论文地址:Wide Residual Networks
笔记地址:http://blog.csdn.net/wspba/article/details/72229177
转载请标明出处,理解不到位的地方也希望大家批评指正,谢谢!
前言
俗话说,高白瘦才是唯一的出路。但在深度学习界貌似并不是这样。Wide Residual Networks就要证明自己,矮胖的神经网络也是潜力股。其实从名字中就可以看出来,Wide Residual Networks(WRNS)源自于Residual Networks,也就是大名鼎鼎的ResNet,之前我们也介绍了,ResNet就是解决随着深度增加所带来的退化问题,它可以将网络深度提升到千层的级别,本身就是以高和瘦出名,可以说是深度学习界的高富帅。然而这一次,大神们剑走偏锋,摒弃了ResNet高瘦的风格,开始在宽度上打起来了注意,而Wide Residual Networks也确实扬眉吐气,从此名声大噪。
动机
作者认为,随着模型深度的加深,梯度反向传播时,并不能保证能够流经每一个残差模块(residual block)的weights,以至于它很难学到东西,因此在整个训练过程中,只有很少的几个残差模块能够学到有用的表达,而绝大多数的残差模块起到的作用并不大。因此作者希望使用一种较浅的,但是宽度更宽的模型,来更加有效的提升模型的性能。
模型结构
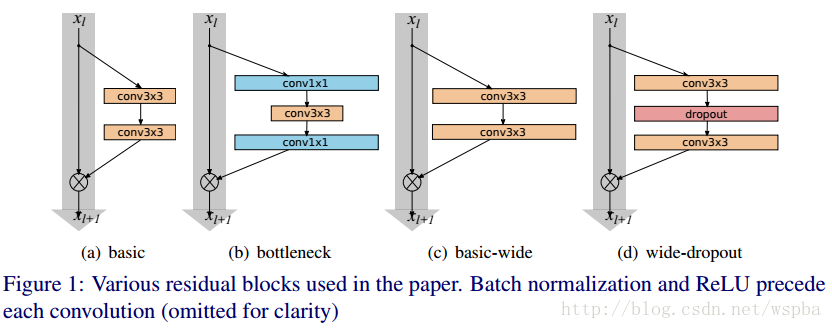
看图,其实很容易理解,(a)和(b)是MSRA提出来的ResNet,一种基本结构,一种bottleneck结构;(c)和(d)就是作者提出来的wide结构。看不出什么来是不是,那下面这个表格就能让你一目了然:
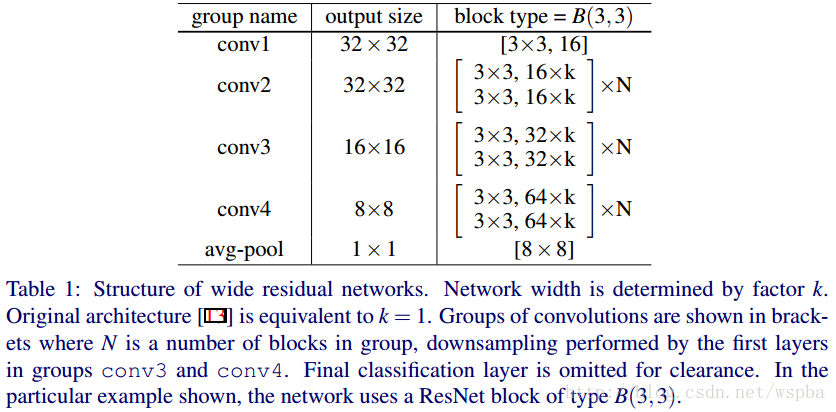
有点眼熟是不是,把表格中的k变为1,是不是就是ResNet论文中,cifar-10实验所使用的网络?还记得吗,ResNet原文中,作者针对cifar-10所使用的的网络,包含三种Residual Block,output channel分别是16、32、64,网络的深度为6*N+2。而在这里,作者给16、32、64之后都加了一个系数k,也就是说,作者是通过增加output channel的数量来使模型变得更wider,从而N可以保持很小的值,就可以是网络达到很好的效果。
