Subspace Clustering详解
第二十四次写博客,本人数学基础不是太好,如果有幸能得到读者指正,感激不尽,希望能借此机会向大家学习。这一篇作为密度聚类算法族的第三篇,主要是介绍一种用来发现子空间中的簇的算法——Subspace Clustering,并对该类算法中最具代表性的CLIQUE(Clustering in quest)算法进行介绍,其他密度聚类算法的链接可以在《DBSCAN详解(密度聚类算法开篇)》这篇文章的最后找到。
子空间聚类(Subspace Clustering)
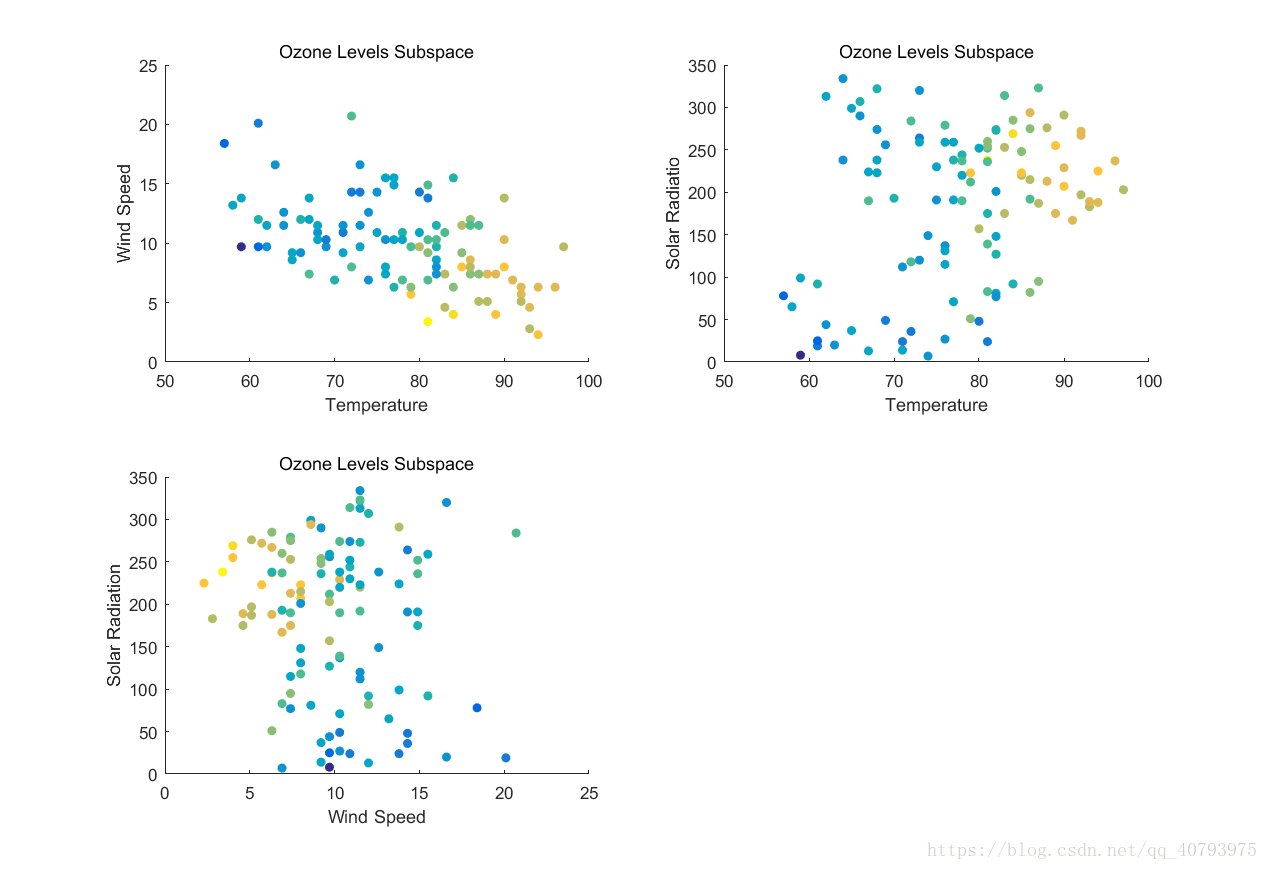
在聚类任务中,有时考虑数据集的所有属性会降低聚类效率和簇的有效性,因为样本在某些属性上存在真正的簇划分,而在其他属性上则是随机分布的,这时在数据集高维空间中的低维子空间中进行聚类就十分重要了,而且不同的子空间会产生不同的簇划分。以不同温度、风速和太阳辐射下的臭氧含量为例,如下图所示不同颜色表示臭氧含量的不同

