文章目录
写在前面:《基于语义相似的水文时间序列相似性挖掘》;期刊:《水文》;主办单位:水利部水文局、水利部水利信息中心;月刊;中文核心期刊;
作者:朱跃龙,博士生导师

1 摘要
- 利用数据挖掘技术,从长期观测的数据序列中发现蕴藏的规律,是当前研究热点之一。
- 相似性挖掘是时间序列挖掘的基础
算法步骤安排:
(1) 首先利用小波变换将时间序列进行平滑处理;
(2) 在此基础上,进行极值点分段并符号化,每个符号代表一种语义模式,从而选取语义相似的子序列作为候选集;
(3)将候选集中子序列,通过动态时间弯曲距离进行精确匹配从而得到相似子序列(以太湖流域大浦口站水位数据为例),
实验证明,该方法能够在大幅度降低时间复杂度的基础上较准确地查找出相似子序列。
2 引言
-
时间序列数据挖掘,主要包括相似性分析、关联规则挖掘、模式发现、预测和周期分析等几个方面,而相似性挖掘是其中的一个重要课题,它是聚类、分类、关联规则发现以及周期分析的基础。
-
水文时间序列数据挖掘,可以用于雨洪过程预测、环境演变分析、水文过程规律发现等。
2.1 现有研究
- 简单综述
时间序列相似性研究,最早开始于Agrawal R提出的基于傅立叶变换的方法,之后逐渐又有离散小波
变换、符号化表示、分段聚集近似、分段线性变换等方法的提出,这些方法各有所长,分别适应于不同的应用领域。
- 相似性研究有两个点:对序列数据降维、定义相似度量函数
目前的研究中,上述的方法主要用于对时间序列数据变换的处理过程以达到降维的目的,而相似性度量问题也是相似性研究中的一个重要课题。主要方法有欧氏距离、动态时间弯曲距离(DTW)、斜率距离、最长公共字串,以及在此基础上的各种变形。
这些度量方法各有所长,也有各自的缺点,目前应用的最多的是动态时间弯曲距离(DTW)
2.2 本文的研究
-
引入语义的相关概念,提出一种基于语义相似的水文时间序列相似性挖掘方法。
-
首先,对水文时间序列进行小波变换,在此基础上进行极值点分段,并符号化。【创新点:先对序列进行小波变换,然后极值点分段(涉及到序列分段的概念),然后加入了一个符号化的概念】
-
分别理解各种符号的语义模式,找出所有与查询序列语义模式符号序列相似的子序列作为候选集【我倒要好好学习一下,这个是怎么理解各个符号的语义模式的!】
-
最后,分别对候选集中的序列,与原序列 都采用极值点分段,然后使用 DTW 距离匹配。
也就是说:先用语义符号相似匹配,筛除语义不同的子序列,然后根据DTW进行精确匹配。
- 文章的数据集:太湖流域大浦口站水位数据,对该方法进行验证。该方法不但能有效地降低 时间复杂度,而且还具有较好的准确性。
3 基于语义相似的水文时间序列相似性挖掘
3.1 什么是语义
- 语义就是数据的含义;语义可以简单看作是数据所对应的,现实世界中的事物所代表的含义,以及这些含义之间的关系;
- 数据就是符号;
3.2 小波变换
- 保留能够体现整体变化趋势的 局部极值点信息,而序列中的短期波动会影响对数据的处理,所以平滑处理是十分必要的。
注意:130d就是130天,d是单位

- 从下图可以看出,小波变换能够保持原有的整体变换趋势。
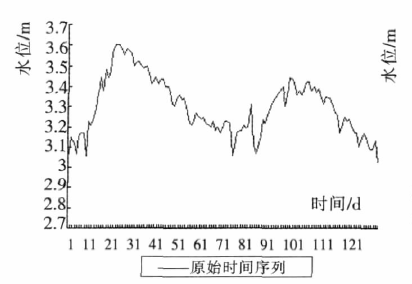
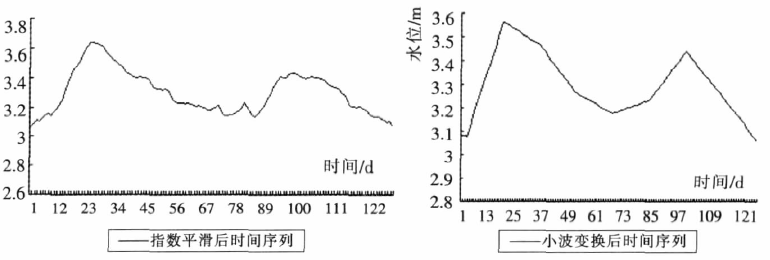
3.3 水文时间序列语义模式表示
- 在小波变换的基础上进行极值点分段

3.3.1 极值点线性分段表示
- 构建一个“新的时间序列”,用原时间序列的极值点构成
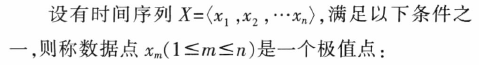

3.3.2 基于小波变换的时间序列语义模式表示
