写在前面:《控制与决策》;中文核心
作者:李正欣、郭建胜

1 摘要
本文提出了一种实现方便、配置简单,并且能保证度量准确性的方法。
- 对多元时间序列进行多维分段拟合;
- 选取各分段上序列点的均值作为特征;
- 以特征序列作为输入,利用DTW实现相似性度量。
2 引言
时间序列是一种与时间相关的高维数据,广泛存在于金融、经济、工程领域。

2.1 多元时间序列问题介绍
相似性度量是时间序列数据挖掘的核心技术之一,其度量精度直接影响着数据挖掘的效果。
多元时间序列相似性度量的研究相对较少,还有较多尚未解决的问题。
2.2 相似性度量方法介绍
- 欧式距离(ED) 简单易实现,但是要求两条序列的长度必须相同,且无法处理序列在时间轴上的伸缩和弯曲。
- 奇异值分解(SVD) 把时间序列中的变量理解为随机变量,以相关系数矩阵作为特征提取的基础,利用线性坐标变换建立相似度量模型[缺点是,这种方法是基于统计的度量方法,不能描述观察值的时序关系
- 基于点分布特征的方法(PD) 也是基于统计的方法,动态时间弯曲距离(DTW) 支持不同长度时间序列的相似性度量,支持序列在时间轴上的伸缩和弯曲,具有较好的度量精度和鲁棒性。
- 趋势距离(TD) 以多元时间序列的倾斜角和时间跨度作为特征,降低了计算复杂度
3 多元时间序列特征提取
- 最直观的方法是,分别提取每一变量维度上的特征。
- 将每个分段上原始点的均值作为该段序列的特征。
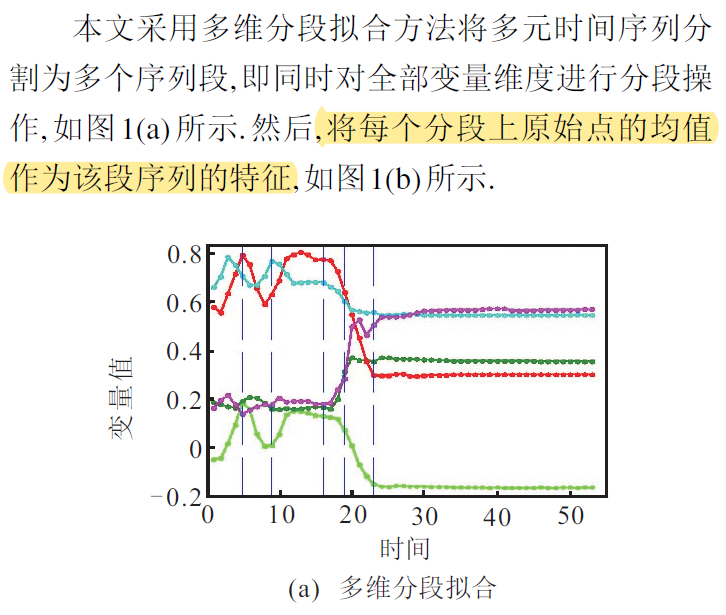
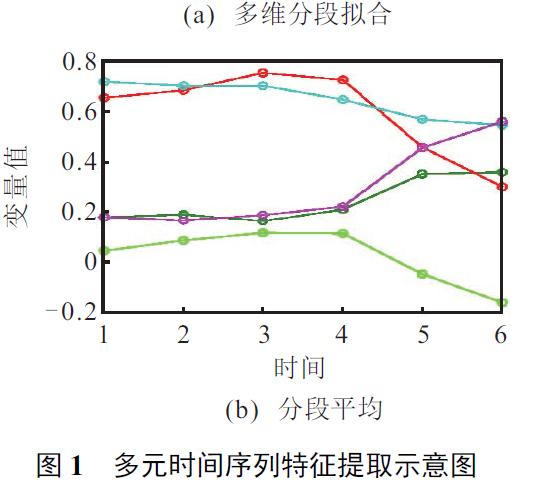
多维分段,并且用均值代表这一段的数据,既可以保持变量间的相关性,而且可以完成时间维度上的降维。


4 多元时间序列相似性度量
- DTW距离

在这里呢, D b a s e D_base Dbase说的是两个向量之间的基距离,通常使用欧式距离。
- 本质上,DTW距离用于确定序列X和Y上每个点之间的匹配关系。