文章目录
写在前面:《计算机与数字工程》;
作者:顾昕辰、万定生

1 摘要
-
传统DTW算法复杂度高,特别是当处理海量数据时,耗时长,效率低下。
-
本文是从算法和实现手段两个方面提高水文时间序列相似性比较效率,提出基于
Hadoop平台,以FastDTW方法实现的水文时间序列相似性查找方法。
【算法是对DTW进行优化,提出FastDTW;然后实现手段方面的优化是Hadoop分布式平台】 -
实现步骤:
① 利用小波变换,对数据去噪;
② 对水文时间序列进行语义化
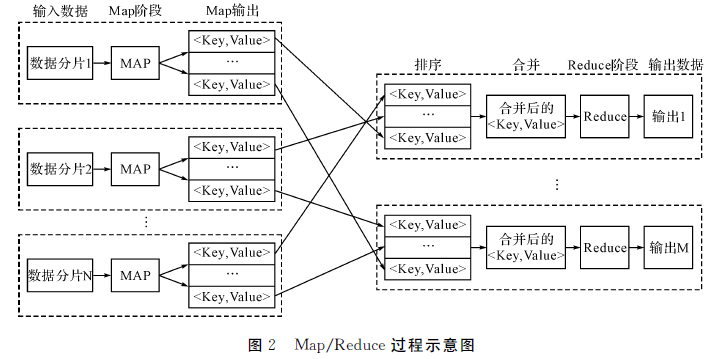
③ 在Hadoop的 MapReduce 过程中调用,FastDTW方法实现 DTW 距离的云计算,得到与查询序列最相似的匹配序列。
2 引言

- 在进行相似性比较时,会遇到:两个时间序列的总体趋势比较相似,但是相似的部分在时间轴上并不是对齐的。
- DTW能有效的解决这个问题,它可以将时间轴进行弯曲,使得相似性比较更加关注趋势相似,而不是简单的点距离相似。
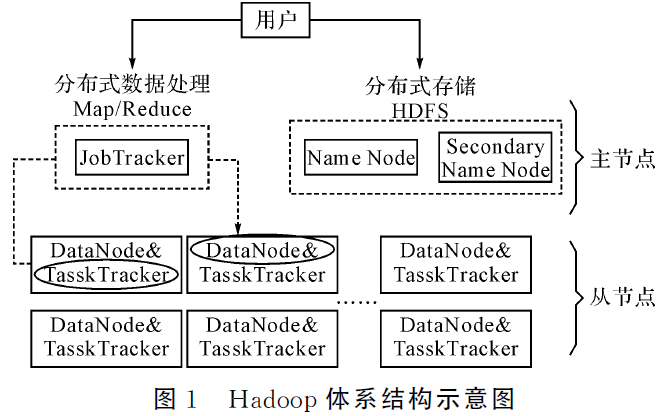
- Hadoop平台作为云计算思想的具体实现,使
得复杂的运算能在多台机器上并行执行,缩短运算用时。同时,它具有良好的扩展性、健壮性,使得数据挖掘高效且可靠。 - Apache Hadoop是一个用Java语言实现的软件框架,实现由大量普通商用计算机组成的集群,并在集群中对大量数据进行分布式处理。
3 MapReduce 计算模型

3.1 Hadoop体系结构
4 DTW 改进算法 FastDTW
-
DTW 采用动态规划来计算两个时间序列之间的相似性,算法的复杂度是 O ( N 2 ) O(N^2) O(N2)
-
本文采用的是文献5中的FastDTW

(1)首先将两个时间序列 粗粒度化,寻找最短DTW路径;
(2)然后将路径及其周围的点,逐步细粒度化,并再次寻找最短DTW路径;
(3)最终,求出原序列间的DTW距离。
4.1 介绍DTW算法
- 在时间序列中,需要比较相似性的两段时间序列的长度可能并不相等;
- 另外,不同时间序列可能仅仅存在时间轴上的位移,在还原位移的情况下,两个时间序列变化趋势是一致;


4.2 FastDTW 方法
-
粗粒度化
采用PAA方法,通过对时间序列等宽度分割,然后用均值来表示这一段的值。

-
投影
在较粗粒度上对时间序列进行DTW算法。求出最短DTW距离对的规整路径。 -
细粒度化
将 在较粗粒度上得到的规整路径,经过方格进一步细粒度化,同时为了避免由于粒度的 过度粗糙 造成的路径偏差。

