《DSSD : Deconvolutional Single Shot Detector》
(一)论文地址:
《DSSD : Deconvolutional Single Shot Detector》
Ps:这篇文章的第二作者就是大名鼎鼎的 大神,也是DSSD的基础《SSD: Single Shot MultiBox Detector》这篇文章的一作;
(二)解决的问题:
SSD的详解可以看我的这两篇博客:
SSD目标检测算法详解 (一)论文讲解
SSD目标检测算法详解 (二)代码详解
相比于faster-rcnn在同一个特征图上采用不同大小的先验框进行目标的提取的方法,SSD算法采取:提取了不同尺度的特征图来做检测,大尺度特征图(浅层的特征图)可以用来检测小物体,而小尺度特征图(深层的的特征图)用来检测大物体;
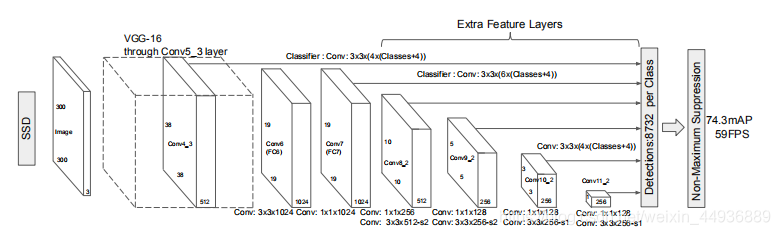
但由于浅层的特征图对于图像特征的提取并不完全,所以SSD算法对小目标的检测依然存在不足;
为了提高小目标检测的精度,作者提出了DSSD,即反卷积SSD;
(三)DSSD 的核心思想:
为了提高对小目标的检测精度,作者提出了:
- 使用 代替 提取特征;
- 使用反卷积层增加上下文(context)的信息;
- 使用迁移学习(特别是在反卷积层)效果会更好;
从而大大增加了上下文信息,在对检测速度影响较小的同时,大大提升了目标检测的准确度;
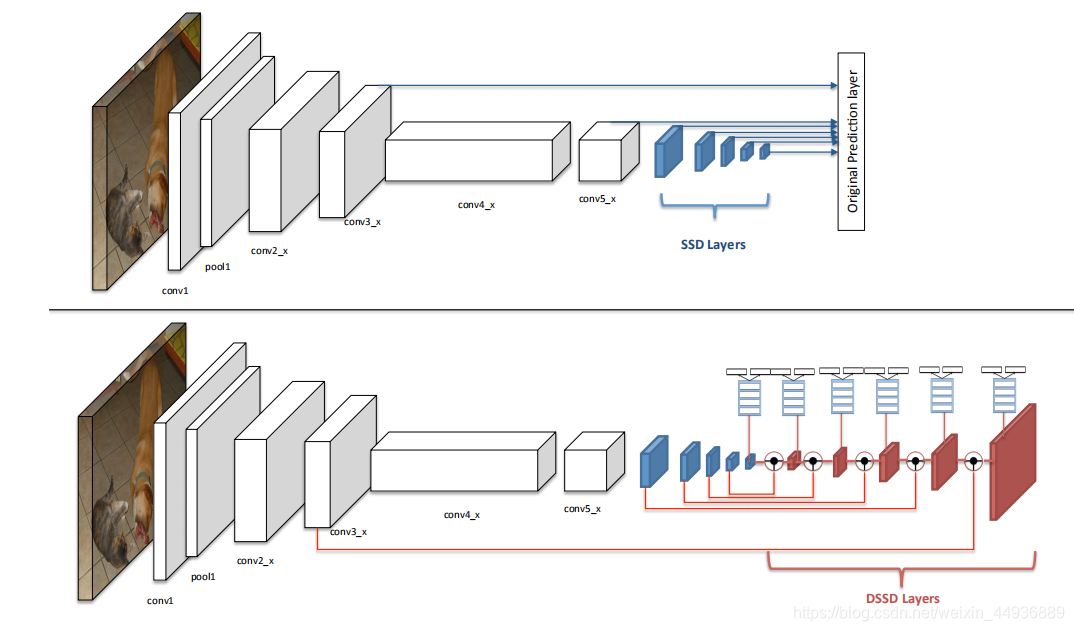
(四)ResNet 的残差单元:
ResNet的核心思想是:
将本来回归的目标函数H(x)转化为F(x)+x,即F(x) = H(x) - x,称之为残差。
在训练时,我们将该单元目标映射(即要趋近的最优解)假设为F(x) + x,而输出为y+x,那么训练的目标就变成了使y趋近于F(x)。即去掉映射前后相同的主体部分x,从而突出微小的变化(残差),并融合上下文信息;

更具体的理解可以看我这一篇:
残差网络ResNet系列网络结构详解:从ResNet到DenseNet
(五) Prediction Module:
