版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/qq_29726869/article/details/84105936
Docker 搭建Spark 依赖singularities/spark:2.2镜像
singularities/spark:2.2版本中
Hadoop版本:2.8.2
Spark版本: 2.2.1
Scala版本:2.11.8
Java版本:1.8.0_151
拉取镜像:
[root@localhost docker-spark-2.1.0]# docker pull singularities/spark
查看:
[root@localhost docker-spark-2.1.0]# docker image ls REPOSITORY TAG IMAGE ID CREATED SIZE docker.io/singularities/spark latest 84222b254621 6 months ago 1.39 GB
创建docker-compose.yml文件
[root@localhost home]# mkdir singularitiesCR [root@localhost home]# cd singularitiesCR [root@localhost singularitiesCR]# touch docker-compose.yml
内容:

version: "2"
services:
master:
image: singularities/spark
command: start-spark master
hostname: master
ports:
- "6066:6066"
- "7070:7070"
- "8080:8080"
- "50070:50070"
worker:
image: singularities/spark
command: start-spark worker master
environment:
SPARK_WORKER_CORES: 1
SPARK_WORKER_MEMORY: 2g
links:
- master
执行docker-compose up即可启动一个单工作节点的standlone模式下运行的spark集群
[root@localhost singularitiesCR]# docker-compose up -d Creating singularitiescr_master_1 ... done Creating singularitiescr_worker_1 ... done
查看容器:
[root@localhost singularitiesCR]# docker-compose ps
Name Command State Ports
--------------------------------------------------------------------------------------------------------------------------------------------------------
singularitiescr_master_1 start-spark master Up 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 50020/tcp,
0.0.0.0:50070->50070/tcp, 50075/tcp, 50090/tcp, 50470/tcp, 50475/tcp,
0.0.0.0:6066->6066/tcp, 0.0.0.0:7070->7070/tcp, 7077/tcp, 8020/tcp,
0.0.0.0:8080->8080/tcp, 8081/tcp, 9000/tcp
singularitiescr_worker_1 start-spark worker master Up 10020/tcp, 13562/tcp, 14000/tcp, 19888/tcp, 50010/tcp, 50020/tcp, 50070/tcp, 50075/tcp,
50090/tcp, 50470/tcp, 50475/tcp, 6066/tcp, 7077/tcp, 8020/tcp, 8080/tcp, 8081/tcp,
9000/tcp
查看结果:

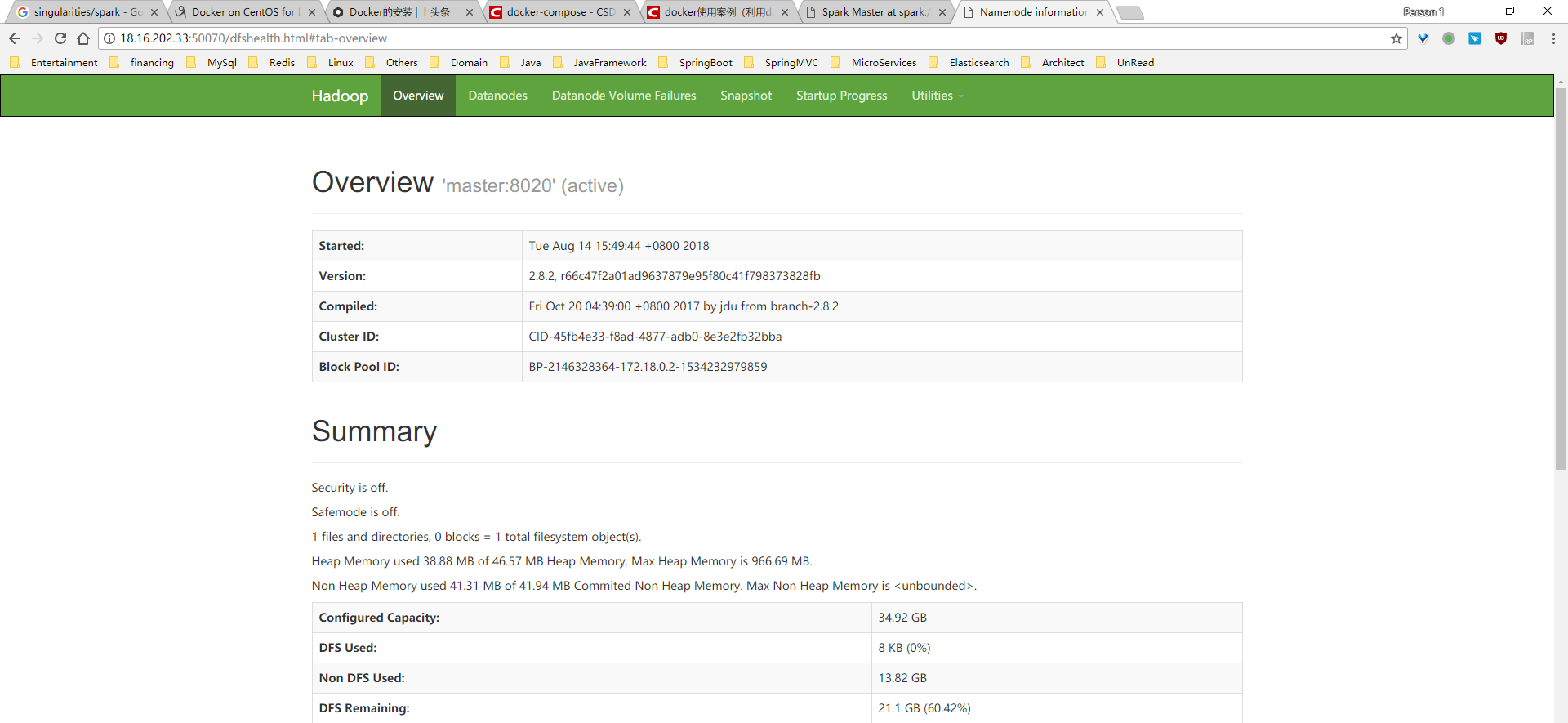
停止容器:
[root@localhost singularitiesCR]# docker-compose stop
Stopping singularitiescr_worker_1 ... done
Stopping singularitiescr_master_1 ... done
[root@localhost singularitiesCR]# docker-compose ps
Name Command State Ports
-----------------------------------------------------------------------
singularitiescr_master_1 start-spark master Exit 137
singularitiescr_worker_1 start-spark worker master Exit 137
删除容器:
[root@localhost singularitiesCR]# docker-compose rm Going to remove singularitiescr_worker_1, singularitiescr_master_1 Are you sure? [yN] y Removing singularitiescr_worker_1 ... done Removing singularitiescr_master_1 ... done [root@localhost singularitiesCR]# docker-compose ps Name Command State Ports ------------------------------
进入master容器查看版本:
