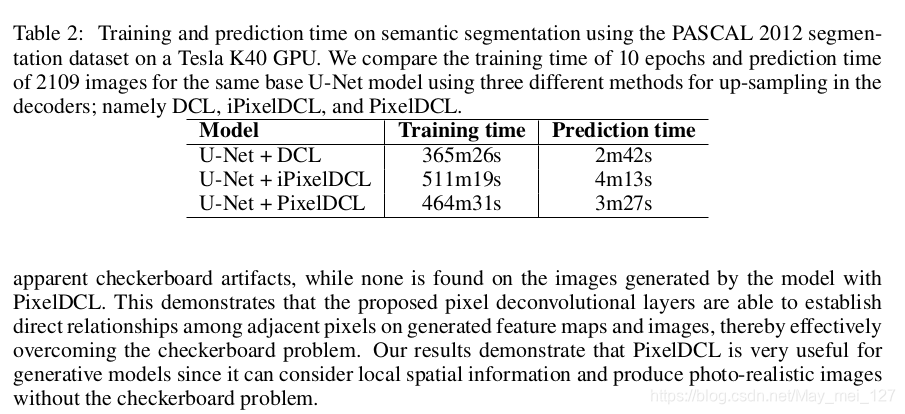
2、用于图像生成任务时,PixelDCL可以大大克服常规反卷积操作所遇到的棋盘问题。
Deconvolutional Layers常见操作
一维反卷积操作
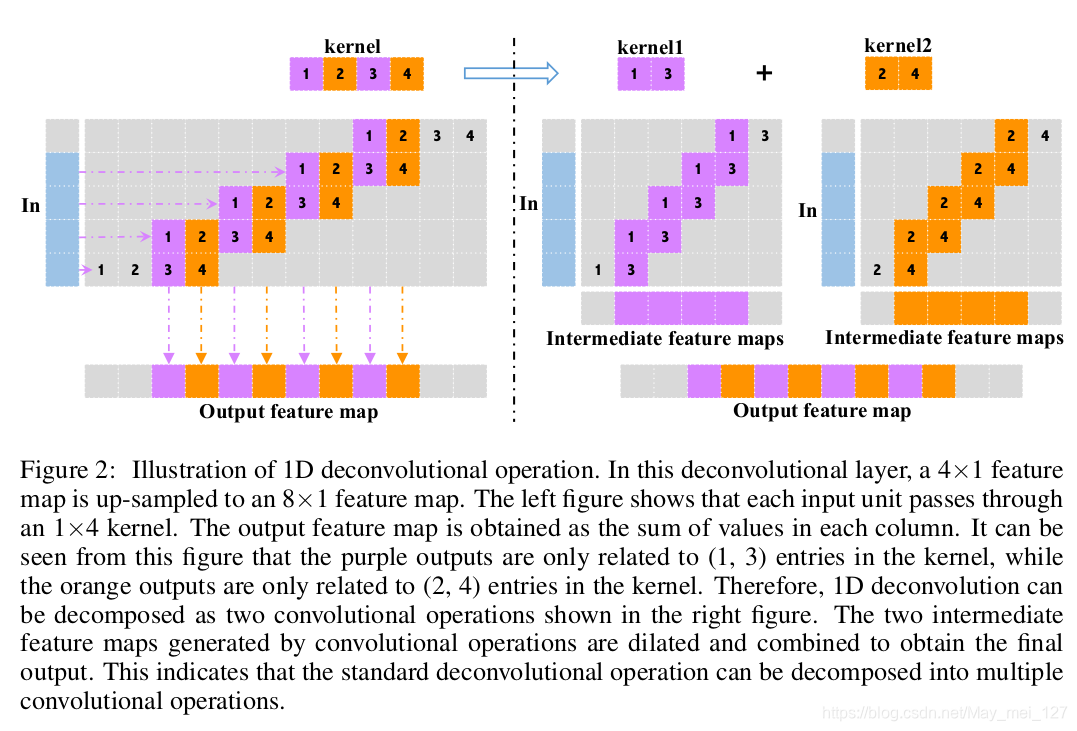
二维反卷积操作
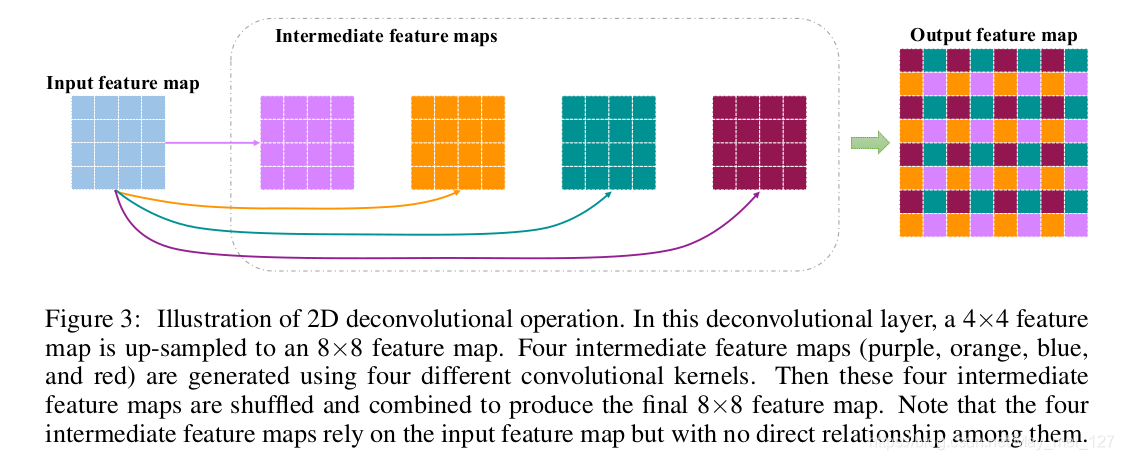

常见一维与二维反卷积操作,其中间特征图只依赖于输入特征图,但他们之间没有直接关系
PixelDCL与iPixelDCL
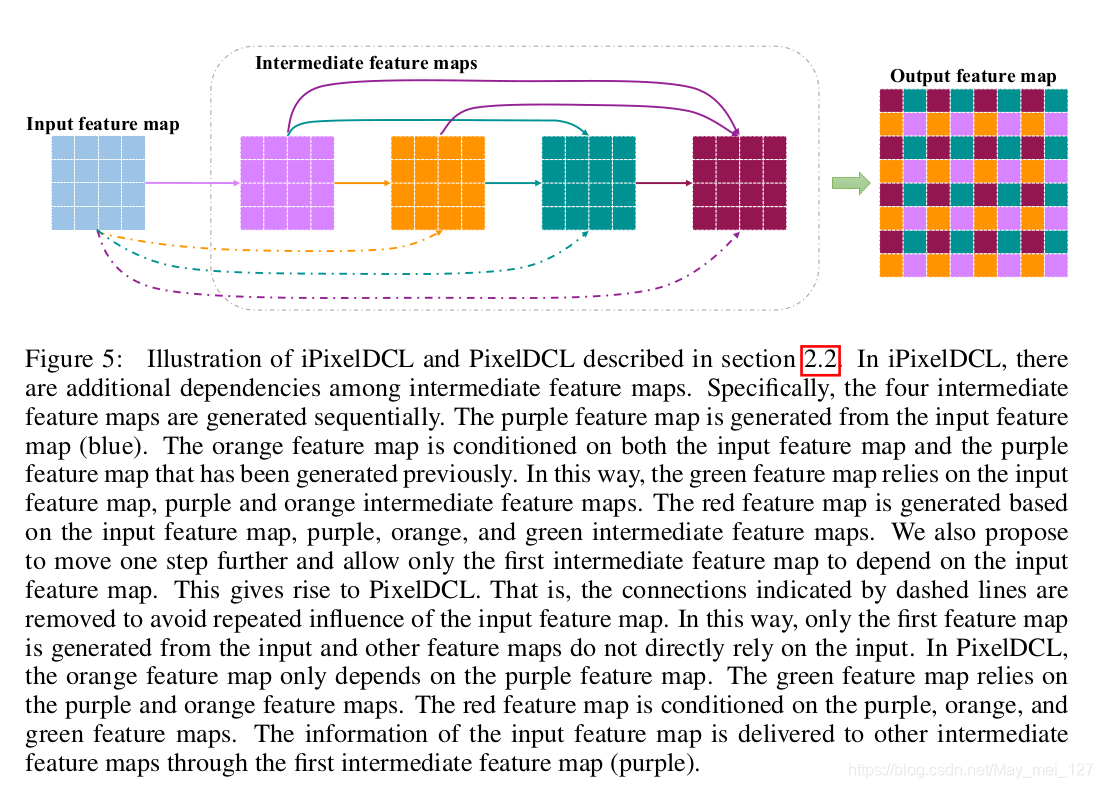

iPixelDCL:实现+虚线部分
PixelDCL: 实线部分
效果:减少对输入特征图的依赖,以更高的计算效率解决棋盘问题
像素反卷积层的有效实现
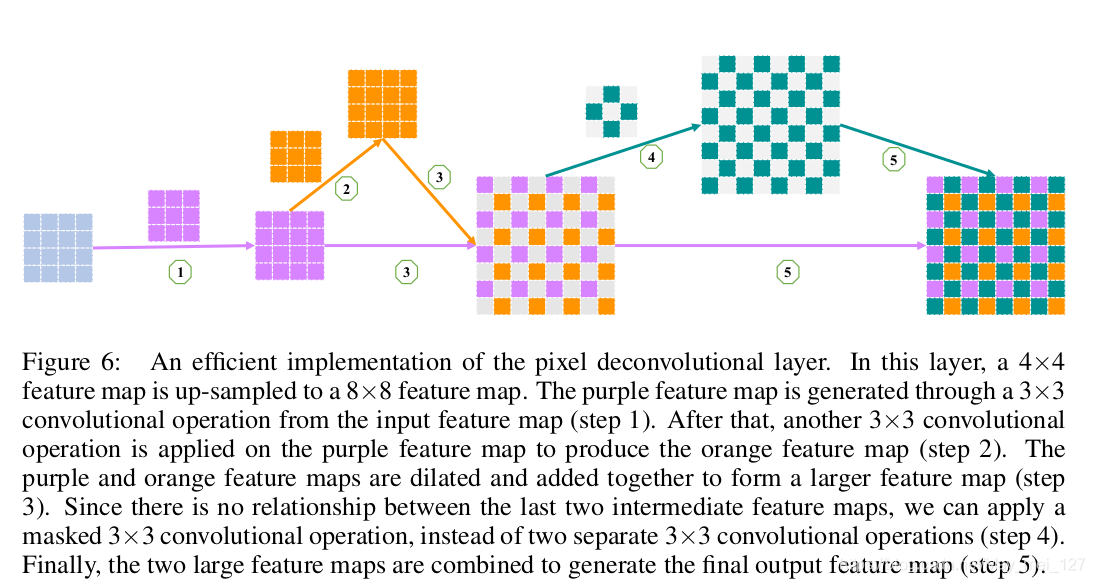