下面在三个不同的子空间观察这些数据,可以看出在这些空间中数据分布各有特点,有些空间中的数据甚至看不出明确的簇
上述例子展示了不同特征子空间中的数据所呈现的不同特点,下面用一个更加明确的例子来展示子空间聚类的效果,如下图所示,在三维空间中存在三个簇分别标记为菱形、正方形和三角形,还有一些看似随机分布的被标记为圆形的样本,下面采用等宽法将每个特征划分为20个区间,每个区间的宽度为0.1,由于每个网格单元是等体积(面积)的,因此单元中的样本点数即单元密度,下面将邻接的稠密单元合并为一个簇,以一维空间下的属性 为例,如图(4)所示可以识别出三个簇


上述例子阐释了两个道理,第一,一个点集(如上圆形点)在整个属性空间上可能不能形成簇,但是在子空间中却可能形成簇,第二,存在于整个属性空间(甚至子空间)中的簇会作为低维空间中的簇出现。因此,往往需要在子空间中发现簇,而这些簇可能是高维空间中的簇的投影,但是发现低维空间中的簇正是这种聚类算法的目的。
CLIQUE(Clustering in quest)聚类
CLIQUE聚类是在1998年由Rakesh Agrawal、Johannes Gehrke等人提出的(原始文献见《Automatic Subspace Clustering of High Dimensional Data for Data Mining Applications》),一种子空间聚类方式,并且应用了基于网格的聚类方法,该算法主要具有以下优点:(1)可伸缩性(2)可以发现在数据集高维空间中子空间的簇(3)聚类模型具有很好的解释性(4)没有对输入数据的次序依赖性(5)不需要事先假定数据集满足某种概率分布。与DBSCAN等基于密度的聚类算法不同的是,CLIQUE算法并不关注整个高维空间,因此它可以更有效的得到原始数据空间的子空间的簇。CLIQUE算法步骤分为一下三部分:
1) 识别包含簇的子空间;
2) 识别这些簇;
3) 产生这些簇的 “最小描述”。
其中,最小描述(minimal description)是指这些簇不重复包含任意稠密网格单元,下面分别对上述部分进行介绍。
(1) 识别包含簇的子空间
识别包含簇的子空间的困难在于如何寻找子空间中的稠密网格单元,最简单的方法是基于子空间中每个网格单元所含有的样本点数,来绘制所有子空间的样本点分布直方图,然后根据这些直方图进行判断。显而易见的是,这种方法并不适用于高维数据集,因为子空间的数量随维度的增加呈指数级增长。Rakesh Agrawal在本文中介绍了另一种“由下至上”(bottom-up)的识别方法,这种方法的理论依据是簇评判的单调性原则。
簇评判的单调性原则:如果一个样本点集(簇)
是
维空间的一个簇,那么
是该空间的任意
维子空间中某个簇的一部分。证明如下,假设
是
维空间的一个簇,由基于网格聚类的原理可知,这个簇是由多个稠密且邻接的网格单元组成的,在任意子空间的某个对应网格中必定存在所有的这些点,因此这个子空间的网格也是稠密的,而
中这些稠密网格的临近性在子空间中也会得到保持。
这种算法是“逐级执行”的,他首先遍历一次原始数据集,得到
维稠密网格单元,当得到
维稠密网格单元后,就可以通过下图(图5)所示的步骤产生候选的
维稠密网格单元,得到候选的
维稠密网格单元后,再遍历一次数据集来确定真正的
维稠密网格单元,重复上述操作直到不再产生候选的稠密单元为止。

上图所示的步骤将所有
维稠密网格单元的集合
作为参数,最终得到一个包含所有
维稠密网格单元集合的超集
,其中,
代表第
个稠密的
维网格单元,
代表
的第
个维,而
和
分别代表
所在的第
个维的网格上界和下界。
中的伪代码用于筛选两个相似的
维稠密网格单元,他们在
个维度上是相同的,然后将他们组成一个候选的
维稠密网格单元,在这里我们可以看出,为了不会产生重复的候选稠密网格单元,在筛选条件的最后一行使用的是
而不是
,要注意的是,这里的维度比较是依赖于下标的有次序的比较,而不是交叉比较。
上述步骤与Apriori算法产生候选频繁项集的方法类似,在重新遍历一次数据集来找到
中的真正稠密单元之前,由簇评判的单调性原则可知,在得到包含所有
维稠密网格单元集合的超集
后,要先删除集合中那些在任何一个
维子空间中不稠密的
维网格单元,之后再进行数据集的遍历。
这种使用先验知识约束来缩小搜索空间的方法与Apriori算法中寻找频繁项集的方法类似,他具有可伸缩性的特点,其时间复杂度是
,
是一个常数,
是所有稠密单元的最大维度,
是数据集的样本点个数,通过特定的手段可以减少遍历数据集的次数。与一般的基于密度的聚类方法相同,当评判网格稠密与否的阈值
设置的过小时,维数较低的子空间将会产生更多地稠密单元,随着这些被误判为包含簇的子空间数目上升,搜索空间将会以指数级增长。为了应对这种问题,文中还提出了一种基于“最小描述长度”(MDL)原则的改进方法,这种方法通过只关注那些“有趣的”子空间来大大减小搜索空间。
(2) 识别稠密单元产生的簇
这里簇识别的方法与基于网格的聚类相同,都是将邻接的稠密网格单元结合成为一个簇,具体的说,基于“深度优先原则”,先从
维稠密单元集合
(伪代码中用
表示)中随机选出一个稠密的网格单元,并将它单独初始化为一个簇,之后遍历
将与该单元邻接的稠密单元划分到这个簇中,如果遍历完成后仍存在没有被划分的单元,那么在这些单元中随机再取出一个作为新的簇,然后重复上一步骤,直到所有的单元均有各自的簇隶属为止。该算法的时间复杂度为
,
为
的大小,如果采用哈希树等数据结构,会得到更快的搜索速度,伪代码如下图所示。