当然他确实做到了。
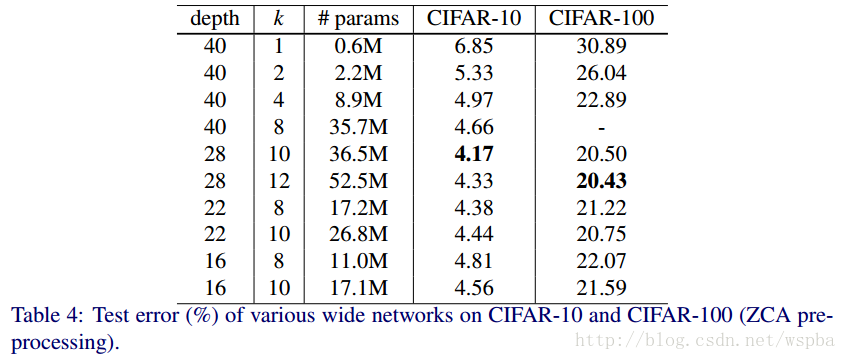
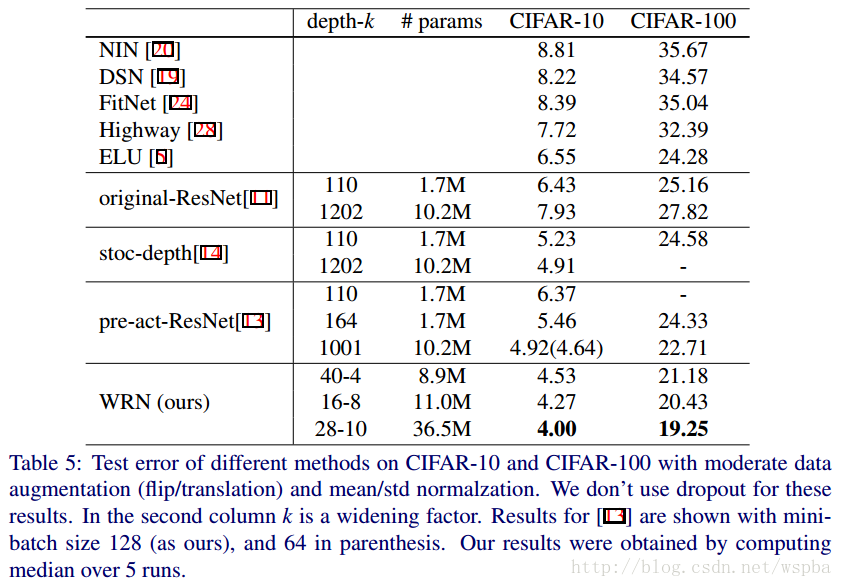
上面结果也确实证明了,增加模型的宽度是对模型的性能是有提升的。不过也不能完全的就认为宽度比深度更好,两者只有相互搭配,达到合适的值,才能取得更好的效果。
后话
其实这篇论文是相对比较简单的,他验证了宽度给模型性能带来的提升,也给大家以后在模型性能遇到瓶颈时提供了一种思路,比如说我在做cifar-10分类任务时,仅仅是将ResNet-20的宽度由16、32、64变为32、64、128,就将分类的性能由92%提升到94%以上,在caffe下,它的caffemodel大小也就10兆出头,和ResNet-56的大小近似,显存占用率也不大,训练速度很快。当然作者文中的WRNS-28-10确实是变态极致的结构了,性能确实好,在我的训练框架下,cifar-10的分类准确率能够逼近97%,但是caffemodel的大小有150M左右,训练的也是非常慢,没记错的话显存应该占用18G左右。所以如果你想在保证在一定准确率的基础上,使得模型复杂度降低,可以从更浅、更加复杂的模型入手。另外我觉得本文还可以尝试的东西可以从文中的另外一个表格入手:
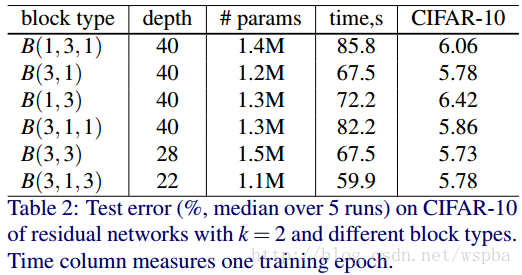
我们可以发现,其实B(3,1,3)在深度最浅、参数量最小、训练时间最短的前提下,在cifar-10的分类错误率上也几乎达到了最好的水平。由于原文中作者只研究了宽度对模型的影响, 因此并没有对这部分内容进行解释。因此这个也是一个可尝试的方向。
另外对于drop-out,其实在WRNS-16-4上,也能够带来性能的提升。虽然dropout是旧办法,但是依然也是好办法,大家大胆去尝试就对了。