[root@localhost singularitiesCR]# docker exec -it 497 /bin/bash
root@master:/# hadoop version
Hadoop 2.8.2
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 66c47f2a01ad9637879e95f80c41f798373828fb
Compiled by jdu on 2017-10-19T20:39Z
Compiled with protoc 2.5.0
From source with checksum dce55e5afe30c210816b39b631a53b1d
This command was run using /usr/local/hadoop-2.8.2/share/hadoop/common/hadoop-common-2.8.2.jar
root@master:/# which is hadoop
/usr/local/hadoop-2.8.2/bin/hadoop
root@master:/# spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/08/14 09:20:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Spark context Web UI available at http://172.18.0.2:4040
Spark context available as 'sc' (master = local[*], app id = local-1534238447256).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.2.1
/_/
Using Scala version 2.11.8 (OpenJDK 64-Bit Server VM, Java 1.8.0_151)
Type in expressions to have them evaluated.
Type :help for more information.
参考:
https://github.com/SingularitiesCR/spark-docker
https://blog.csdn.net/u013705066/article/details/80030732
使用docker-compose创建spark集群
下载docker镜像
sudo docker pull sequenceiq/spark:1.6.0创建docker-compose.yml文件
创建一个目录,比如就叫 docker-spark,然后在其下创建docker-compose.yml文件,内容如下:
version: '2'
services:
master:
image: sequenceiq/spark:1.6.0
hostname: master
ports:
- "4040:4040"
- "8042:8042"
- "7077:7077"
- "8088:8088"
- "8080:8080"
restart: always
command: bash /usr/local/spark/sbin/start-master.sh && ping localhost > /dev/null
worker:
image: sequenceiq/spark:1.6.0
depends_on:
- master
expose:
- "8081"
restart: always
command: bash /usr/local/spark/sbin/start-slave.sh spark://master:7077 && ping localhost >/dev/null
- 其中包括一个master服务和一个worker服务。
创建并启动spark集群
sudo docker-compose up集群启动后,我们可以查看一下集群状态
sudo docker-compose ps
Name Command State Ports
----------------------------------------------------------------------
dockerspark_master_1 /etc/bootstrap.sh bash /us ... Up ...
dockerspark_worker_1 /etc/bootstrap.sh bash /us ... Up ...- 默认我们创建的集群包括一个master节点和一个worker节点。我们可以通过下面的命令扩容或缩容集群。
sudo docker-compose scale worker=2扩容后再次查看集群状态,此时集群变成了一个master节点和两个worker节点。
sudo docker-compose ps
Name Command State Ports
------------------------------------------------------------------------
dockerspark_master_1 /etc/bootstrap.sh bash /us ... Up ...
dockerspark_worker_1 /etc/bootstrap.sh bash /us ... Up ...
dockerspark_worker_2 /etc/bootstrap.sh bash /us ... Up ...此时也可以通过浏览器访问 http://ip:8080 来查看spark集群的状态。
运行spark作业
首先登录到spark集群的master节点
sudo docker exec -it <container_name> /bin/bash然后使用spark-submit命令来提交作业
/usr/local/spark/bin/spark-submit --master spark://master:7077 --class org.apache.spark.examples.SparkPi /usr/local/spark/lib/spark-examples-1.6.0-hadoop2.6.0.jar 1000停止spark集群
sudo docker-compose down