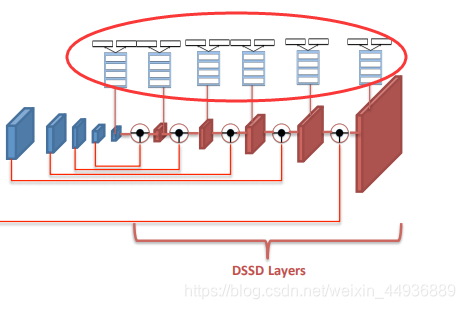
指的是,将特征图输入到卷积层,输出每个特征点对应多个default box的类别向量和回归坐标;
的几种变体如图所示:
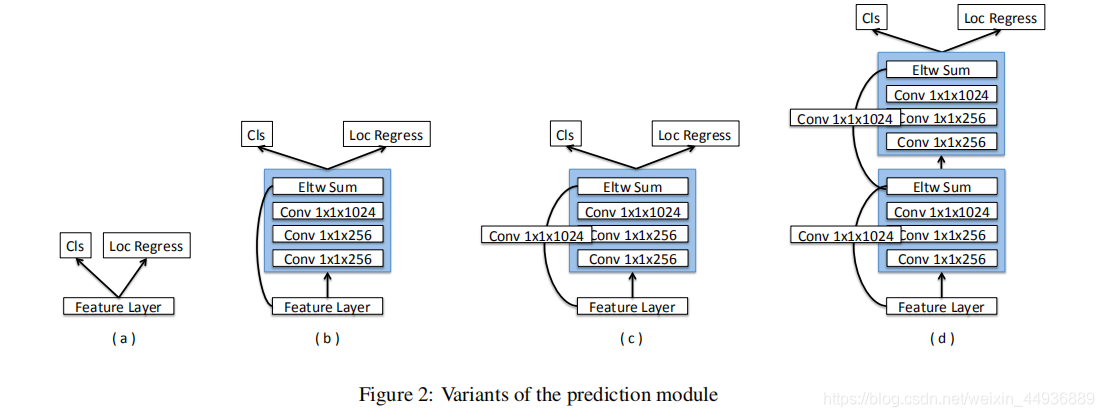
其中(a)是SSD采用的
,即使用单层卷积(
卷积核大小)直接输出相应的
(类别向量,包括背景分类)和
(回归坐标),实现代码如下:
def ssd_multibox_layer(self, inputs, class_num, ratio, size):
num_anchors = len(size) + len(ratio)
num_loc = num_anchors * 4
num_cls = num_anchors * class_num
# loc
loc_pred = slim.conv2d(
inputs, num_loc, [3, 3], activation_fn=None, scope='conv_loc')
# cls
cls_pred = slim.conv2d(
inputs, num_cls, [3, 3], activation_fn=None, scope='conv_cls')
loc_pred = tf.reshape(loc_pred, (-1, 4))
cls_pred = tf.reshape(cls_pred, (-1, class_num))
# softmax
cls_pred = slim.softmax(cls_pred, scope='softmax')
return loc_pred, cls_pred
变体(b)、(c)和(d)则是DSSD采用的 ,即在输出预测结果前,使用 卷积核大小的卷积层和类似ResNet的残差结构,在不大量增加参数量和不改变感受野大小的前提下,进一步提取特征并融合上下文信息;
(六)Deconvolutional Module:

是DSSD的核心;
