1. 聚类的基本思想
再介绍下面这篇论文之前,我们先来回顾一下聚类算法的核心思想。其核心主要是让聚类后的各个簇“离得尽可能远”,这样就能最大程度上使得聚类的准确度最高。那么现在的问题就是我们应该如何来量化“离得尽可能远”呢?或者什么叫“离得尽可能远”,怎么来刻画?
我们都知道传统Kmeans算法仅仅只是最小化簇内距离(先计算每个簇中,每个样本点到其簇中心距离和 ;再计算 ,其中最小化 就是Kmeans的思想)。我们可以看到它并没有考虑簇间距离,但从直觉上来说,最小化簇内距离,并且同时让各个簇“离得尽可能远”,这样将会使得聚类效果更好。所以,下面这篇文章的主要思想就是: 最小化簇内距离,同时最大化簇间距离(“离得尽可能远”)
2. ESSC算法
在之前的子空间聚类论文中,如WKMeans,EWKMeans等等。在这些算法中,毫无例外得都没有考虑到簇间聚类在聚类中所起到得作用。在这篇论文中,作者提出了通过最大化各个簇中心点到全局中心点得距离和来达到最大化簇间距离得目的。
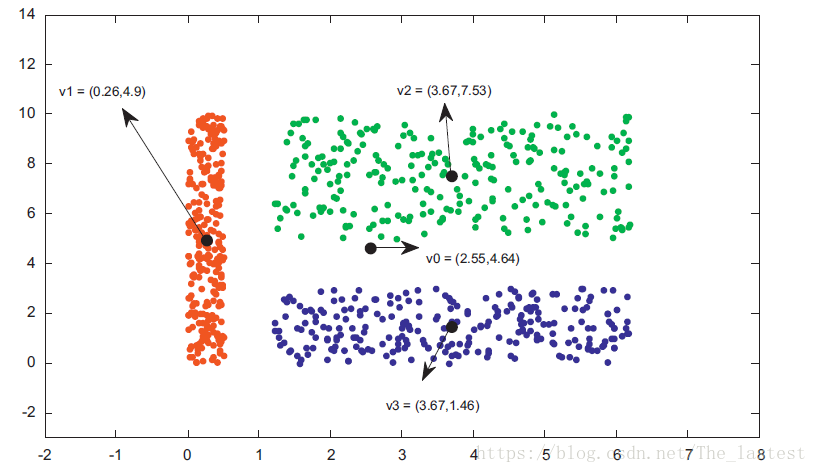
注:论文中这个图是用来说明两种权重形式得区别,我这儿是借用这个图来说明论文的主要思想
如图所示,一共样本点中一种有3个簇 ,其中心点分别为 。 为所用样本的中心点,即全局中心。ESSC算法的思想就是,在最小化簇内距离的时候,同时最大化 到 的距离和(即簇间距离),然后通过超参数 来调节簇间距离的影响程度。从直观上看,这种做法确实能达到我们想要的目的。
2.1 目标函数
其中:
表示簇数;
表示样本点数;
表示维度;
是中心点矩阵;
是权重矩阵;
是样本点分配矩阵;
;
可以看出,蓝色部分基本上就是继承EWKMeans的目标函数,唯一不同的是:
①此处
例如,某个样本的分配矩阵为
,则其对应属于第三个簇;
②分配矩阵上多了一个指数
(fuzzy index);
2.2 迭代求解



2.3 算法实现
源码
实现的算法总体上能用,但仍有许多细节的地方可以优化。