参考代码:StreamPETR
1. 概述
介绍:在BEV感知中时序信息融合会为下游感知任务带来不小性能提升,但是在单帧基础上引入时序信息必然会带来额外开销,因而迫切需要一种高性能且代价小的融合方案。现有的一些时序融合策略多是在BEV特征空间维度上完成的,并且对于一些DETR-based方案本身就没有显式构建BEV特征,如PETR,则BEV特征空间上的时序融合方法就不适用了。对此,这里基于PETR中DETR-based方案提出了一种使用query实现多桢object-centric的时序融合策略,也就是不在BEV特征或者图像特征维度实现时序融合,只是在query针对目标去做融合。由于感知的目标是可能存在运动的,则需要建立起帧间运动关系,这里可以使用目标的运动信息(间隔时间、速度、相机内外参数等)构建目标的运动感知模块(MLN,motion-aware layer normalization),这样就可以为场景中的运动目标进行处理。
之前工作中对于BEV特征融合的策略可以为下图中的左边两幅图:
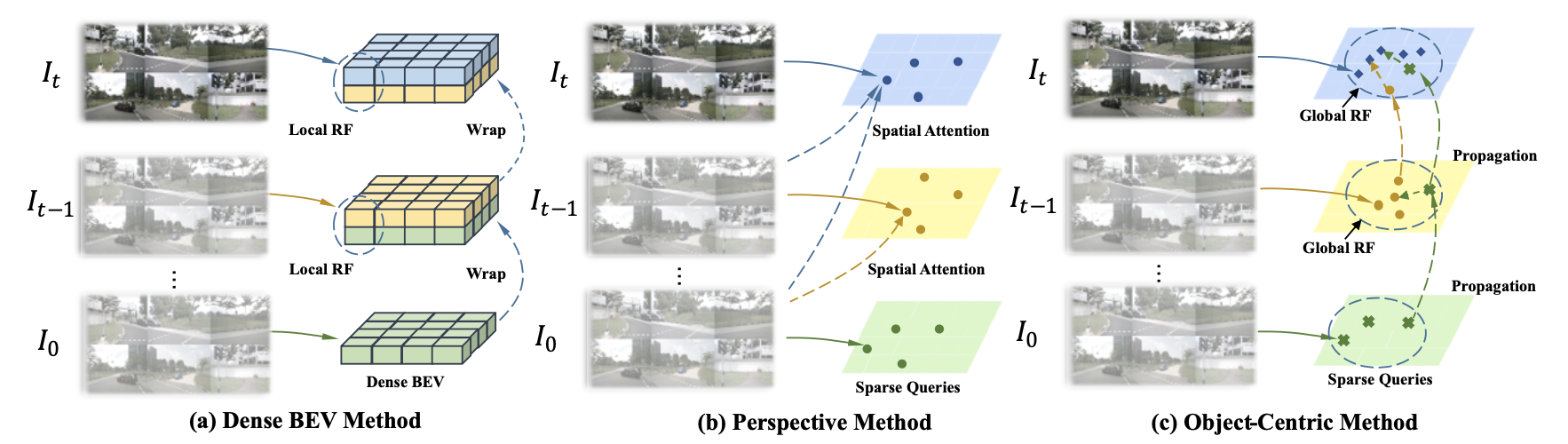
直接特征图上的时序关联:
这种类型的时序建模是直接操作于BEV空间上,如对不同时刻BEV特征在经过帧间pose对齐之后,通过一个网络直接融合,典型方法如BEVFusion:
F ˉ b e v t = φ ( F b e v t − 1 , F b e v t ) \bar{F}_{bev}^t=\varphi(F_{bev}^{t-1},F_{bev}^t) Fˉbevt=φ(Fbevt−1,Fbevt)
只用前面一帧的信息太少了,可以多利用之前帧的信息,典型方法是SOLOFusion:
F ˉ b e v t = φ ( F b e v t − k , … , F b e v t − 1 , F b e v t ) \bar{F}_{bev}^t=\varphi(F_{bev}^{t-k},\dots,F_{bev}^{t-1},F_{bev}^t) Fˉbevt=φ(Fbevt−k,…,Fbevt−1,Fbevt)