在实现pixel deconvolutional layers,设计了一个简化版本以减少顺序依赖性,从而实现更好的并行计算和训练效率,如图6所示。第三和第四中间特征图基于第一第二特征图,第三和第四特征图没有依赖关系,于是选择使用masked 3×3 convolutional对其进行操作。
实验结果
语义分割
数据集:PASCAL 2012、MSCOCO 2015,图像尺寸:256×256×3
实验方法
1、从头开始训练:利用U-Net架构作为基础模型
网络由编码器的四个块和解码器的四个相应块组成。 在每个解码器块内,有一个反卷积层,后面是两个卷积层。 根据数据集中的类数调整最终输出层。 PASCAL 2012细分数据集具有21个类别,而MSCOCO 2015检测数据集具有81个类别。由于MSCOCO 2015检测数据集比PASCAL 2012细分数据集具有更多的类,因此该数据集每层中的特征图数量增加了一倍,以容纳更多的输出通道。 利用像素反卷积层(iPixelDCL)及其简化版本(PixelDCL)替换了反卷积层,同时保持所有其他变量不变。 DCL中的kernals为6×6,与具有4组3×3kernals的iPixelDCL具有相同数量的参数,并且比具有2组3×3和1组2×2kernals的PixelDCL具有更多的参数。 这将够在控制所有其他因素的同时,针对常规反卷积层评估新的像素反卷积层。
2、微调实验:DeepLabResNet的架构微调模型
在高度和宽度尺寸上,DeepLab-ResNet的输出比输入图像小八倍。 为了恢复原始尺寸,添加了三个上采样块,每个上采样块将特征图上采样率提高了2倍。对于每个上采样块,都有一个反卷积层,然后是一个卷积层。 通过采用相同的策略,使用与从头开始的实验中训练的大小相同的内核,用PixelDCL和iPixelDCL替换反卷积层。
实验结果:


图像生成
数据集:CelebA,图像尺寸:64×64×3
生成模型:variational auto-encoder (VAE)
实验方法:用PixelDCL替代VAE中的解码器部分的反卷积层
DCL中的kernal大小为6×6,与PixelDCL相比,其参数更多,而PixelDCL具有2组3×3和1组2×2kernal。
