title: Spark集群搭建
date: 2020-03-19 19:30:31
tags: Hadoop
基于Hadoop的Spark集群搭建
准备
Spark三种运行模式简介
Local模式
-
Local 模式是最简单的一种Spark运行方式,它采用单节点多线程(cpu)方式运行,local模式是一种OOTB(开箱即用)的方式,只需要在spark-env.sh导出JAVA_HOME,无需其他任何配置即可使用,因而常用于开发和学习
-
方式:./spark-shell - -master local[n] ,n代表线程数
Standalone模式
- Spark可以通过部署与Yarn的架构类似的框架来提供自己的集群模式,该集群模式的架构设计与HDFS和Yarn大相径庭,都是由一个主节点多个从节点组成,在Spark 的Standalone模式中,主,即为master;从,即为worker.
Spark on Yarn
- 简而言之,Spark on Yarn 模式就是将Spark应用程序跑在Yarn集群之上,通过Yarn资源调度将executor启动在container中,从而完成driver端分发给executor的各个任务。将Spark作业跑在Yarn上,首先需要启动Yarn集群,然后通过spark-shell或spark-submit的方式将作业提交到Yarn上运行。
实验环境
本文默认各位读者已经提前搭建好了Hadoop集群,配置好了Java、Hadoop环境变量
实验环境:Hadoop-2.7.7、jdk-8u231、Scala-2.13.1、Spark-2.4.5
安装Scala
Spark依赖scala,所以在安装Spark之前,这里要先安装scala。在每个节点上都进行安装。为方便操作,我们会使用XShell远程连接虚拟机进行实验
下载和解压
Scala官网:http://www.scala-lang.org/
点击Download后下来到other resources选择scala-2.13.1.tgz下载
下载完成后使用Xftp将压缩包传输到四台虚拟机的/root/download目录下
接下来我们使用XShell的‘发送键输入到所有会话’对四台虚拟机同时进行操作
切换到download目录下开始解包
cd /root/donwload
tar -zxvf scala-2.13.1.tgz -C /root/app
配置环境变量
vi /etc/profile
在profile配置文件最后添加如下内容
export SCALA_HOME=/root/app/scala-2.13.1
export PATH=$PATH:$SCALA_HOME/bin
保存退出后刷新一下配置文件
source /etc/profile
验证是否安装成功
输入以下命令以检查Scala是否安装成功
scala -version

安装Spark
下载和解压
Spark官网:http://spark.apache.org/downloads.html
选择相应配置,我们使用Hadoop2.7.7,所以选择如下文件下载

与上面Scala的下载一样,下载完成后我们使用Xftp将压缩包传输到四台虚拟机的/root/download目录下
切换到download目录下开始解包
cd /root/donwload
tar -zxvf spark-2.4.5-bin-hadoop2.7.tgz -C /root/app
解压完成后我们进入app目录改一下spark目录的名字
cd /root/app
mv spark-2.4.5-bin-hadoop2.7 spark
配置环境变量
vi /etc/profile
在profile配置文件末尾添加如下内容:
export SPARK_HOME=/root/app/spark
export PATH=$PATH:$SPARK_HOME/bin
export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JAVA_HOME/jre/lib
保存退出后,刷新一下配置文件
source /etc/profile
配置spark-env.sh
cd /root/app/spark/conf
cp spark-env.sh.template spark-env.sh 将该文件复制并重命名
vi spark-env.sh
在文件结尾添加如下内容
export SCALA_HOME=/root/app/jdk1.8.0_231
export JAVA_HOME=/root/app/jdk1.8.0_231
export HADOOP_HOME=/root/app/hadoop-2.7.7
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/root/app/spark
export SPARK_MASTER_IP=master
export SPARK_EXECUTOR_MEMORY=1G
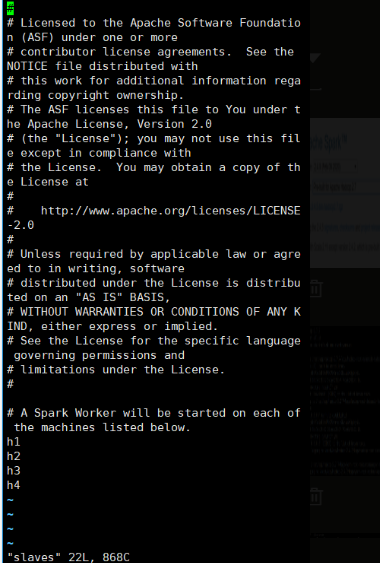
修改slaves文件
cp slaves.template slaves 将该文件复制并重命名
vi slaves
删除文件末尾的localhost,并修改为如下内容
h1
h2
h3
h4
启动Spark
注意,启动操作仅在主机(h1)上执行
cd /root/app/spark
sbin/start-all.sh
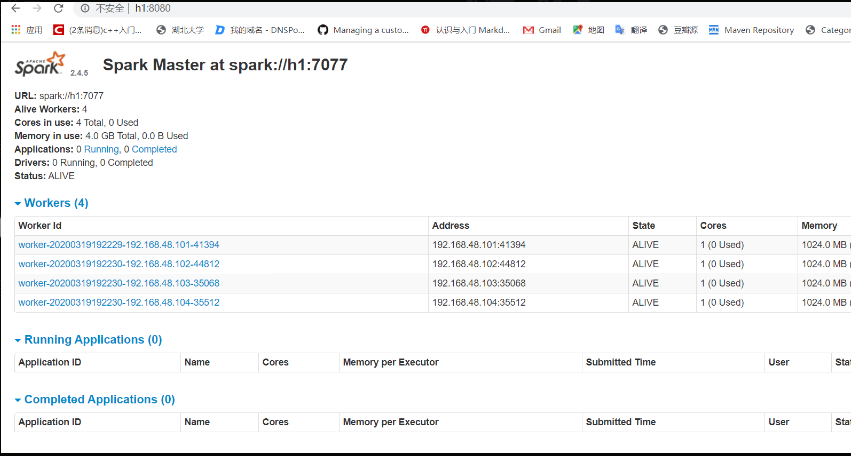
启动完成后使用jps命令即可看到Master与Worker两个进程
在浏览器输入"192.168.48.101:8080"可以登录到web端查看spark
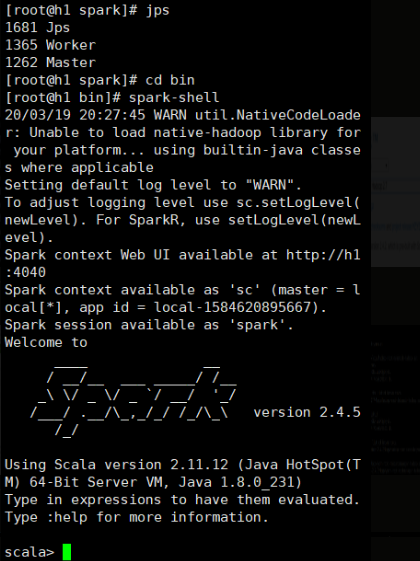
最后我们检查以下spark-shell能否正常使用
cd bin
spark-shell
按Ctrl+C可以退出spark-shell
至此,Spark on Yarn就安装完成啦