Deep similarity learning for multimodal medical images
Abstract
- 有效的多模态图像相似度度量是医学图像融合在许多临床应用中的关键。
- 提出了一种新的深度相似度学习方法,训练一个二值分类器来学习两个图像patches之间的对应关系。将分类器的输出转换为连续的概率值,然后用作相似性评分指标。
- 提出利用多模态堆叠去噪自编码器来有效地预训练深度神经网络。
- 使用来自同一受试者的采样对应/非对应计算机断层扫描和磁共振的头部图像patches来训练和测试所提出的指标。
- 与NLI和LCC进行比较,产生的相似性度量具有更好地准确性和鲁棒性
1. Introduction
互信息和KL散度对于多模态配准尤其是多模态变形配准存在局限性,主要是因为局部强度分布的统计量不足以描述具有不同底层成像物理原理的模态之间的复杂关系。
为了应对这一挑战,提出了有监督的相似度度量学习。
与传统的图像分类或检测问题不同,将图像/patches直接输入到DNN分类器,学习图像之间的相似性更加困难。传统DNN在此不适用,学习目标也不明确。
为了解决这一问题,我们提出了一个有监督的深度学习框架来构建跨模态图像之间的相似性度量。
我们还提出使用多模态堆叠去噪自动编码器(SDAE)来有效地预训练DNN。
2. Methods
2.1 Similarity metric learning
想学习一个函数 f ( x 1 , x 2 ) f(x1, x2) f(x1,x2)来计算来自不同图像形态的一对patchs——x1和x2之间的相似度分数。
监督学习需要ground-truth。
x1和x2之间唯一的信息就是它们对应的状态。因此,我们的相似度学习的目标是构造二值函数g(·),它可以将每个图像对分类到其标记状态。(即将两张图像是否对应作为ground-truth)
由于g(.)可能是分复杂,所以使用了全连接DNN,其结构如下:
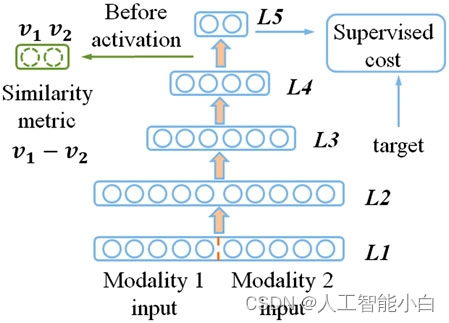
图一.5层DNN的结构。当2单元的输出用于监督训练时,它们在激活前的值,即v1, v2用于形成提出的相似度度量。
输出层有两个单位,表示分类结果,即’ 10 ‘表示对应,’ 01 '表示不对应。将结果与训练图像对的标签进行比较,以驱动模型参数的优化。同时,使用sigmod函数(激活层)的输入(v1,v2)作为x1和x2相互对应的概率,训练阶段结束后,使用f = v1−v2作为相似度评分指标。
2.2. DNN pre-training
2.2.1 Stacked denoising autoencoder
这一部分介绍了什么是SDA,用处不大
2.2.2 Multi-modal SDAE
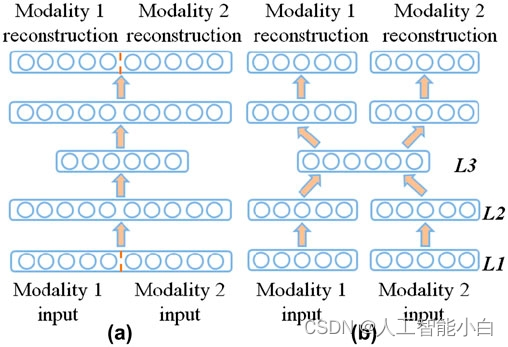
图中(a)为uni-modal SDAE,(b)为multi-modal SDAE 。论文中说使用multi-modal SDAE 可以更有效地进行建立相关性模型,具体原因没有去深究。
之后用multi-modal SDAE的训练结果去初始化DNN的底层三层 (L1~L3),将将L1和L2之间缺失的连接设置为零(因为DNN是全连接的,而multi-modal SDAE并不是)。

上图是multi-modal SDAE中学习到的连接L1和L2的权重矩阵W的一部分,它可以被解释为用于特征检测的滤波器。左图为CT模态,右图为MRI模态。
3. Experimental results
3.1. Experimental data and parameter selection
这一部分介绍了训练的数据和模型参数的选择,作者选用了2D-patchs进行训练,感兴趣的可以去看原文。
3.2. Similarity metric evaluation
这里作者说生成的 similarity metric并不适合非刚性配准,所以使用了相似值的秩作为预测误差来评估所提出的度量,这部分没看懂,反正最后作者得到了自己的模型产生的metric比其他的metric要好,anyway,对于模型复现而言,这也不重要,跳过吧。
4. Conclusion and future work
future work简单来说有两点:
- 将提出的相似度度量从2-D扩展到3-D
- 将其纳入非刚性配准框架以进行进一步评估