(3) 产生簇的“最小描述”
这一部分是全文的核心的核心,他决定了最后得到的聚类模型的可解释性,该过程将某个
维子空间
中的多个互斥的簇(稠密网格单元集合)未作为输入,输出的是簇的“最小描述”,这个“最小描述”是一个区域(region)的集合
,其中每个区域
都包含在稠密网格单元集合
中,并且
中的每个稠密单元都要至少属于这些区域中的一个,这显然是一个NP-hard问题。Rakesh Agrawal在本文中给出的方法具体分为两步:
1) 使用“贪心增长算法”,获得覆盖每个簇的最大区域;
2) 通过丢弃被重复覆盖的网格单元,来得到“最小描述”。
下面分别对这两步进行详细描述,
a) 获得覆盖每个簇的最大区域
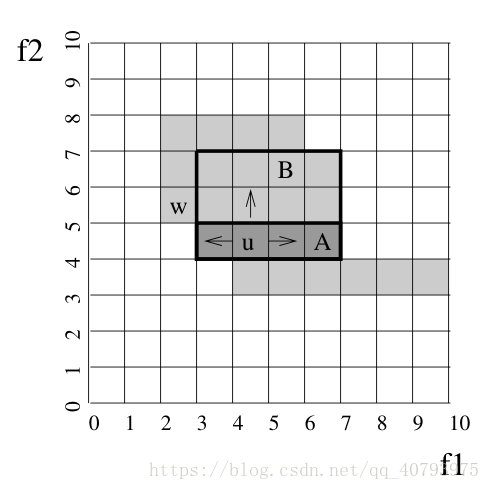
在这一步中,我们将簇中的某个稠密单元作为初始区域,然后在某一个维度上,基于其(左、右)邻接单元将该区域进行延伸,延伸完成后,在另一个维度上,基于该区域中的所有稠密单元的邻接单元对该区域做进一步延伸,重复上述步骤直到遍历所有的
个维度,然后对该簇中没有被包含到对应区域的单元继续重复上术操作,直到没有孤立的网格单元为止,需要注意的是,上述操作形成的区域是一个空间线性多边体。下面举一个2维空间的实例来进行说明(如图7所示),假设
、
为该子空间的两个维度,用灰色代表稠密单元,其中稠密单元
是我们选择的初始区域,首先将
在维度
上做延伸得到区域
,然后基于区域
中每个单元,对该区域在维度
上做进一步延伸得到区域
。完成上述步骤后,可以注意到单元
没有被包含到该区域中,这时可以对
重复上述操作。
可以证明在最坏的情况下,该算法的时间复杂度是 ,这里 是该簇所含稠密单元的数量, 是该簇所在子空间的维数,这里的“最坏情况”指的是,对于 个稠密单元,这些单元组成的邻接区域含有 个“角”,下面举一个2维空间的实例(如图8),可以看出该算法在这个空间中的时间复杂度为 。

b) 得到“最小描述”
这里文中推荐使用一种启发式的移除冗余单元的方法,具体来说就是首先找到最小的(包含的稠密单元数量最少)最大区域,如果这个最大区域中的每个单元均在其他区域中重复出现过,那么就从该簇的最大区域集合中移除该区域,直到找不到下一个类似区域为止,该算法的时间复杂度是
。由于簇的每个区域都可以用一组基于子空间维度的不等式来表示,因此最终通过这些不等式来描述整个簇。
参考资料
【1】《机器学习》周志华
【2】《数据挖掘导论》
【3】Agrawal R, Gehrke J, Gunopulos D, et al. Automatic subspace clustering of high dimensional data for data mining applications[C]// ACM SIGMOD International Conference on Management of Data. ACM, 1998:94-105.