时序特征有自然的序列属性,那么可使用类RNN的方法去处理这类数据:
F ˉ b e v t = φ ( F ˉ b e v t − 1 , F b e v t ) \bar{F}_{bev}^t=\varphi(\bar{F}_{bev}^{t-1},F_{bev}^t) Fˉbevt=φ(Fˉbevt−1,Fbevt)
2D图像特征上做时序融合:
这类方法关注的不再是BEV特征而是任务的query,构建目标query直接在不同帧的2D图像上做cross-attention来获取query特征表达,如PETR(计算量真的受不了):
F ˉ o b j t = φ ( F 2 d t − k , F o b j t ) + ⋯ + φ ( F 2 d t , F o b j t ) \bar{F}_{obj}^t=\varphi(F_{2d}^{t-k},F_{obj}^t)+\dots+\varphi(F_{2d}^{t},F_{obj}^t) Fˉobjt=φ(F2dt−k,Fobjt)+⋯+φ(F2dt,Fobjt)
object-centric层次的特征时序融合:
为了弥补使用2D特征做cross-attention带来的巨大计算开销,文章提出在obj-wise上做时序融合,但由于场景目标是存在运动的,则这里就需要运动信息 M M M(包含时间戳、时间间隔、估计的速度等)对之前帧的目标进行补偿:
F ˉ o b j t − 1 = μ ( F o b j t − 1 , M ) \bar{F}_{obj}^{t-1}=\mu(F_{obj}^{t-1},M) Fˉobjt−1=μ(Fobjt−1,M)
完成目标补偿之后便可以与当前帧query做融合:
F ˉ o b j t = φ ( F ˉ o b j t − 1 , F o b j t ) \bar{F}_{obj}^t=\varphi(\bar{F}_{obj}^{t-1},F_{obj}^t) Fˉobjt=φ(Fˉobjt−1,Fobjt)
