贴一下汇总贴:论文阅读记录
论文链接:《Revisiting Spatial-Temporal Similarity:A Deep Learning Framework for Traffic Prediction》
一、摘要
由于大规模交通数据的可获得性及其在现实世界中的重要性,交通预测在人工智能研究领域受到越来越多的关注。例如,准确的出租车需求预测可以帮助出租车公司预分配出租车。交通预测的关键挑战在于如何对复杂的空间依赖性和时间动态进行建模。尽管在建模中考虑了这两个因素,但已有的研究对空间依赖和时间动态做出了强有力的假设,即空间依赖在时间上是平稳的,而时间动态是严格周期性的。然而,在实践中,空间的依赖可能是动态的(即随时间而变化),时间的动态可能在一个周期到另一个周期之间有一些扰动。本文给出了两个重要的观察结果:(1)位置间的空间依赖是动态的;(2)时间依赖遵循日依赖和周依赖的模式,而不是严格的周期性的动态变化。为了解决这两个问题,我们提出了一种新的时空动态网络(STDN),其中引入了流量门控机制来学习位置之间的动态相似性,并设计了周期性转移的注意机制来处理长期的周期性时间转移。据我们所知,这是第一个在统一框架下解决这两个问题的工作。我们在真实交通数据集上的实验结果验证了所提方法的有效性。
文章主要内容
提出了一种新的时空动态网络(STDN),其中引入了一种门控机制来学习位置之间的动态相似性,并设计了一种周期性注意力转移机制来处理长期的周期性时间转移。
二、结论
提出了一种新的用于流量预测的时空动态网络(STDN)。该方法通过流量门控机制来跟踪区域间的动态空间相似性,通过周期性转移注意机制来跟踪时间周期相似性。对两个大规模数据集的评价表明,所提出的模型优于目前最先进的方法。
可能的方向:
- 在其他时空预测问题上研究所提出的模型;
- 解释这个对决策者来说很重要的模型。
三、相关背景
在基于深度学习的交通预测中,虽然考虑了时空依赖性,但现有的方法存在两大局限性。
- 首先,地点之间的空间依赖仅仅依赖于历史交通流的相似性,模型学习的是静态空间依赖关系。然而,位置之间的依赖关系可能会随着时间而改变,例如,早晨,住宅区和商业中心之间的依赖性很强;而在深夜,这两个地方的关系可能很弱。然而,既有研究并没有考虑到这种动态依赖关系。
- 其次,许多现有的研究忽略了长期周期性依赖的转变。交通数据表现出较强的日、周两种周期性模式。然而,交通数据并不是严格的周期性的。例如,工作日的高峰时间通常发生在下午晚些时候,但不同工作日可以从下午4:30到6:00之间变化。既有研究虽然考虑了周期性,但没有考虑周期性的时间转移。
本文提出的STDN是基于时空神经网络,分别通过局部CNN和LSTM处理时空信息。提出了一种基于门控的局部CNN,利用交通流信息对不同位置之间的动态相似性进行建模,从而处理空间依赖关系。提出了一种周期性注意机转移制来学习长期周期依赖关系,通过注意力机制捕捉交通序列的长期周期性信息和周期性时间转移信息。此外,使用LSTM来处理时间依赖关系。模型使用的数据集是纽约的出租车和共享单车数据集。
四、STDN时空动态网络
该网络分为三部分:
- (1) Local Spatial-Temporal Network, 局部时空网络;
- (2) Spatial Dynamic Similarity: Flow Gating Mechanism, 门控机制;
- (3) Temporal Dynamic Similarity: Periodically Shifted Attention Mechanism,周期性注意力转移机制。
