论文笔记(三)NIPSI:value iteration Networks
arxiv:https://arxiv.org/pdf/1602.02867.pdf
GitHub:https://github.com/onlytailei/Value-Iteration-Networks-PyTorch
首先,安利一下我最近在准备的会议nips:
NIPS:神经信息处理系统大会(Conference and Workshop on Neural Information Processing Systems),是一个关于机器学习和计算神经科学的国际顶级会议。该会议固定在每年的12月举行,由NIPS基金会主办。在中国计算机学会的国际学术会议排名中,NIPS为人工智能领域的A类会议。
1)本文的目的,通过一个价值迭代神经网络代替人物的损失函数,证明强化学习中我这个策略是有效的,可以用来预测未知的领域。
传统神经网络需要一个人类科学家精心打造的损失函数。但是,对于生成模型这样复杂的过程来说,构建一个好的损失函数绝非易事。这就是对抗网络的闪光之处。对抗网络可以学习自己的损失函数——自己那套复杂的对错规则——无须精心设计和建构一个损失函数.
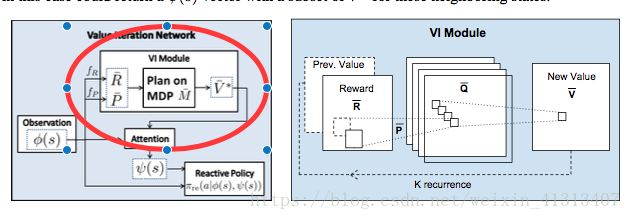
作者引入了两个函数fR和fP 分别用于的参数化 奖励R’和转移概率P’。函数fR为一个奖励函数映射:当输入的状态图,计算出对应的奖励值;例如,在接近于目标附近的状态得到的奖励值就比较高,而接近于障碍物的状态得到的奖励值就越低;fP 是一个状态转移的函数,是在状态下的确定性的转移动作。
这篇文章中起作用的就是我红圈那个模块,用于策略评估的回报函数/价值函数.不再用传统的指数家族函数或者log损失函数去模拟价值函数, 而是在框架中加入一个VI(Value iteration)模块。
抛砖引玉来了
那么我们引入了一个游戏:
给你一张图,让你找到一条起点到终点的最短路径,
那么问题来了,如果我去掉最短路径这个损失函数,那么神经网络会不会自己学会目标是找最短路?
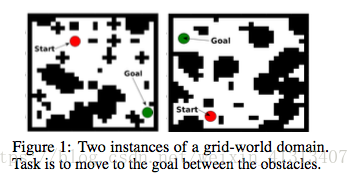
可以看到在没有价值迭代模块的时候效果并不理想。

那么,我们又该如何·通过价值迭代的方法解决这个问题呢?
什么是增强学习中的价值迭代?
首先, 传统增强学习的价值迭代, 是在每次迭代根据已有的一些行为, 状态转移, 以及回报的信息, 更新价值函数:
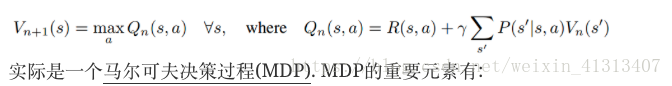
状态S,
行为a,
奖励函数R(S,a)
转移概率P(S’|S,a);
这样我们就可以得到一连串的马尔科夫决策链:
那么我们可以一个价值迭代模块VI
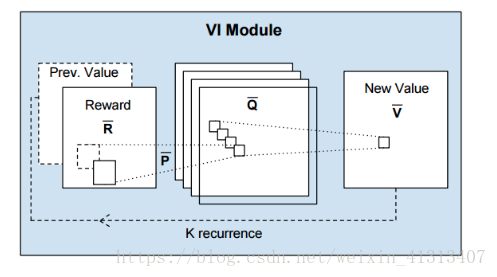
看作CNN神经网络
输入是: 回报R, 转移概率P和上次迭代的价值函数Pre V,
输出是: 价值函数V. 之所以看做CNN, 是针对一些回报R是局部相关的问题.
我们把4个上下左右的通道组成一个新的value,用attention来剪枝,我只关心这四个状态,
基于这样的观察,作者就提出了本文的VI Network,表达式为:
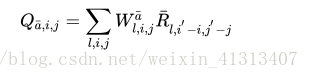
并且在得到的结果当中,对不同通道的Q值进行 max-pooling操作。那我们来理解这个表达式,在表达式当中的l 表示的是各个动作action对应的R层,a其实对应于l; 累加当中的 表示邻近于这个位置的一个区域索引。W 就是网络的参数了,也就是一个卷积核,表示的是可以到周围的几个Q的概率;经过最后的 跨通道的Max-pooling 得到就是一次迭代后的值函数的值。于是这样这个网络具备了值迭代的功能,同时也能够像CNN一样通过BP算法来进行网络的更新。
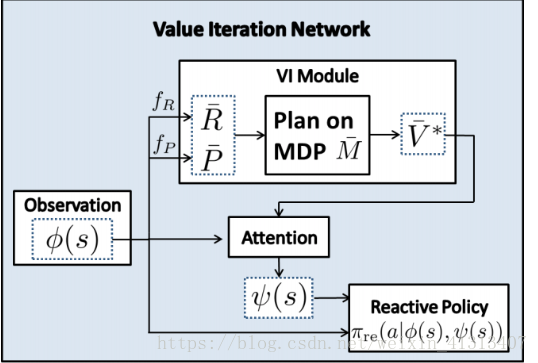
引入了两个函数fR和fP 分别用于的参数化 奖励R’和转移概率P’。函数fR为一个奖励函数映射:当输入的状态图,计算出对应的奖励值;例如,在接近于目标附近的状态得到的奖励值就比较高,而接近于障碍物的状态得到的奖励值就越低;fP 是一个状态转移的函数,是在状态下的确定性的转移动作。
这样以来,我们的状态就大幅减少了,通过学习VI,我们是否可以让VIN变成一个价值函数?
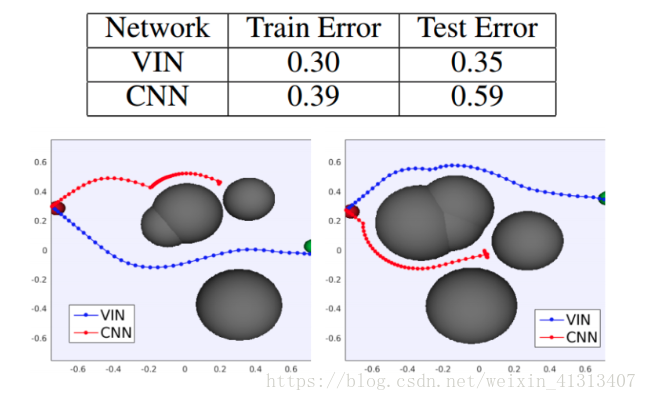
可以看得出效果还是很明显好的。
优点:总结VIN的创新点,我觉得主要是以下的几个点:
将奖励函数和转移函数也参数化,并且能够求导;
引入了一个空间辅助策略的求解,使得policy更具有泛化能力;
在策略的求解当中引入attention机制;
将VI module的设计等价为一个CNN网络,且能够使用BP算法更新网络。