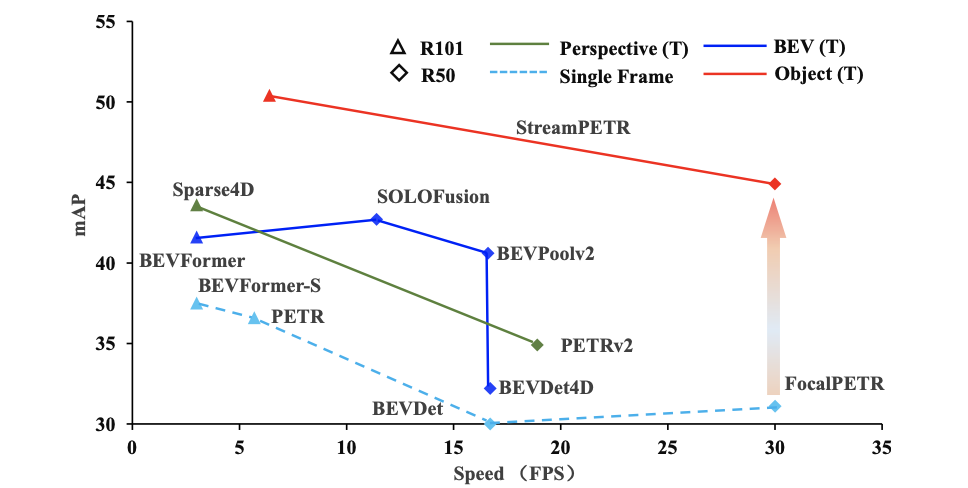
则将文章的方法与之前的一些方法进行比较,可以看到有很明显优势,而且实现更加简洁:
2. 方法实现
1. 整体流程:
文章算法的整体框图见下图所示:
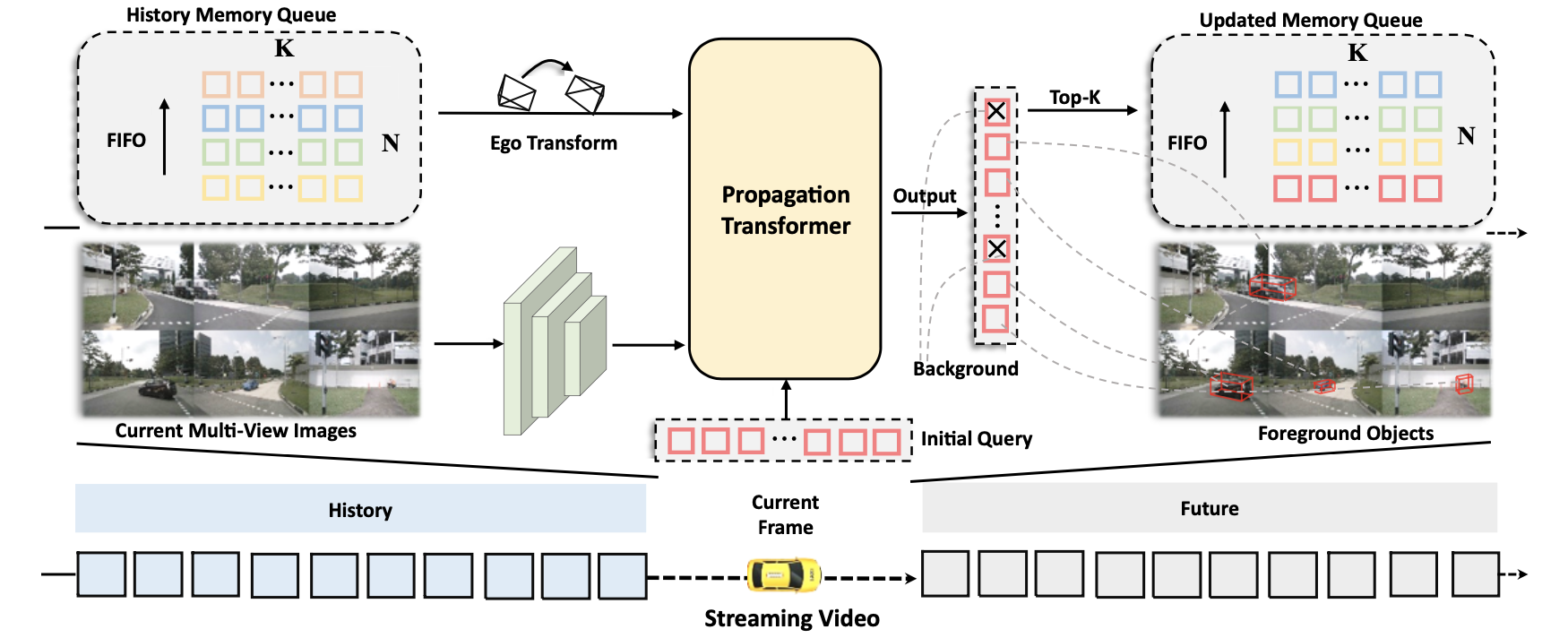
文中将多帧融合表示为目标的query在不同时刻补偿对齐之后融合的策略,这样可以极大减少网络计算量。大致过程如下:
- 1)如上图中之前帧的目标query会经过top-k选择之后送入维度为 N ∗ K N*K N∗K的FIFO对队列,其中 N N N为历史帧数, K K K为目标的数量。
- 2)同时还引入帧间时间间隔、帧间pose、目标速度作为补偿因子,这部分通过MLN实现,这样便可以得到从历史帧中对齐的query。
- 3)对齐之后的历史帧query和当前帧query一同输入到后续解码中得到感知结果,对于重复的目标是通过hybird attention layer实现的。
2. 特征抽取:
图像的特征会经过CNN backbone和FPN网络完成特征抽取,同时借鉴Focal-DETR在2D特征维度引入FCOS检测头,这样就可以从2D图像中去获取真正的前景信息,
# projects/mmdet3d_plugin/models/dense_heads/focal_head.py#L180
sample_weight = cls_score.detach().sigmoid() * centerness.detach().view(bs,-1,1).sigmoid()
_, topk_indexes = torch.topk(sample_weight, num_sample_tokens, dim=1)
正如上面代码,其是抽取的top-k的index作为后续BEV感知所需图像特征的输入。同时对2D层面也用了MLN实现不同帧的对齐。但是这里需要注意:需要分析2D检测部分出现问题之后对下游性能影响?只使用index确定的位置特征参与后续BEV感知,稳定性和不同任务适配能力如何?
