上篇文章《对话AI–问答系统,阅读理解综述第一部分概述》已经介绍了一些基本的概念,下面就第三部分,问答和机器阅读理解展开[参考文献1]。
概要
这里主要介绍两种问答:
- 基于知识库的问答——相比传统的SQL查询语句,基于知识库的问答系统不需要复杂的SQL结构,直接根据Query进行语义解析或者是信息抽取,然后再得到结果。
- 基于文档的问答——不同于传统的搜索引擎给出若干个排列结果,其直接给出精确简明的答案。
基于语义分析的符号主义的方法,将自然语言转为一系列的逻辑表达形式,接着在知识库中进行查询和推理,然后获得答案。其可移植性较差,因为对于大型的知识库,这种基于关键词匹配和query-to-answer的方法效率较低,而且对于计算句子相似性,鲁棒性较差。为了解决这些问题,提出的神经网络的方法,其主要是把query和知识库表达在一个低维连续的向量空间,可以在语义级别进行预测。使用这2个模型Implicit ReasoNet[1] ,M-Walk[2]作为例子阐述实现的细节。也会描述典型的结构和一些基于知识库的对话系统和数据集。
然后介绍基于文档的问答系统,其核心就是MRC ,基于文档对输入产生一个答案。在两个维度上进行描述:
- 对问题和文档的编码方式
- 执行推理,产生答案
3.1知识库
知识库(knowledge base)的问答一般都是基于结构化的知识,像DBpedia,FreeBase还有Yago,在开放域问答上越来越重要。一种常用的方式,就是用三元组来表示知识。其中,s,t表示主体和客体,r表示两者之间的关系。
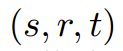
一个知识库也常被称为知识图谱,结点表示实体,边表示关系。

上图是一个知识库的表示和基于语义分析的Q&A的解答过程,下面也将以此为例进行阐述。
3.2 语义分析的KB-QA
很多符号主义的方法都是基于语义分析的方法,将一个问题映射为其逻辑表达(比如一阶谓词逻辑),然后再转换为KB查询。问题的答案就能通过查找一系列和query有关的KB中的路径或者检索这些路径的结点获得。
上图中的左图,就是关于一个TV show-Family Guy的关系子图,有show中的角色,角色的扮演者,扮演的时间等信息。注意Compound Value Type(CVT)是一个复合实体。一种描述两个实体之间的关系的有向图,其中关系作为标签。右图就展示了问题的逻辑表达。首先将query通过语义分析得到表达,然后找到这两个实体,MegGriffin 和 FamilyGuy。其中的y表示,存在一个实体,描述一些关系,比如角色,演员和她开始担任角色的时间(CVT)。我们的答案就是要找到一个这样的x,其中的限制条件就是,最早扮演这个角色。最后根据这个路径,我们就能找到LaceyChabert是正确答案。
那么这种系统是存在两个主要的挑战的:
- 自然语言的相似性:对于相同的问题可能会有很多不同的问法,这可能就会造成问题和label之间的不匹配从而得不到答案。比如在我们的例子中,我们就需要去衡量query-“Who first voiced Meg on Family Guy?”和知识库中-“cast-actor”的匹配程度。匹配程度高,那么我们就能在这条路径上找到答案,如果是因为问题表达方式没有匹配上(相似度很低),那么我们的答案就没有办法找到了。因此,此人[4]提出了一种DSSM的方法,概念上来说它是一种embedding-based 的方法,在3.3中会有介绍。
- 搜索复杂度:找到所有的匹配复杂问题的多步关系是十分昂贵的,因为这些候选路径的数量会随着路径的长度指数增长。
3.3 embedding-based 方法
embedding-based的方法把KB中的实体-关系映射到一个连续的neural空间,相同的语义表达能够映射到相同的连续向量。很多KB-embedding的模型都是为了Knowledge Base Completion Task,预测一个未出现在KB中的三元组,实体是否具有关系r。这种任务比KB-QA更简单,因为它不需要搜索。
bilinear model[5]就是一种这样的方法,它为每一个实体entity学习一个向量x,为每一个关系relation学习一个矩阵W,通过打分,评估三元组的可能性: 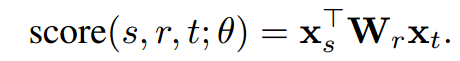
训练方法如下,具体可以参看文章[1]:
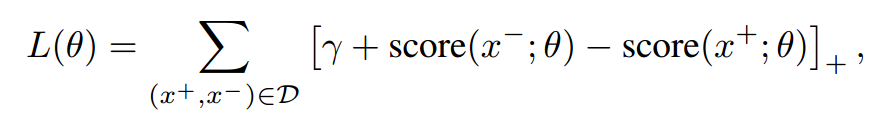
上述基本的bilinear model可以扩展到多步关系查询。比如说,“Where did Tad Lincoln’s parents live?”,s (TadLincoln)会有一系列的关系 (r1; ····; rk)比如说(parents, location),我们可以通过向量空间组合,将个体关系ri嵌入到(r1; ····; rk)。因此,我们可以计算下式的得分,来衡量匹配程度,其中q = (s; r1; ····; rk),
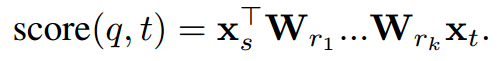
这样我们就不需要通过语义分析,而是直接在向量空间进行计算打分。这种方法在unseen的验证集上有很好的泛化性。感兴趣的读者可以参考文章[6].
3.4 [多步关系1]
Knowledge Base Reasoning(KBR)是KB-QA的一个子任务。
3.6 机器阅读理解(MRC)
MRC是一个具有挑战性的任务:目标就是通过机器阅读一系列的文档,然后问答和文档有关的任何问题。
MRC的进展很大程度上取决于大量可用的数据集,像维基百科,SQuAD以及MCTest等等。其根据答案类型可以分为三种:
- 完型填空式
- 选项给定式
- 自由回答式