5 水文时间序列相似性查找方法
5.1 水文数据的预处理
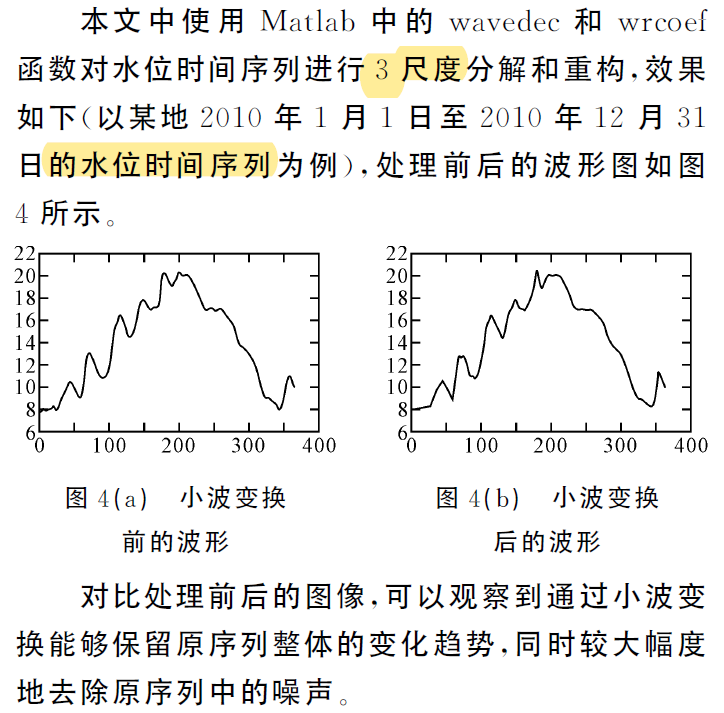
- 小波去噪
通过小波变换,可以将水文时间序列分解成确定成分和随机成分,除了可以进行原始序列 主周期识别以外,还能对序列的突变特征进行识别。

-
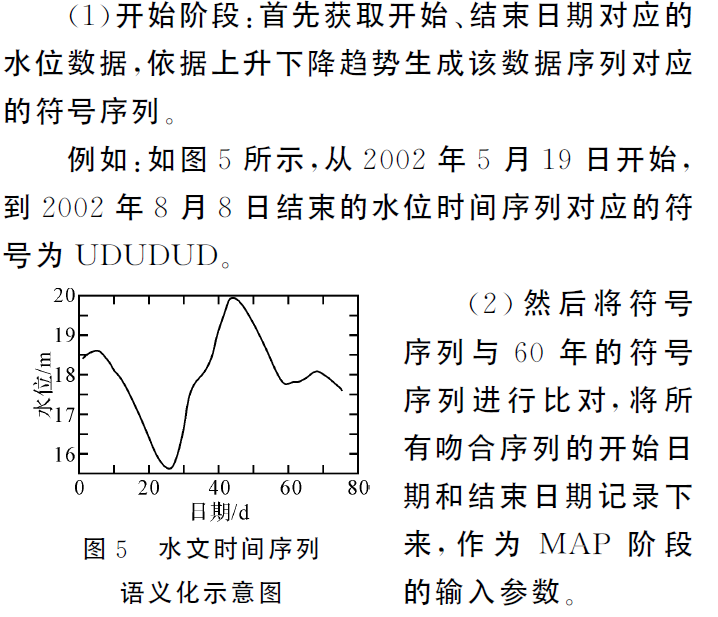
水文时间序列语义化
寻找水位时间序列中,特征明显的极大极小值,作为对序列语义化的依据。
按照时间顺序,将极值点之间的水文,上升段记为U,下降段记为D。 -
极值点的定义
考虑到小波去噪之后,序列波形中仍存在一些小幅度波动。为了提取出特征明显的极值点:

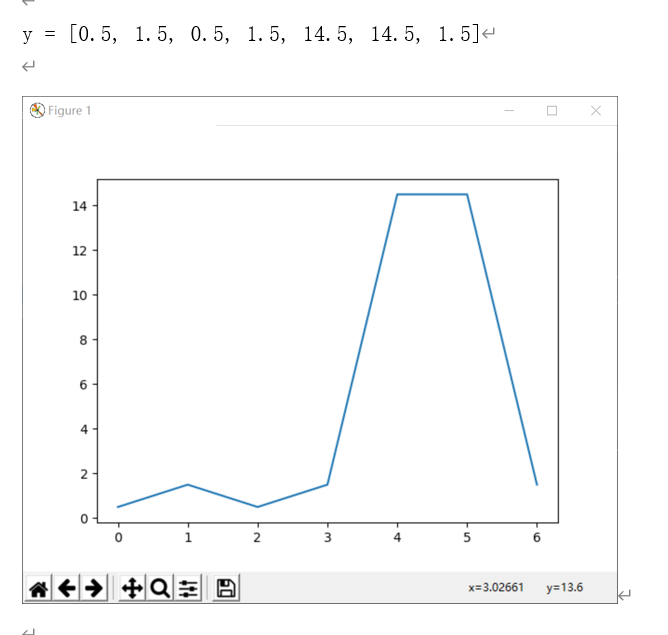
④ 的重要性可以看上图,可以看出时间点1和时间点2是不应该算成极值点的,这两个波动是不需要被关注的,对于整体的趋势是没有太大意义的。
- 所以说,阈值 r 至少要占到 2/3的max 吧。
- UD 分段的定义:(也就是语义化)


5.2 MapReduce过程