3. 当前帧query的构建:
借鉴DN-DETR中使用GT添加noise方式构建query,之后做去噪任务。以此提升网络的收敛性和性能表现。
4. 输入历史帧query:
对于不同帧query的对齐,会将pose、time、velocity这些变量作为相对变化量使用MLN实现对齐,具体MLN的结构可以参见下图右图。
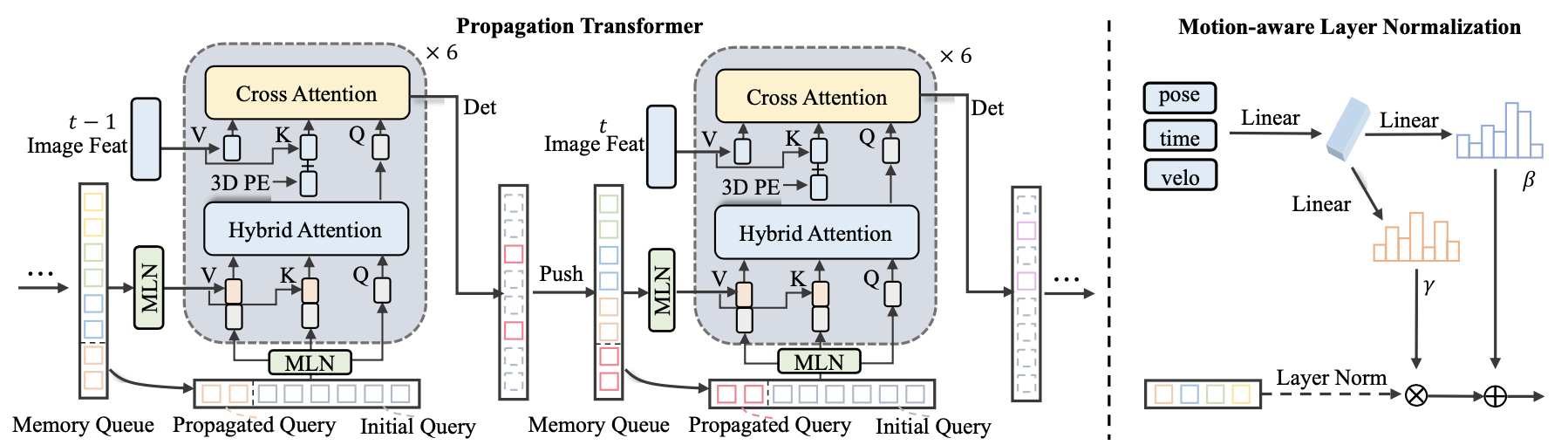
对齐之后的query会与当前帧的query送入到hybrid attention layer做query内部的self-attention操作,从而实现query去重的任务。对于这些query在hybird中如何输入的,可以参考上图中左图下半部分的细节,图已经呈现很明确了。
3. 实验结果
在nuScenes val数据集下的性能比较:

那么上面提到的pose、time、velocity对于对齐的效果影响,pose才是影响因子的大头: