论文地址:DSSD : Deconvolutional Single Shot Detector
项目地址:Github
概述
这篇论文应该算是SSD: Single Shot MultiBox Detector的第一个改进分支,作者是Cheng-Yang Fu, 我们熟知的Wei Liu大神在这里面是第二作者,说明是一个团队的成果,论文很新,暂未发布源代码。博主对该文章重要部分做了翻译理解工作,不一定完全对,欢迎讨论。
在SSD的研究基础上,本文的主要贡献可分为两点:首先,把SSD的基准网络从VGG换成了Resnet-101,增强了特征提取能力;然后使用反卷积层(deconvolution layer )增加了大量上下文信息。最终提升了目标检测精度,尤其是小物体的检测精度。DSSD以513 * 513的图片输入,在VOC2007上的mAP是81.5%,而SSD为80.6%,在COCO数据集上mAP也达到了33.2%,贴一张成绩对比图。

简介
本文的主要贡献前面已述,这里作者强调论文思想实施起来并不太容易,重点是反卷积中前馈连接的模块和新输出的模块,作者的深入研究使得这一方法具有了很大的潜力。
文章简要回顾了目标检测的发展历程,提到在基于现有深度学习方法的基础上,还要提升检测精度的话,其中两个途径就是更好的特征提取网络和增加上下文信息,尤其对小物体检测而言更是如此。SSD方法用的基准网络是VGGNet,要是换成Resnet-101的话就能提升精度,这就更好的特征提取网络。在目标检测研究之外,有一种编码-解码(encoder-decoder )网络,其中网络中间层加入了输入图像的编码部分,后面再进行解码(就是卷积和反卷积),这样形成的宽-窄-宽的网络结构很像沙漏,FCN就是类似结构,本文就利用反卷积层实现了上下文信息的扩充。
DSSD模型
SSD框架
DSSD的基础是SSD检测网络,推荐阅读博客:论文阅读:SSD: Single Shot MultiBox Detector 写的非常通俗详细。
使用Resnet-101替换VGG
作者对SSD的第一项改进就是换网络,把VGG换成Resnet-101(Figure 1上半部分)。这里,作者在conv5-x区块后面增加了一些层(SSD Layers),然后会在conv3-x,conv5-x以及SSD Layers预测分类概率和边框偏移。如果仅仅是换网络的话,mAP居然还下降了一个百分点,只有增加上下文信息,精度才会有较大提升。