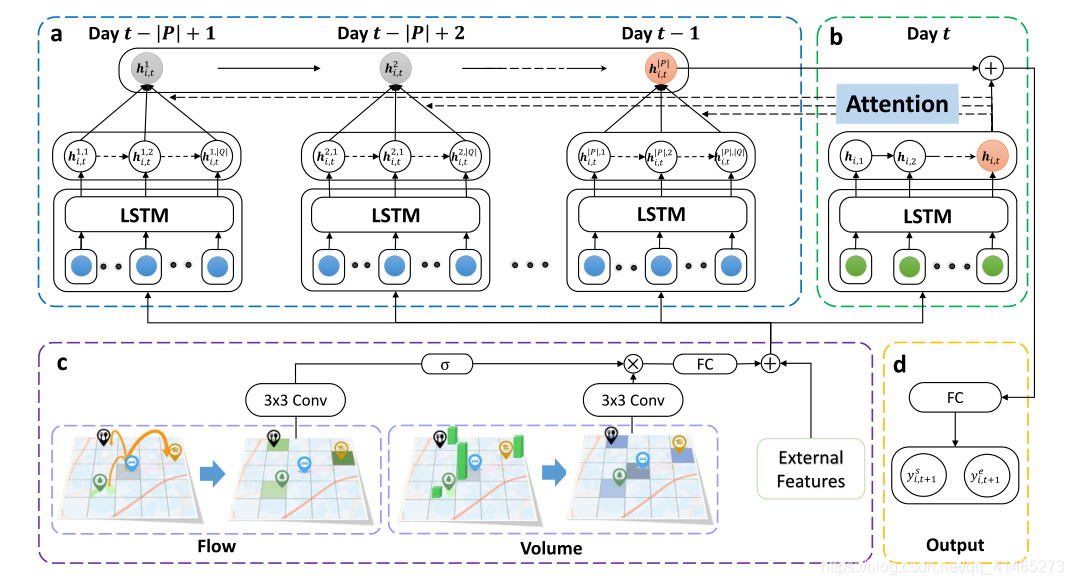
(一)局部时空网络
使用CNN处理局部空间依赖,对于每个时间间隔 t t t,我们将目标区域 i i i及其周围的邻域作为一个具有两个通道的 S × S S×S S×S图像, Y i , t ∈ R S × S × 2 Y_{i,t}\in\R^{S×S×2} Yi,t∈RS×S×2。一个通道包含客流产生量信息,另一个通道包含客流吸引量信息,目标区域在图像的中心。卷积公式: Y i , t ( k ) = R e L U ( W ( k ) ∗ Y i , t ( k − 1 ) + b ( k ) ) ( 1 ) Y_{i,t}^{(k)}=ReLU(W^{(k)}*Y_{i,t}^{(k-1)}+b^{(k)})\;\;\;\;\;\;(1) Yi,t(k)=ReLU(W(k)∗Yi,t(k−1)+b(k))(1)其中 k k k代表层数,卷积层后接flatten层和全连接层输出空间依赖关系。
使用原始的LSTM处理时间依赖关系。 h i , t = L S T M ( [ y i , t ; e i , t ] , h i , t − 1 ) ( 2 ) h_{i,t}=LSTM([y_{i,t};e_{i,t}],h_{i,t-1})\;\;\;\;\;\;(2) hi,t=LSTM([yi,t;ei,t],hi,t−1)(2)其中 y y y为CNN的输出, e e e代表外部因素(天气等), h h h为上一时刻的输出。
(二)空间动态相似性:门控机制
然而,既有文章提取的空间依赖性是静态的,不能充分反映目标区域与其相邻区域之间的动态关系。表示区域间交互的更直接的方法是交通流。如果两个区域之间存在更多的客流,它们之间的关系就会更强(即,它们更相似,也就是文章中说的相似性)。因此,我们设计了一种门控机制(Flow Gating Mechanism),以捕捉层次结构中的动态空间依赖关系。
这块其实就是将局部区域 S × S S×S S×S网格内的OD矩阵考虑到了空间关系的提取当中去了。提取两个矩阵,一个是出发的OD矩阵(t时刻O点出发到达各D点),一个是到达的OD矩阵(t时刻各个D点出发到达O点),其实这类也不能叫做OD矩阵,暂且这样叫吧。(这一块感觉提取方式就是提取全网的两个矩阵,然后用 3 × 3 3×3 3×3的filter去卷积,就是所谓的局部区域 S × S S×S S×S网格)
给定一个特定的区域 i i i,我们从过去的 l l l个时间间隔(即,时间区间 t − l + 1 t - l + 1 t−l+1到 t t t)。将获得的OD矩阵进一步叠加,用 F i , t ∈ R S × S × 2 l F_{i,t}\in\R^{S×S×2l} Fi,t∈RS×S×2l表示,其中 S × S S×S S×S表示周围相邻区域的大小, 2 l 2l 2l为流动矩阵的个数(每个时间间隔两个上面说的OD矩阵),叠加的矩阵包含了所有与区域 i i i相关的过去的流量间的相互作用。这一块的卷积结果用下式表示: F i , t ( k ) = R e L U ( W f ( k ) ∗ F i , t ( k − 1 ) + b f ( k ) ) ( 3 ) F_{i,t}^{(k)}=ReLU(W_f^{(k)}*F_{i,t}^{(k-1)}+b^{(k)}_f)\;\;\;\;\;\;(3) Fi,t(k)=ReLU(Wf(k)∗Fi,t(k−1)+bf(k))(3)将式(1)和式(3)两个卷积的output相乘,即得到式(4)。这个乘法也就是文章中所说的门控机制。