论文链接:https://arxiv.org/abs/1603.05027
本篇文章是对ResNet取得较好效果的分析与改进,在过去residual block的基础上,提出了新的residual block,并通过一系列实验验证了identity mapping能对模型训练产生很好的效果。
1、介绍
1、ResNet block表示:
resnet block结果如下:
resnet block公式表示如下:
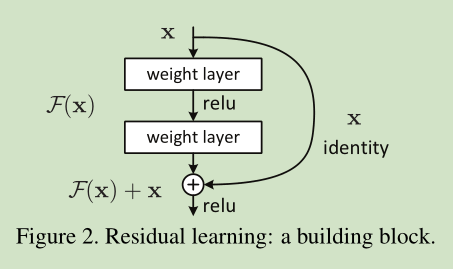
其中 和 是第l个单元的输入和输出,f表示一个残差函数。在He,ResNet论文中, 代表一个恒等映射,f代表 ReLU。
2、Analysis of Deep Residual Networks
在resnet表达式中,如果f是一个恒等映射:
,我们可以将公式合并得到:
通过递归:如下面例子帮助理解
对于任意深的单元 L 和任意浅的单元 l,可以得到:
该公式展示了一些良好的特性,如下:
- 对于任意深的单元L的特征 可以表达为浅层单元l的特征 加上一个形如 的残差函数,这表明了任意单元L和l之间都具有残差特性。
- 对于任意深的单元L,它的特征 ,即为之前所有残差函数输出的总和加上x0。
- plain network中的特征 是一系列矩阵向量的乘积,也就是 (忽略了BN和ReLU)。
- 具有良好的反向传播特性:

这里,梯度 可以被分解成两个部分:其中 直接传递信息而不涉及任何权重层,而另一部分 表示通过权重层的传递。 保证了信息能够直接传回任意浅层 l。
同时,该公式表明在mini-batch中梯度不可能出现消失的情况,因为通常 对于一个mini-batch总的全部样本不可能都为-1。这意味着,哪怕权重是任意小的,也不可能出现梯度消失的情况。
3、On the Importance of Identity Skip Connections
1、 替代恒等。
即:
则:根据递推
反向传播过程:

如果对于所有的i都有 λi>1,那么这个因子将会是指数型的放大;
如果λi<1 ,那么这个因子将会是指数型的缩小或者是消失,从而阻断从捷径反向传来的信号,并迫使它流向权重层。
Experiments on Skip Connections
作者设计了constant scaling、exclusive gating、short-only gating、1*1 conv shortcut以及dropout shortcut来替代h(xl)=xl,实验中都是基于f= ReLU,如下图:


- 经过实验发现,h(xl)=xl的误差衰减最快、误差也最低,而其他形式的都产生了较大的损失和误差。
- 作者分析,连接中的操作 (包括:缩放、门控、1×1 的卷积以及 dropout) 会阻碍信息的传递,以致于对优化造成困难。
4、On the Usage of Activation Functions
作者进一步探索激活函数位置对于网络的影响,设计了如下网络:



- fig(b)效果不明显,BN层改变了流经捷径连接的信号,并阻碍了信息的传递,这从训练一开始降低训练误差的困难。
- fig(c) 加入relu 导致输出永远为正数,然而一个“残差”函数的输出应该是(−∞,+∞)。
- 预激活替代后激活,效果提升较高,且全预激活效果最好。
预激活分析
- 使模型优化变得更为简单,层数较多时候尤为明显。
- 降低过拟合。

