DenseNet是CVPR2018的oral,文章提出的DenseNet是一种密集连接的网络,主要启发来自于之前的ResNet的Inception结构和stochastic depth。残差网络的Inception结构里面,网络的输入来源于上层网络的输出和上层网络的输入,随机深度网络采用了一种类似dropout的策略,只是随机失效的是网络层,而不是每层的某些像素,这样形成了随机深度。DenseNet网络中,每一层的输入来自前面所有层的输出。传统的卷积神经网络中,如果有L层,那么就会有L个连接,但在DenseNet中,会有L(L+1)/2个连接。
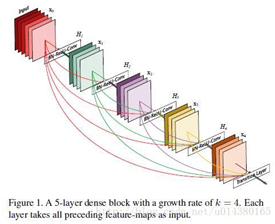
在深度学习网络中,目前都是显著加深了网络深度,但是我们知道,随着网络层数的加深,梯度消失问题会愈加明显,目前很多论文都针对这个问题提出了解决方案,比如ResNet的shortcut结构,Stochastic depth随机深度,FractalNets分形网络结构等,尽管这些算法的网络结构有差别,但是核心都在于通过创建从前面网络层到后面层的捷径。而文章中是在保证网络中层与层之间最大程度的信息传输的前提下,直接将所有层连接起来。
DenseNet的一个优点是网络更窄,参数更少,主要得益于这种dense block的设计(上图),dense block中每个卷积层的输出feature map的数量都很小(小于100),而不是像其他网络一样动不动就几百上千的宽度。同时这种连接方式使得特征和梯度的传递更加有效,网络也就更加容易训练。文中作者提到:Each layer has direct access to the gradients from the loss function and the original input signal, leading to an implicit deep supervision.直接解释了为什么这个网络的效果会很好。前面提到过梯度消失问题在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深的网络都不是问题。另外作者还观察到这种dense connection有正则化的效果,因此对于过拟合有一定的抑制作用。
![]()
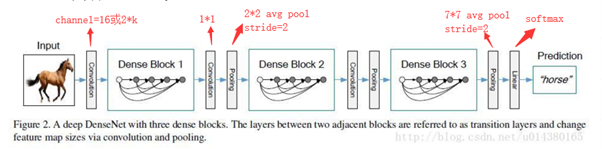
DenseNet的结构如上,每个蓝色方块是一个dense block,整个网络有三个dense block 和两个transition层(convolution + pooling)组成,前面是input+convolution,最后是pooling+softmax层,k是每层的特征图数。
另外作者还设计了DenseNet-B和DenseNet-C, DenseNet-B是在dense block中的卷积层前都加了一个1*1卷积,DenseNet-C是在transition层的添加1*1卷积,特征图的输出改为一半。另外还有ReLU和BN,全局平均池化等设计。
最后作者在cifer和SVHN,ImageNet数据集上都做了实验,同等条件对比其他网络,实验结果显示,densenet基本都有很大的效果提升。
总结:该文章提出的DenseNet核心思想在于建立了不同层之间的连接关系,充分利用了feature,进一步减轻了梯度消失问题,加深网络不是问题,而且训练效果非常好。另外,利用bottleneck layer,Transition layer以及较小的growth rate使得网络变窄,参数减少,有效抑制了过拟合,同时计算量也减少了。
DenseNet优点很多,而且在和ResNet的对比中优势还是非常明显的。主要有:
1、减轻了vanishing-gradient(梯度消失)
2、加强了feature的传递 ,更有效地利用了feature
3、一定程度上减少了参数数量,减少计算量,更容易训练