同样,卷积层后接flatten层和全连接层输出空间依赖关系 ,至此空间关系提取完毕。 Y i . t ( k ) = R e L U ( W ( k ) ∗ Y i , t ( k − 1 ) + b ( k ) ) ⊗ σ ( F t i , k − 1 ) ( 4 ) Y_{i.t}^{(k)}=ReLU(W^{(k)}*Y_{i,t}^{(k-1)}+b^{(k)})\otimes\sigma(F^{i,k-1}_t)\;\;\;\;\;\;(4) Yi.t(k)=ReLU(W(k)∗Yi,t(k−1)+b(k))⊗σ(Fti,k−1)(4)
(三)时间动态相似性:周期性注意力转移机制
要读懂这一块肯定要理解透彻RNN注意力机制是怎么实现的,可参考这篇文章,讲的很清楚:深度学习中的注意力机制。
只使用前几个时间间隔(通常是几个小时),忽略了长期依赖性(如周期性)。所以应该考虑对预测目标的相对时间间隔(例如,昨天和前天的同一时间)进行建模。然而,单纯考虑相对时间间隔是不够的,忽略了周期性的时间转移,即,交通数据并非严格意义上的周期性。例如,工作日的高峰时间通常在下午,但可以从下午4:30到6:00。由于交通事故或交通拥挤,周期性信息的时间转移在交通序列中普遍存在。下图中显示了在不同的天和周之间的时间转移。因此,我们设计了一个周期性注意力转移机制(Periodically Shifted Attention Mechanism)来解决这些问题。
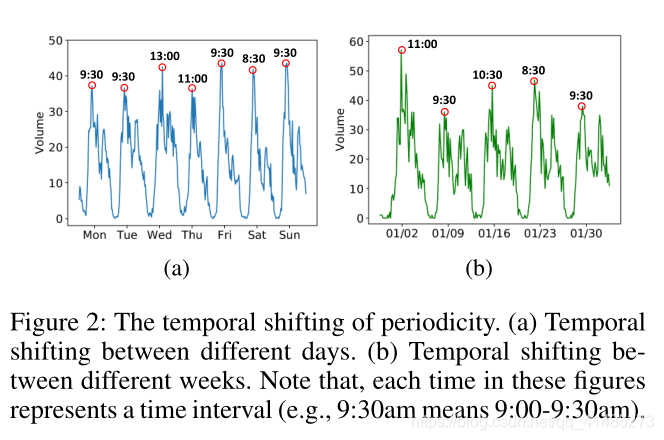
我们的重点是处理不同天之间的周期性的变化。如图1(a)所示,包含了前 P P P天对应的时间间隔来处理周期性依赖关系。对于每一天,为了解决时间移动的问题,我们在 Q Q Q中进一步选择每天的 Q Q Q时间间隔。例如,如果预测的时间是晚上9:00-9:30,我们选择预测时间的前后1小时(即8:00-10:30pm, Q = 5 Q = 5 Q=5)。这些时间间隔 q ∈ Q q∈Q q∈Q用于处理潜在的时间周期性转移。此外,我们使用LSTM来表达每天 p ∈ P p∈P p∈P的序列信息,其表达式为: h i , t p , q = L S T M ( [ y i , t p , q ; e i , t p , q ] , h i , t p , q − 1 ) , ( 5 ) h_{i,t}^{p,q}=LSTM([y_{i,t}^{p,q};e_{i,t}^{p,q}],h_{i,t}^{p,q-1}),\;\;\;\;\;\;\;\;\;\;(5) hi,tp,q=LSTM([yi,tp,q;ei,tp,q],hi,tp,q−1),(5) h i , t p , q h_{i,t}^{p,q} hi,tp,q为第 i i i区域预测时间 t t t在前一天 p p p中的时间 q q q的表示( p p p代表同一天,可以把 p p p去掉来看这个公式)。我们采用注意机制来捕捉时间的变化,并得到每一天的加权表示。形式上,某天的 h i , t p h_{i,t}^{p} hi,tp表示为每个选定时间间隔 q q q中表示的加权和(即上面说的 Q = 5 Q=5 Q=5那5个时段的加权和),定义为: h i , t p = ∑ q ∈ Q α i , t p , q h i , t p , q ( 6 ) h_{i,t}^{p}=\sum_{q\in Q}\alpha_{i,t}^{p,q}h_{i,t}^{p,q}\;\;\;\;\;\;\;\;\;\;(6) hi,tp=q∈Q∑αi,tp,qhi,tp,q(6) α \alpha α代表同一天不同时段的重要性,其计算就用到了注意力机制: α i , t p , q = exp ( s c o r e ( h i , t p , q , h i , t ) ) ∑ q ∈ Q exp ( s c o r e ( h i , t p , q , h i , t ) ) ( 7 ) \alpha_{i,t}^{p,q}=\frac{\exp(score(h_{i,t}^{p,q},h_{i,t}))}{\sum_{q\in Q}\exp(score(h_{i,t}^{p,q},h_{i,t}))}\;\;\;\;\;\;\;\;\;(7) αi,tp,q=∑q∈Qexp(score(hi,tp,q,hi,t))exp(score(hi,tp,q,hi,t))(7)其中 h h h就是hidden state,上述中5个时间间隔的隐层状态(也即5个timesteps的隐层状态),score函数就相当于注意力机制中的相似性函数,整个函数就是个softmax。
上面求的是前一天的一个总的加权和隐藏层状态,前一天的状态传递到当天即为公式: h ^ i , t p = L S T M ( h i , t p , h ^ i , t p − 1 ) ( 9 ) \hat h_{i,t}^p=LSTM(h_{i,t}^p,\hat h_{i,t}^{p-1})\;\;\;\;\;\;\;\;(9) h^i,tp=LSTM(hi,tp,h^i,tp−1)(9)Figure1(a)可以理解为有分支的stacked LSTM, 分支求的是每天的隐层状态加权和,主LSTM利用该加权和进行预测。
该模型在github上有一个项目可以参考:STDN
五、案例分析
模型的损失函数由于是预测的各个区域的吸引量和产生量,所以也就变为
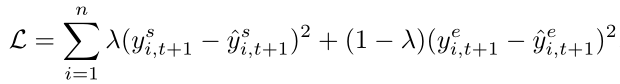
是inflow和outflow共同的MSE, λ λ λ是衡量两者影响大小的参数,所用数据是纽约的出租车和共享单车数据集。
出租车:从2015年1月1日到2015年3月1号共2200万条出行记录,其中前40天训练,后20天测试。
共享单车:自行出轨迹数据是从2016年7月1号到2016年8月29号共260万条出行记录,其中前40天训练,后20天测试。
数据处理:我们将整个城市划分为10×20个区域。每个区域的大小约为1km×1km。每个时间间隔的长度设置为30分钟。我们使用Min-Max归一化将流量转换为[0:1]规模。预测完成后,对预测值进行反归一化并进行评价。我们对训练和测试数据都使用滑动窗口来生成样本。在对模型进行测试时,我们对体积值小于10的样本进行过滤,这是工业和学术中常用的做法。因为在实际的应用中,关心低流量几乎没有什么意义。我们选择80%的训练数据用于学习模型,剩下20%用于验证。
评价指标:MAPE,RMSE
参数设置:我们根据验证集的性能来设置超参数。对于空间CNN卷积部分,我们将所有卷积核大小都设置为3×3 ,64过滤器。所考虑的每个邻域的大小设为7×7。设K = 3 (层数),l = 2 (考虑OD矩阵的时间跨度)。对于时间LSTM部分,我们将短期LSTM的长度设为7 (即前3.5个小时), |P |= 3表示长期周期信息 (即前3天), |Q| = 3为周期性注意力转移机制 (即考虑相对于预测时间的前后半小时),LSTM隐藏层维数是128。通过Adam进行优化,batch size设置为64. 学习率设置为0.001。LSTM的dropout和recurrent dropout均为0.5。λ设置为0.5。