深层特征图的感受野比较大,语义信息表征能力强,但是特征图的分辨率低,几何信息的表征能力弱;浅层特征图的感受野比较小,几何细节信息表征能力强,虽然分辨率高,但是语义信息表征能力弱;
为了充分利用深层特征图和浅层特征图的有效信息,作者提出了 ,即在使用浅层特征图(假设为 大小)输入到 之前,先使用反卷积层将下一层较深的特征图( 大小)转换为相同大小( ),将这两个特征图融合,作为 的输入;
作者还提出了 具体结构:

- 每个卷积层之后添加 ;
- 反卷积层参与训练,而非是简单的双线性插值;
- 通过点积融合两个特征图;
(七)Training:
训练方式与SSD相似,即将不同的default box进行分类,分为正样本(物体)和负样本(背景);
通过计算default box和true boxes(真值框)的IOU值,IOU>0.5的标注为正样本,则该default box的标签就是跟这个default box的IOU最大的真值框的标签;IOU<0.5的标注为负样本;
由于我们的分类向量有一个背景得分,故负样本可以参与类别的loss计算,但不参与坐标回归的loss计算;
然后选取所有的正样本,然后按照正、负样本比为 1 :3 的比例选取IOU得分最小的负样本参与Loss计算,其余default box的Loss记为0(其中分类Loss使用交叉熵Loss,坐标回归Loss使用SmoothL1);
另外,作者使用
算法聚类重新指定了几种default box的宽高比:
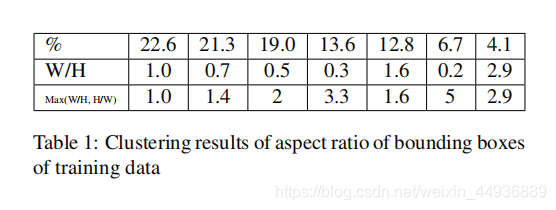
相比于SSD中人工指定的宽高比,显然这里的宽高比更具有代表性;
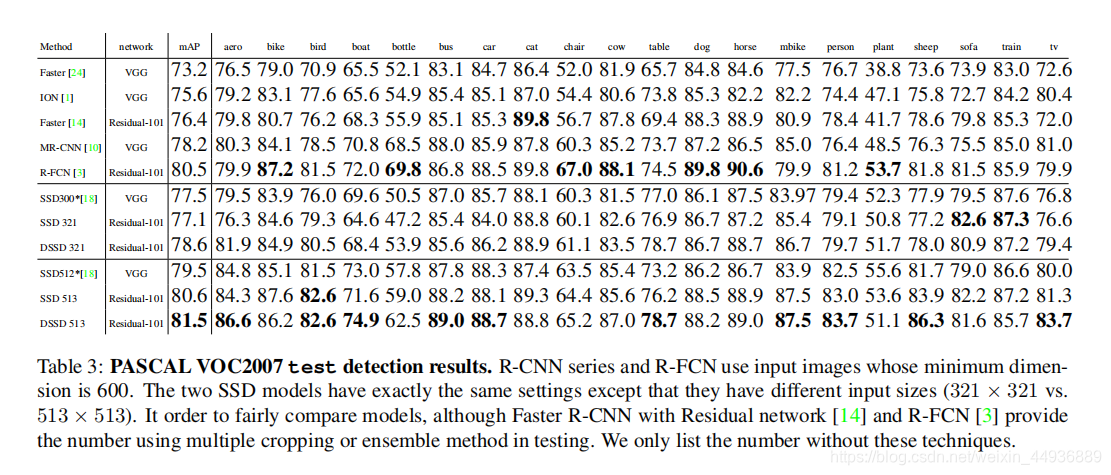
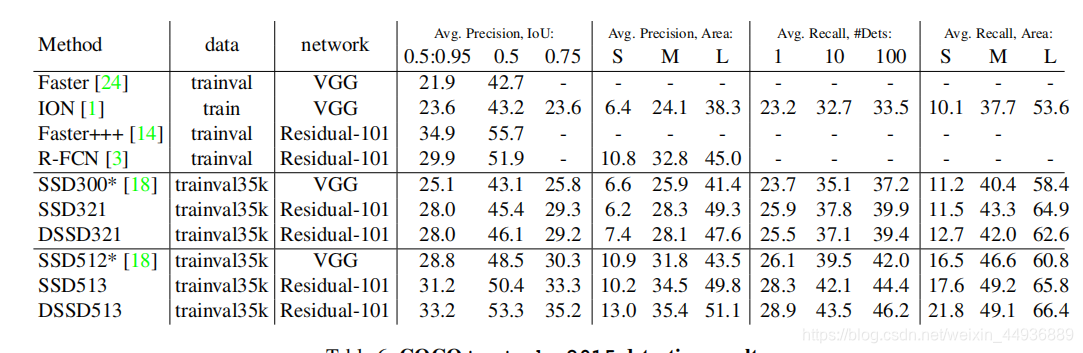
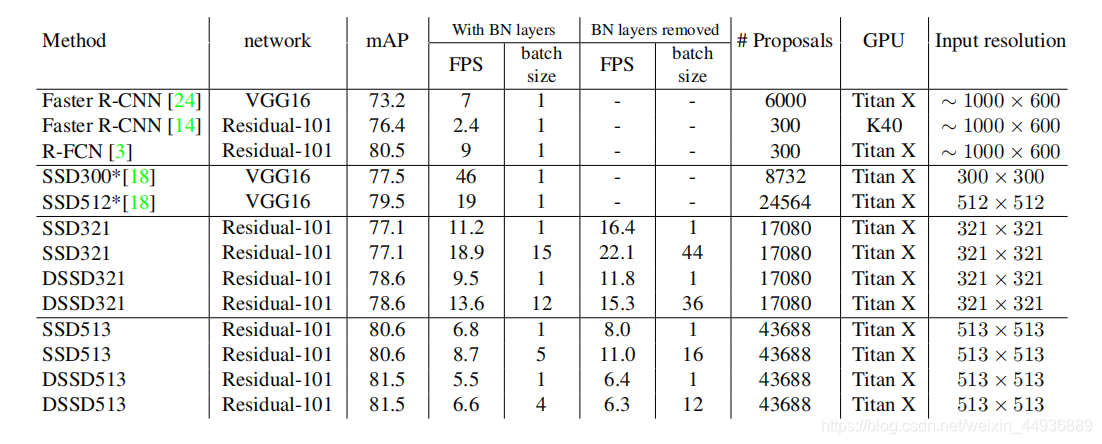
(八)实验结果:
DSSD-513在VOC2007上取得了81.5% mAP,在VOC2012上取得了80.0% mAP,在COCO上取得了33.2% mAP的成绩,均高于R-FCN;FPS为5.5(batch_size=1);