Figure 1基本上展示了论文的核心思想,也就是如何利用中间层的上下文信息。方法就是把红色层做反卷积操作,使其和上一级蓝色层尺度相同,再把二者融合在一起,得到的新的红色层用来做预测。如此反复,仍然形成多尺度检测框架。在图中越往后的红色层分辨率越高,而且包含的上下文信息越丰富,综合在一起,使得检测精度得以提升。
预测模块
SSD的直接从数个卷积层中分别引出预测函数,预测量多达7000多,梯度计算量也很大。MS-CNN方法指出,改进每个任务的子网可以提高准确性。根据这一思想,作者在每一个预测层后增加残差模块,并且对于多种方案进行了对比,如下图所示。结果表明,增加残差预测模块后,高分辨率图片的检测精度比原始SSD提升明显。
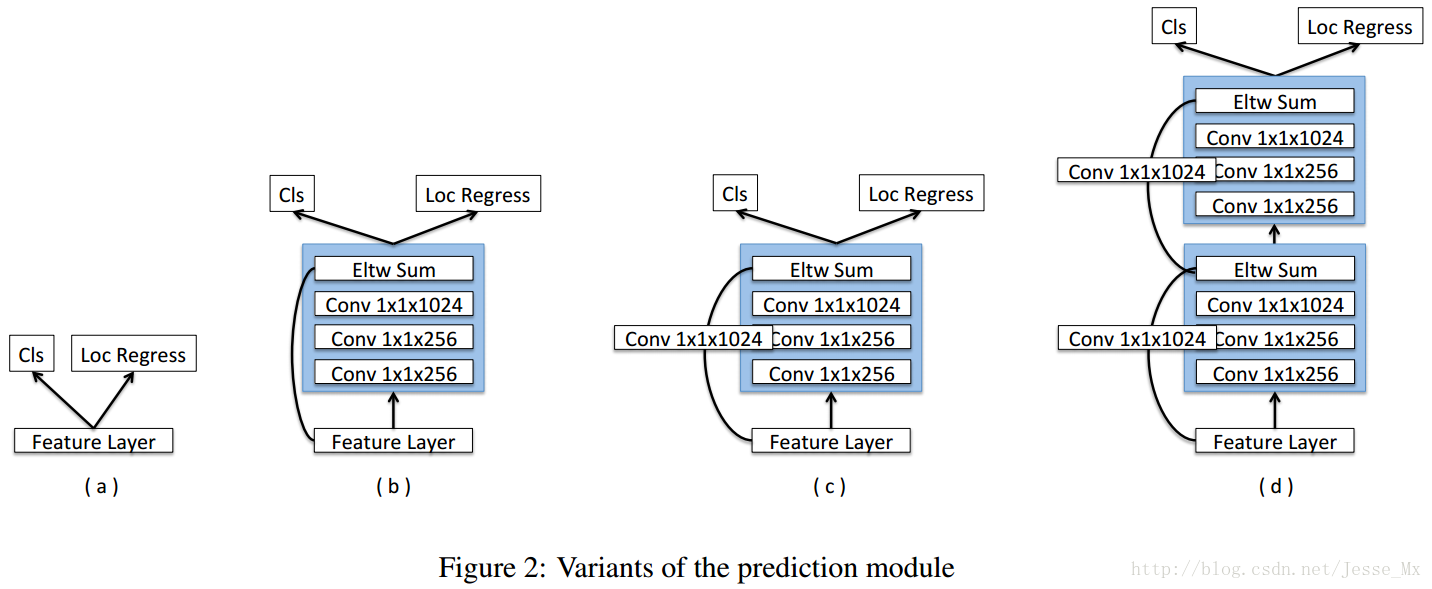
反卷积SSD网络
为了引入更多的高级上下文信息,作者在SSD+Resnet-101之上,采用反卷积层来进行预测,和原始SSD是不同的,最终形成沙漏形的网络。添加额外的反卷积层以连续增加后面特征图的分辨率,为了加强特征,作者在沙漏形网络中采用了跳步连接(skip connection)方法。按理说,模型在编码和解码阶段应该包含对称的层,但由于两个原因,作者使解码(反卷积)的层比较浅:其一,检测只算是基础目标,还有很多后续任务,因此必须考虑速度,做成对称的那速度就快不起来。其二,目前并没有现成的包含解码(反卷积)的预训练模型,意味着模型必须从零开始学习这一部分,做成对称的则计算成本就太高了。
反卷积模块
为了整合浅层特征图和反卷积层的信息,作者引入了如figure 3所示的反卷积模块,该模块可以适合整个DSSD架构(figure1 底部实心圆圈)。作者受到论文Learning to Refine Object Segments的启发,认为用于精细网络的反卷积模块的分解结构达到的精度可以和复杂网络一样,并且更有效率。作者对其进行了一定的修改,如Figure 3所示:其一,在每个卷积层后添加批归一化层;其二,使用基于学习的反卷积层而不是简单地双线性上采样;其三,作者测试了不同的结合方式,元素求和(element-wise sum)与元素点积(element-wise product)方式,实验证明点积计算能得到更好的精度。
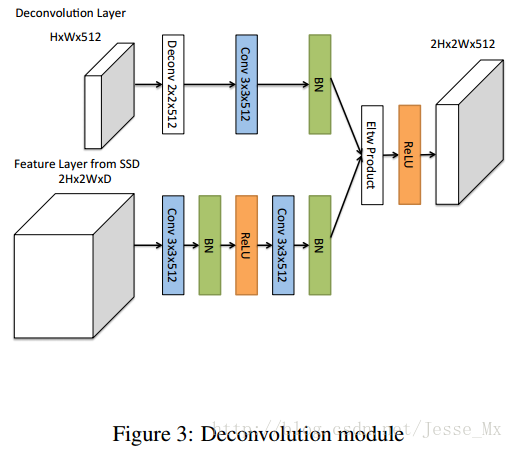
网络训练
训练技巧大部分和原始SSD类似。首先,依然采用了SSD的default boxes,把重叠率高于0.5的视为正样本。再设置一些负样本,使得正负样本的比例为3:1。训练中使Smooth L1+Softmax联合损失函数最小。训练前依然需要数据扩充(包含了hard example mining技巧)。另外原始SSD的default boxes维度是人工指定的,可能不够高效,为此,作者在这里采用K-means聚类方法重新得到了7种default boxes维度,得到的这些boxes维度更具代表性(此处和YOLOv2的聚类做法有点类似,可参考博客:YOLOv2 论文笔记)。

实验细节
有点长,看心情再决定写不写。