上图是两个MRC的数据集,左图式SQuAD数据集。是一种自由回答式的MRC。给定一个问题和一个文档,要求找到文章答案范围。比如问题“what causes precipitation to fall?”,,首先定位到相关部分,“precipitation … falls under gravity”,然后under涉及到原因,而不是位置信息,因此选择正确答案,gravity。
右图是由微软发布的数据集MS MARCO,它相比较SQuAD更具有挑战性,它是从大量的网页问题上进行采样得到的,答案是产生式的,不一定能够在文章中找到,更加符合现实数据。如图中的例子,I am new要能够推理出来和 citizen, permanent resident是相反的意思。
3.7 神经MRC模型
这部分主要以SQuAD数据集为例,给定Q和P,需要在P中定位答案A(start, end).
尽管提出了很多神经网和注意力机制,但是MRC不外乎以下三步:
- 把问题的符号表达和passage 进行编码
- 在向量空间中进行推理,找到答案向量
- 解码答案向量,得到自然语言输出(把答案向量映射到text span)
下图所示两个模型:

左图是The Stochastic Answer Net(SAN) model[7],在2017年12月的时候占领了SQuAD1.1排行榜;右图是The BiDirectional Attention Flow (BiDAF) model.[8]其作为一个广泛使用的基准模型。
3.7.1 Encoder
大部分Model都是通过三层,Embedding、Contextual、Attention,得到文档和query的表达。
Embedding Layer
通常通过W2V或者Glove获得初始化的词向量,以便在连续低维空间捕获语义信息。但是最近提出的Bert,在NLP十一项任务上有很大提升,所以可以考虑使用Bert词向量。另外还可以加上字符级别(英文)、词性标注以及命名实体信息来增加词向量的表达。给定Query和Passage,可以得到 的表达, , 的表达 ,其中I和J分别表示Q和P的词的个数,d表示词向量的维度。
Contextual Embedding Layer
使用词的上下文去定义词向量,对上述的词向量进行微调,举个例子,“
” 和 “
”通过上下文,就知道bank表示的是河岸还是银行了。使用双向LSTM捕获上下文信息,得到
的上下文表达
和
的上下文表达
.
ELMo是2018提出的一个新的model,它是使用深度的Bi-LSTM,每一层的权重是根据特定任务获得的,然后再加权得到Contextual Embedding。
RNN难以平行计算,[9]此人提出使用CNN和self-Attention的方式。使得训练速度大大提高。
Attention Layer
在query的背景下,对文档的每一个词计算Attention,并且产生一个working memory,在其上进行推理。Attention的计算如下:
,
属于
,
属于
其中的sim函数可以是bilinear模型。计算完得分之后通过一个softmax层得到attention值。然后再通过attention和我
做一个加权求和,得到文档的表示
后面还有未更新的,上周刚考完试,这段时间应该就会继续更新了,谢谢大家!
Reference
[1][2018]Neural Approaches to Conversational AI
[2]Shen, Y., Huang, P.-S., Chang, M.-W., and Gao, J. (2017a). Traversing knowledge graph in vector space without symbolic space guidance. arXiv preprint arXiv:1611.04642
[3]Shen, Y., Chen, J., Huang, P., Guo, Y., and Gao, J. (2018). M-walk: Learning to walk in graph with monte carlo tree search. CoRR, abs/1802.04394.
[4]Yih, S. W.-t., Chang, M.-W., He, X., and Gao, J. (2015a). Semantic parsing via staged query graph generation: Question answering with knowledge base. In ACL.
[5]Yang, B., Yih, W.-t., He, X., Gao, J., and Deng, L. (2015). Embedding entities and relations for learning and inference in knowledge bases. ICLR.
[6]Nguyen, D. Q. (2017). An overview of embedding models of entities and relationships for knowledge base completion. arXiv preprint arXiv:1703.08098.
[7]Liu, X., Shen, Y., Duh, K., and Gao, J. (2018c). Stochastic answer networks for machine reading comprehension. In ACL.
[8]Seo, M., Kembhavi, A., Farhadi, A., and Hajishirzi, H. (2016). Bidirectional attention flow for machine comprehension. arXiv preprint arXiv:1611.01603.
[9]Yu, A. W., Dohan, D., Luong, M.-T., Zhao, R., Chen, K., Norouzi, M., and Le, Q. V. (2018). QANet: Combining local convolution with global self-attention for reading comprehension. arXiv preprint